Linux 透明代理
什么是正向代理?
什么是透明代理?
透明代理如何工作?
- REDIRECT:只支持 TCP 协议的透明代理。
- TPROXY:支持 TCP 和 UDP 协议的透明代理。
此脚本的作用及由来
为什么叫做ss-tproxy?因为该脚本最早的时候只支持 ss 的透明代理,当然现在它并不局限于特定的代理软件。
dokodemo-door 入站协议即可。再次强调,透明代理只是 client 不同,并不关心你的 server 是什么版本,因此你的 vps 上,可以运行所有与之兼容的 server 版本,以 ss/ssr 为例,你可以使用 python 版的 ss、ssr,也可以使用 golang 版的 ss、ssr 等等,只要它们之间可以兼容。- 去除不常用的
global分流模式 - 支持 IPv4、IPv6 双协议栈的透明代理(可配置)
- 使用 chinadns-ng 替代原版 chinadns,修复若干问题
- 完美兼容"端口映射",只代理"主动出站"的流量,规则更加细致化
- 支持配置要代理的黑名单端口,这样可以比较好的处理 BT/PT 流量
- 支持自定义 dnsmasq/chinadns 端口,支持加载外部 dnsmasq 配置
- ss-tproxy stop 后,支持重定向内网主机发出的 DNS 到本地直连 DNS
- 支持网络可用性检查,无需利用其它的 hook 来避免脚本自启失败问题
- 脚本逻辑优化及结构调整,尽量提高脚本的可移植性,去除非核心依赖
gfwlist、chnroute、chnlist 3 种分流模式,相关介绍:gfwlist分流模式:gfwlist.txt中的域名走代理,其余走直连,即黑名单模式。chnroute分流模式:除了国内地址、保留地址之外,其余均走代理,即白名单模式。chnlist分流模式:本质还是gfwlist模式,只是域名列表为国内域名,即回国模式。
有人可能会有疑问,为什么使用 ss-tproxy 后,虽然可以访问谷歌,但依旧无法 ping 谷歌,这是为什么呢?这是因为 ping 走的是 ICMP 协议,没有哪个代理软件会去支持 ICMP 的代理,因为 ICMP 的代理并没有任何实际意义。
相关依赖
iptables:核心部件,用于配置 IPv4 的透明代理规则。ip6tables:核心部件,用于配置 IPv6 的透明代理规则。xt_TPROXY:TPROXY 内核模块,这是必须的,无论什么模式。ip:通常位于 iproute2 软件包,用于配置策略路由(TPROXY)。ipset:ipset 用于存储 gfwlist 的黑名单 IP,以及 chnroute 的白名单 IP。dnsmasq:基础 DNS 服务,对于 gfwlist 模式,该 dnsmasq 需要支持--ipset选项。chinadns-ng:chnroute 模式的 DNS 服务,注意是 chinadns-ng,而不是原版 chinadns。
如果某些模式你基本不用,那么对应的依赖就不用管。比如,你不打算使用 IPv6 透明代理,则无需关心 ip6tables,又比如你不打算使用 chnroute 模式,也无需关心 chinadns-ng,安装依赖之前先检查当前系统是否已有对应依赖。
curl:用于更新 chnlist、gfwlist、chnroute 分流模式的相关列表。base64:用于更新 gfwlist 的域名列表,gfwlist.txt 是base64格式编码的。perl:用于更新 gfwlist 的域名列表,gfwlist.txt 是adblock plus规则,要进行转换。
安装脚本
git clone https://github.com/zfl9/ss-tproxy
cd ss-tproxy
chmod +x ss-tproxy
cp -af ss-tproxy /usr/local/bin
mkdir -p /etc/ss-tproxy
cp -af ss-tproxy.conf gfwlist* chnroute* /etc/ss-tproxy
cp -af ss-tproxy.service /etc/systemd/system # 可选,安装 service 文件
卸载脚本
ss-tproxy stop
ss-tproxy flush-postrule
ss-tproxy delete-gfwlist
rm -fr /usr/local/bin/ss-tproxy /etc/ss-tproxy # 删除脚本及配置文件
升级脚本前请先卸载脚本,如果有残留规则无法清除,请务必重启系统。
文件列表
ss-tproxy:shell 脚本,欢迎各位大佬一起来改进此脚本。ss-tproxy.conf:配置文件,本质是 shell 脚本,修改需重启生效。ss-tproxy.service:systemd 服务文件,用于 ss-tproxy 的开机自启。chnroute.set:IPv4 国内地址及保留地址的 ipset 文件,不要手动修改。chnroute6.set:IPv6 国内地址及保留地址的 ipset 文件,不要手动修改。gfwlist.txt:存储 gfwlist、chnlist 分流模式的黑名单域名,不要手动修改。gfwlist.ext:存储 gfwlist、chnlist 分流模式的扩展黑名单,可配置,重启生效。
