关于KCP ARQ协议和kcptun请见:
kcptun作者对此的解决方法是使用
为了解决断流问题,各位网友各出奇招,比如 issue #228 提到的端口随机化、上下行分不同端口等,都能一定程度缓解该问题,然而这仍然都是治标不治本的方法。
你可能理所当然的认为,“下层协议用TCP不就好了”(即kcp over tcp)。是的,ISP对TCP做的QoS要“宽容”很多(完全断流且不能恢复的几率不大),如果将kcptun的下层协议换成TCP,应该可以解决我们的问题?
答案是NO。UDP和TCP的一个重要区别是,UDP是不可靠的、基于message的实时性协议,而TCP是可靠的、基于stream的非实时性协议。而KCP作为可靠的ARQ算法,所依赖的下层协议必须保证实时性,而可靠性并不需要保证。如果我们直接将下层协议换成TCP,则流量会先经过操作系统内核进行拥塞控制和纠错处理,再递交kcp层,这样一来kcp的优化拥塞控制算法就完全没有发挥作用。
受这个项目的启发,我想使用同样的原理重新实现一个简单的kcptun:下层协议更换为带TCP头的packet(通过raw socket或libpcap等实现),使ISP认为这是TCP流量。但这并不是严格的“kcp over tcp”,因为我们完全绕过系统内核的TCP/IP内核栈对流量的管控而直接交由kcp进行拥塞控制和纠错。这样一来,我们我们能够保证下层报文递交到kcp算法时的实时性。
换言之,我们需要 在用户态模拟从IP到TCP的协议栈。
在造轮子之前,需要验证这些带了伪TCP header的IP header是否能够在网络上正常收发。于是编写了这么的一个实验程序:
https://gist.github.com/Chion82/699ae432a27507242ea788df324f4e47
该程序修改自网上的一段SYN flood程序。
通过修改IP信息,编译出
这个程序使用raw socket实现packet收发,由程序直接拼装TCP和IP报头:在
在接收packet时,由于使用了
这个实验程序说明了伪装TCP流量实现双向通信是可行的。因为要使用raw socket来重写kcptun,我们就称这个项目为“kcptun-raw”吧。
因此,我们需要使这些IP报文绕过内核的TCP/IP协议栈,以此来避免内核对我们模拟的TCP连接的干涉。这可以通过Linux的
假设服务端IP为
对应的客户端命令是:
在使用了
linhua55同学在 Issue #2 中提到Windows下绕过内核协议栈的方法,即通过
具体测试结果如下(Issue #2):
这样,一次上层TCP连接从建立到断开的分层流程大致如下:
客户端:
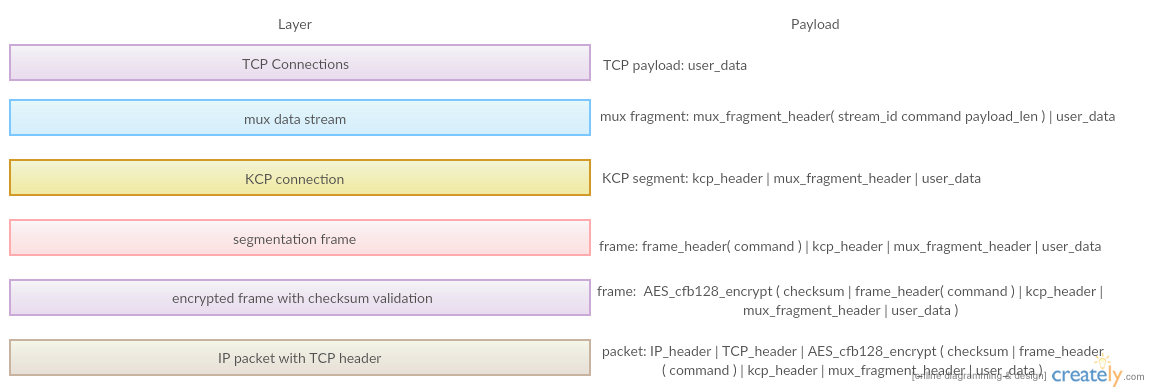
其次,考虑到加密封包和checksum验证,最终设计的数据流分层以及对应的payload定义如下:
为了避免这个问题,我们需要双向流控来实现双边连接的同步:当对方
kcptun-raw的开发前后遇到了不少困难,不过最终还是做出来了。经过我的测试,效果还是不错的,单线程下载速度最高在15~20 Mbytes/s,最大并发连接数程序写死了8192(当然一般是到不了这么大的)。
https://github.com/Chion82/kcptun-raw
https://github.com/skywind3000/kcp
https://github.com/xtaci/kcptun
UDP断流问题
我们知道kcptun的底层协议是UDP,而很多ISP对大流量UDP会做QoS,这包括了大量issue反映的“断流”问题:在正常运行一段时间之后流量会中断,需要等待数分钟才能恢复,有时候除非更换端口,将一直保持0速度。kcptun作者对此的解决方法是使用
--autoexpire参数设置UDP连接超时并自动重连(补充:UDP虽无连接状态,但仍有会话保持机制),但此举治标不治本,对于QoS频繁的网络环境需要频繁更改UDP端口,而该过程可能会导致kcptun的上层连接(本地TCP连接)中断。为了解决断流问题,各位网友各出奇招,比如 issue #228 提到的端口随机化、上下行分不同端口等,都能一定程度缓解该问题,然而这仍然都是治标不治本的方法。