ss-tproxy 只是一个 shell 脚本,并不是常驻后台的服务,因此所有的修改都需要 restart 来生效。
配置说明
- 注释:井号开头的行为注释行,配置文件本质上是一个 shell 脚本,对于同名变量或函数,后定义的会覆盖先定义的。
mode:分流模式,默认为 chnroute 模式,可根据需要修改为 gfwlist 模式;需要说明的是,如果想使用chnlist回国模式,那么 mode 依旧为gfwlist,gfwlist 模式与 chnlist 模式共享gfwlist.txt、gfwlist.ext文件,因此使用 chnlist 模式前,需要先执行ss-tproxy update-chnlist将 gfwlist.txt 替换为国内域名,同时手动编辑 gfwlist.ext 扩展黑名单,将其中的 Telegram IPv4/IPv6 地址段注释,此外你还需要修改dns_direct/dns_direct6为本地直连 DNS(如 Google 公共 DNS),然后修改dns_remote/dns_remote6为大陆 DNS(如 114 公共 DNS,走国内代理)。ipv4/ipv6:启用 IPv4/IPv6 透明代理,你需要确保本机代理进程能正确处理 IPv4/IPv6 相关数据包,脚本不检查它。tproxy:true 为纯 TPROXY,false 为 REDIRECT/TPROXY 混合,ss/ssr 只能使用 false,v2ray 经配置后可使用 true。proxy_svraddr4/proxy_svraddr6:填写 VPS 服务器的外网 IPv4/IPv6 地址,IP 或域名都可以,填域名要注意,这个域名最好不要有多个 IP 地址与之对应,因为脚本内部只会获取其中某个 IP,这极有可能与本机代理进程解析出来的 IP 不一致,这可能会导致 iptables 规则死循环,应尽量避免这种情况,比如你可以将该域名与其中某个 IP 的映射关系写到 ss-tproxy 主机的/etc/hosts文件中,这样解析结果就是可预期的。允许填写多个 VPS 地址,用空格隔开,填写多个地址的目的是方便切换代理,比如我现在有两个 VPS,A、B,假设你先使用 A,因为某些因素,导致 A 的网络性能低下,那么你可能需要切换到 B,如果只填写了 A 的地址,就需要去修改 ss-tproxy.conf,将地址改为 B,修改启动与关闭命令,最后还得重启 ss-tproxy 脚本,很麻烦,更麻烦的是,如果现在 A 的网络又好了,那么你可能又想切换回 A,那么你又得重复上述步骤。但现在,你不需要这么做,你完全可以在proxy_svraddr中填写 A 和 B 的地址,假设你默认使用 A(proxy_startcmd启动 A 代理进程),那么启动 ss-tproxy 后,使用的就是 A,此后如果想切换为 B,仅需停止 A 代理进程,再启动 B 代理进程(切回来的步骤则相反),该过程无需操作 ss-tproxy;这种配置下应注意proxy_stopcmd,stopcmd 最好能停止 A 和 B 进程,不然切换进程后执行 ss-tproxy stop 可能不会正确停止相关的代理进程。另外,你只需填写实际会使用到的 VPS 地址,比如本机代理进程仅使用 IPv4 访问 VPS,则proxy_svraddr6可能是空的,反之,如果本机代理进程仅使用 IPv6 访问 VPS,则proxy_svraddr4可能是空的;这两个数组是否为空与ipv4、ipv6选项没有必然的联系,比如你可以启用 IPv4 和 IPv6 透明代理,但是本机代理进程仅使用 IPv4 访问 VPS,这是完全可以的,但不允许proxy_svraddr4与proxy_svraddr6都为空,你至少需要填写一个地址。proxy_svrport:填写 VPS 上代理服务器的外部监听端口,格式同ipts_proxy_dst_port,填写不正确会导致 iptables 规则死循环。如果是 v2ray 动态端口,如端口号 1000 到 2000 都是代理监听端口,则填1000:2000(含边界)。proxy_tcpport/proxy_udpport:本机代理进程的透明代理监听端口,前者为 TCP 端口,后者为 UDP 端口,通常情况下它们是相同的,根据实际情况修改。需要注意的是,ss-tproxy v3.0 之后都要求代理软件支持 UDP,否则 DNS 是无法正常解析的,请务必检查 UDP 代理的连通情况,对于 ss/ssr,它们的 UDP 代理数据是通过 UDP 协议进行传递的,某些 ISP 可能会对 UDP 恶意丢包,v2ray 某些协议则为 UDP over TCP,对于这种情况则无需担心 UDP 丢包问题。proxy_startcmd/proxy_stopcmd:前者是启动本机代理进程的 shell 命令,后者是关闭本机代理进程的 shell 命令。这些命令应该能快速执行完毕,否则会导致透明代理长期处于半启动或半关闭状态。具体的 startcmd、stopcmd 示例见后。dnsmasq_bind_port:dnsmasq 监听端口,默认 53,如果端口已被占用则修改为其它未占用的端口,如60053。dnsmasq_conf_dir/dnsmasq_conf_file:dnsmasq 外部配置文件/目录,被作为conf-dir、conf-file选项值。ipts_set_snat:是否设置 IPv4 的 MASQUERADE 规则,通常保持为 false 即可。有两种情况需要将其设置为 true:第一种,ss-tproxy 部署在出口路由位置且确实需要 MASQUERADE 规则(即该主机至少两张网卡,一张连接内网,一张连接公网,要进行源地址转换);第二种,在设置为 false 的情况下,代理不正常,那么也需要将其改为 true,曾经遇到过这种情况,可能与路由器的配置有关。注意,MASQUERADE 规则在 ss-tproxy stop 仍然是有效的,如果你想清空这些残留规则,可以执行ss-tproxy flush-postrule命令。ipts_set_snat6:是否设置 IPv6 的 MASQUERADE 规则,默认为 true,通常你必须将其设置为 true,因为 IPv6 的透明代理需要利用 ULA 内网地址,如果设置为 false,那么其它内网主机将无法访问 IPv6 网络,因为 ULA 地址是不可以在公网上被路由的,因此你必须进行 SNAT 源地址转换。除非你使用 GUA 地址进行透明代理,但这样会让配置变得复杂且不易使用,因为 GUA 地址是动态变化的,运营商不会给你分配一个固定的 GUA 地址段。ss-tproxy stop 之后,这些规则仍然有效,如果你想清空这些残留规则,可以执行ss-tproxy flush-postrule命令。ipts_intranet/ipts_intranet6:填写需要代理的内网网段,可以填写多个,空格隔开,当然也可以一个都不填,这表示只代理 ss-tproxy 主机自身的流量。对于 IPv6 透明代理,此选项有非常多值得讨论的地方,具体请看后文。ipts_reddns_onstop:当 ss-tproxy stop 之后,是否使用 iptables 规则将内网主机发往 ss-tproxy 主机的 DNS 请求重定向至本地直连 DNS(即dns_direct/dns_direct6),为什么要这么做呢?因为其它内网主机的 DNS 是指向 ss-tproxy 主机的,但是现在我们已经关闭了 ss-tproxy(dnsmasq 进程关闭了),所以这些内网主机会因为无法解析 DNS 而无法正常上网,而设置此选项后,这些 DNS 请求会被重定向给 114.114.114.114 等国内直连 DNS,这样它们就又可以正常上网了,在 ss-tproxy start 前,这些规则会自动删除,如果你需要手动删除这些规则,可以执行ss-tproxy flush-postrule命令。该选项的默认值为 true,如果 ss-tproxy 主机上有正常运行的 DNS 服务,那么这个选项应该设置为 false。ipts_proxy_dst_port:告诉 ss-tproxy,黑名单地址的哪些目的端口需要走代理。所谓黑名单地址,对于 gfwlist/chnlist 模式来说,就是 gfwlist.txt/gfwlist.ext 里面的域名、IP、网段,对于 chnroute 模式来说,就是 chnroute/chnroute6 之外的地址(即国外地址),当然黑名单地址还包括proxy_svraddr4/proxy_svraddr6中所指定的 VPS 地址。该选项的默认值为1:65535,因此只要我们访问黑名单地址,就会走代理,因为所有端口号都在其中。如果觉得端口范围太大,那么你可以修改这个选项的值,比如设置为1:1023,8080,在这种配置下,只有当我们访问黑名单地址的 1 到 1023 和 8080 这些目的端口时才会走代理,访问黑名单地址的其它目的端口是不会走代理的,因此可以利用此选项来放行 BT、PT 流量,因为这些流量的目的端口通常都在 1024 以上。修改此选项需要足够小心,配置不当会导致某些常用软件无法正常走代理,因为它们使用的端口号可能不在你所指定的范围之内,因此指定为1:65535可能是最保险的一种做法。opts_ss_netstat:告诉 ss-tproxy,使用 ss 还是 netstat 命令进行端口检测,目前检测本机代理进程是否正常运行的方式是直接检测其是否已监听对应的端口,虽然这种方式有时候并不准确,但是我现在貌似并没有其它更好的便携方法来做这个事情。选项的默认值为auto,表示自动模式,所谓自动模式就是,如果当前系统有 ss 命令则使用 ss 命令进行检测,如果没有 ss 命令但是有 netstat 命令则使用 netstat 命令进行检测,而ss选项值则是明确告诉 ss-tproxy 使用ss进行检测,同理,netstat选项也是明确告诉 ss-tproxy 使用netstat进行端口检测。通常情况下保持auto即可。opts_overwrite_resolv:如果设置为 true,则表示直接使用 I/O 重定向方式修改/etc/resolv.conf文件,这个操作是不可逆的,但是可移植性好;如果设置为 false,则表示使用mount -o bind魔法来暂时性修改/etc/resolv.conf文件,当 ss-tproxy stop 之后,/etc/resolv.conf会恢复为原来的文件,也就是说这个修改操作是可逆的,但是这个方式可能某些系统会不支持,默认为false,如果遇到问题请修改为true。opts_ip_for_check_net:指定一个允许 Ping 的 IP 地址(IPv4 或 IPv6 都行),用于检查外部网络的连通情况,默认为114.114.114.114,注意这个 IP 地址应该为公网 IP,如果你填一个私有 IP,即使检测成功,也不能保证外网是可访问的,因为这仅代表我可以访问这个内网。根据实际网络环境进行更改,一般改为延迟较低且较稳定的一个 IP。