你可能理所当然的认为,“下层协议用TCP不就好了”(即kcp over tcp)。是的,ISP对TCP做的QoS要“宽容”很多(完全断流且不能恢复的几率不大),如果将kcptun的下层协议换成TCP,应该可以解决我们的问题?
答案是NO。UDP和TCP的一个重要区别是,UDP是不可靠的、基于message的实时性协议,而TCP是可靠的、基于stream的非实时性协议。而KCP作为可靠的ARQ算法,所依赖的下层协议必须保证实时性,而可靠性并不需要保证。如果我们直接将下层协议换成TCP,则流量会先经过操作系统内核进行拥塞控制和纠错处理,再递交kcp层,这样一来kcp的优化拥塞控制算法就完全没有发挥作用。
伪装TCP流量的可行性
要解决UDP断流问题,不更换下层协议是很难做到的。于是我想到,能不能直接使用网络层的IP packet作为kcp的下层协议。因为边缘路由器一般是在OSI网络层进行转发,所以在公网环境下是可行的。然而我们的客户端都是在ISP内网环境,这将不现实:因为NAT需要跟踪运输层头部数据,如双方的端口信息。后来我发现了 linhua55 同学的 some_kcptun_tools/relayRawSocket 项目,这位同学写了个简单的python脚本实现了“fake TCP to UDP”的中继,通过raw socket来实现带静态TCP头部的IP packet收发,并转发到上层UDP。经测试,这个脚本能一定程度上解决断流问题,但存在带宽利用率不高、不稳定的问题。受这个项目的启发,我想使用同样的原理重新实现一个简单的kcptun:下层协议更换为带TCP头的packet(通过raw socket或libpcap等实现),使ISP认为这是TCP流量。但这并不是严格的“kcp over tcp”,因为我们完全绕过系统内核的TCP/IP内核栈对流量的管控而直接交由kcp进行拥塞控制和纠错。这样一来,我们我们能够保证下层报文递交到kcp算法时的实时性。
换言之,我们需要 在用户态模拟从IP到TCP的协议栈。
在造轮子之前,需要验证这些带了伪TCP header的IP header是否能够在网络上正常收发。于是编写了这么的一个实验程序:
https://gist.github.com/Chion82/699ae432a27507242ea788df324f4e47
该程序修改自网上的一段SYN flood程序。
通过修改IP信息,编译出
client和server两个bin,即可测试本地到服务端的双向连通性。若测试成功,双方都能收到对方的一条text消息。这个程序使用raw socket实现packet收发,由程序直接拼装TCP和IP报头:在
trans_packet.c 中,借助 struct iphdr 和 struct tcphdr 两个结构来拼接,TCP头是静态的,置flag SYN=1。在接收packet时,由于使用了
ETH_P_ALL 过滤器(为什么不使用 IPPROTO_TCP 后面会提到),经过全部网卡的所有packet都会被捕捉,因此要通过判断IP头协议以及TCP头目标端口进行过滤。这个实验程序说明了伪装TCP流量实现双向通信是可行的。因为要使用raw socket来重写kcptun,我们就称这个项目为“kcptun-raw”吧。
绕过内核TCP/IP协议栈
由于我们在用户态直接使用raw socket发送IP报文,双方的内核都对这个我们手动模拟的TCP连接不知情,因此当内核收到对方发送的IP报文时,内核根据报文中的TCP头信息(这些信息是我们手动拼接的)试图寻找TCP连接跟踪信息并且寻找失败,随即认为该报文是无效的,内核接着会试图“终止”我们模拟的TCP连接,并向对方发送一个RST包。该RST包会导致中间路由器认为连接已被重置,撤销打通的NAT pipe,使得接下来发送的报文都不能到达对方。因此,我们需要使这些IP报文绕过内核的TCP/IP协议栈,以此来避免内核对我们模拟的TCP连接的干涉。这可以通过Linux的
iptables的DROP命令实现。假设服务端IP为
108.0.0.1,模拟TCP连接的端口为888,在服务端的iptables命令是:
|
|
|
|
DROP操作后,如果raw socket继续使用 IPPROTO_TCP 过滤器,将无法接收到该端口上的任何报文。因此,我们将使用 ETH_P_ALL,接收流经网卡的全部IP报文。
|
|
ipseccmd.exe 或 netsh 命令。动态TCP header和模拟三次握手
作者在几个ISP网络环境下进行了测试,发现部分环境下静态TCP报头无法传送到服务端,或是服务端返回的packet客户端收不到,这种情况下需要模拟TCP三次握手过程。另外,将TCP报头的seq/ack参数改为动态自增可以增强稳定性,而有的环境下则必须保持定值。具体测试结果如下(Issue #2):
- 广东移动:
- 服务端ack flag必须置为1,否则客户端将一直收不到服务端的packet。
- seq/ack序列需要一直保持定值,如果一直自增会被QoS随后pipe被掐断;
- 广电宽带(广东)和电信4G:
- 必须模拟TCP三次握手过程,即 客户端SYN->服务端SYN+ACK->客户端ACK ,随后pipe才能打通。
- seq/ack序列无要求,保持定值和一直自增都可以。
- 服务器提供商(阿里云等):
- vps之间通信基本无限制,在防火墙关闭的情况下,packet想怎么发都可以(因为没有经过NAT和ISP的QoS的缘故?)
报文分层设计和流控
在确认了下层协议的实现可行性之后,作者即开始动手开发kcptun-raw。第一次报文分层
作为隧道,最上层协议当然是TCP,而KCP的下层协议是packet。一开始理所当然的想法是,一个上层的TCP连接对应一个KCP连接,而全部KCP连接共用同一个伪造的TCP连接并在其上传输带伪造TCP头的packet作为最下层传输协议。而最下层的packet封包除了传输多个kcp连接的片段数据(KCP segment),还用于传送命令,这些命令包括建立连接、关闭连接和保活命令等。这样,一次上层TCP连接从建立到断开的分层流程大致如下:
客户端:
服务端:
→ → → → → TCP ↓ 新连接 ↓ 接收数据 ↑ 发送数据 ↓ 断开连接 KCP ↓ 新连接 ↓ 发送KCP片段 ↑ 接收KCP片段 ↓ 杀死 packet ↓ 推送新连接 ↓ 推送数据段 ↑ 接收数据段 ↓ 推送关闭连接
这看起来没有什么问题。然而这忽略了一个很重要的东西:命令封包丢失。如果丢失的是KCP的数据段封包,这没有什么问题——KCP会自动处理好重发、拥塞和纠错策略,以保证上交到TCP层的数据是正确完整的;但是如果丢失的是建立连接或断开连接的命令封包,问题就很严重了,这会导致客户端的新TCP连接迟迟无法响应、或是其中一方的TCP连接变成“僵尸连接”(其中一方已关闭连接,而主动关闭命令未送达)。这正是为什么TCP需要三次握手和四次挥手的原因:为了处理在边界情况下的各种丢包情况。
→ → → → → TCP ↑ 新连接 ↑ 发送数据 ↓ 接收数据 ↑ 断开连接 KCP ↑ 新连接 ↑ 接收KCP片段 ↓ 发送KCP片段 ↑ 杀死 packet ↑ 对方推送新连接 ↑ 接收数据段 ↓ 发送数据段 ↑ 对方推送关闭连接
MUX层、共享KCP连接
要解决这个问题,我们需要重新设计一次报文分层。因为KCP层以上的数据都是可靠的,因此我们可以共享kcp连接,并在此之上传送命令封包和数据封包。要实现这样的设计,我们要在TCP层之下引入MUX层。MUX即Stream Multiplexing,这样我们可以在唯一的KCP流上进行多路复用。为此我们重新设计在KCP流上传输的封包类型:标识了TCP流ID的数据帧、新连接命令、断开连接命令、保活命令。其次,考虑到加密封包和checksum验证,最终设计的数据流分层以及对应的payload定义如下:
流控
为什么需要流控?考虑这样的一个情景:服务端的TCP连接在1s内接收了100MB的数据(如果是跑在服务器本机的服务,这个速度很正常),并一下子全部经由KCP传送给客户端,而受服务端到客户端的带宽所限,这100MB数据需要2min才能传输完成,此时服务端的KCP发送队列十分拥塞,如果这时服务端上有另一个TCP连接接收到了数据,这部分数据帧将追加到KCP发送队列的队尾,并迟迟发不出去,直至100MB的数据传输完毕。这样的直接表现是,正在全速下载大文件时,发出的新连接请求要等到文件下载完毕后才得到响应,并发性能极差。为了避免这个问题,我们需要双向流控来实现双边连接的同步:当对方
kcp_recv()速度远慢于己方tcp_recv()速度,导致己方KCP发送队列长时,及时暂停己方的tcp_recv();当己方的TCP发送队列长(表现为非阻塞socket下、send() 后得到 EAGAIN ),暂停己方的kcp_recv(),以增加对方的KCP发送队列长度。最终实现
在确定了各项设计后,我们可以开始着手开发kcptun-raw了。程序使用非阻塞socket,借助 libev 库实现高性能的事件并发模型,避免使用多线程/进程。kcptun-raw的开发前后遇到了不少困难,不过最终还是做出来了。经过我的测试,效果还是不错的,单线程下载速度最高在15~20 Mbytes/s,最大并发连接数程序写死了8192(当然一般是到不了这么大的)。
稳定性和保活
为了保证程序长期运行的稳定性,以应对各种不可避免的网络断流问题,我写了两层保活机制:- 模拟TCP层保活:packet层的心跳检测,超时则更换客户端端口、重新建立模拟TCP连接。
- KCP层保活:在KCP流上的心跳检测,timeout时限比TCP层更长,一旦超时,将立即关闭所有上层TCP连接,重新初始化KCP流,并通知对方重新初始化KCP流。
一般情况下,模拟TCP层的保活可以解决绝大多数断流问题——这正是两层保活的优点:下层的自动重连不会影响到KCP流和TCP连接,而当迫不得已需要重启KCP流时,必须中断全部上层TCP连接,以保证双方数据帧的同步。
几个问题?
- kcptun-raw还有待改进的地方?
目前kcptun-raw的设计是简化的kcptun,特别是取消了FEC,现在发现取消了FEC后会存在延迟抖动、带宽利用率比不上原版kcptun的问题。日后如果发现有需要,会考虑引入FEC。
- 4.9内核后引入了BBR拥塞算法,为何还需要kcptun?或者说BBR能否为KCP提供一点改进思路?
首先,BBR和KCP是工作在两个不同层面的东西:BBR在内核态直接作为TCP/IP协议栈的模块,接管所有TCP连接的拥塞控制,其原理是抛弃老旧的基于丢包检测的窗口控制算法,改为主动探测水管大小,避免网络设备的缓冲区满;KCP则是通过牺牲一部分公平性原则、以大流量换取小延迟的算法,基本原理是激进重传,会消耗20%~30%额外的带宽。经过我的测试,大多时候BBR虽然传输速度比kcptun更快,但是BBR未能解决被QoS的问题:一个TCP连接一旦断流,速度将一直不能恢复,需要重新建立TCP连接方可恢复。这是当然的,因为BBR只是作为接管内核原来的TCP拥塞算法,它是针对per TCP connection而工作的,并没有改变协议栈的分层约定。而kcptun-raw作为上层TCP到下层自定义协议的隧道工具,TCP层以下的协议规则约定是可以自定义的,当下层连接断流了,该层可以自动重连,而这不会导致上层TCP连接的断开,这是解决QoS的关键所在。
- 另外,快乐膜法师同学基于原版kcptun,也写了一个基于raw socket和伪造TCP的改版,同时支持Linux、MacOS和Windows,并且还有伪装HTTP流量的功能,需要给运营商薅羊毛的同学可以参考:
https://github.com/ccsexyz/kcpraw
https://github.com/Chion82/kcptun-raw
No comments:
Post a Comment