ipts_intranet6 选项中的 IP 段,如果你在这里填写 GUA 地址段,那么当 GUA 地址变更后,你需要及时的修改 ipts_intranet6 为最新的 GUA 地址段,否则 ss-tproxy 就将无法拿到其它设备发出的流量。显然,这样的体验非常糟糕。ipts_intranet6 中填写此 ULA 网段,同时启用 ipts_set_snat6 选项,做源地址转换,因为 ULA 地址需要转换为 GUA 地址才能被路由。这其实和我们现在的 IPv4 NAT 网络差不多,不同的是,这些设备具有一个 IPv6 公网地址,因此我们仍然可以从外部 IPv6 网络访问这些具有 GUA 地址的设备。- 禁用除 ss-tproxy 主机外的其它主机的 GUA 地址,这样它们始终会使用 ULA 地址作为源 IP,但这会让 IPv6 变得毫无优势,因为这种配置下,完全等于我们之前的 IPv4 NAT 网络,没有任何本质区别。
- 配置除 ss-tproxy 主机外的其它主机的路由条目,强制使用 ULA 地址作为源 IP,而不是 GUA 地址,比如可以使用
ip route的src选项,但是对于其它操作系统,尚不清楚如何干预源地址的选择。 - 另外还有一种方式,即在要走代理的设备上都分别部署 ss-tproxy 脚本,这样我们甚至不需要关心什么 GUA、ULA,因为我们只代理本机的流量,无需关心其它主机过来的流量,但这实际上并不太现实。
proxy_startcmd、proxy_stopcmd{
"server": "服务器地址",
"server_port": 服务器端口,
"local_address": "本地监听地址",
"local_port": 本地监听端口,
"method": "加密方式",
"password": "用户密码",
"no_delay": true,
"fast_open": true,
"reuse_port": true
}
127.0.0.1、::1,否则必须为 0.0.0.0、::。然后 proxy_startcmd、proxy_stopcmd 可以这么写:#proxy_startcmd='(ss-redir -c /etc/ss.json -u -v
proxy_startcmd、proxy_stopcmd 例子:#proxy_startcmd='(ssr-redir -c /etc/ssr.json -u -v
dokodemo-door 入站协议即可。由于 v2ray 配置复杂,在报告透明代理有问题之前,请务必检查你的配置是否有问题,这里不想解答任何 v2ray 配置问题,原则上不建议在 v2ray 上配置任何分流或路由规则,脚本会为你做这些事,如果你硬要这么做,那么出问题请自行解决,这里不提供相关的指导。下面是一个简单的配置示例:{
"log": {
"access": "/var/log/v2ray/access.log",
"error": "/var/log/v2ray/error.log",
"loglevel": "info" // 调试时请改为 debug
},
"inbounds": [
{
"protocol": "dokodemo-door",
"listen": "0.0.0.0", // 如果仅代理本机,可填环回地址
"port": 60080, // 本地监听端口必须与配置文件中的一致
"settings": {
"network": "tcp,udp", // 注意这里是 tcp + udp
"followRedirect": true
},
"streamSettings": {
"sockopt": {
//"tproxy": "tproxy" // tproxy + tproxy 模式
"tproxy": "redirect" // redirect + tproxy 模式
}
}
}
],
"outbounds": [
{
"protocol": "shadowsocks",
"settings": {
"servers": [
{
"address": "node.proxy.net", // 服务器地址
"port": 12345, // 服务器端口
"method": "aes-128-gcm", // 加密方式
"password": "password" // 用户密码
}
]
}
}
]
}
proxy_startcmd、proxy_stopcmd 例子,假设使用 systemctl 进行启动与停止,则:proxy_startcmd='systemctl start v2ray'
proxy_stopcmd='systemctl stop v2ray'
pre_start(启动前执行)、post_start(启动后执行)、pre_stop(停止前执行)、post_stop(停止后执行)。举个例子,在不修改 ss-tproxy 脚本的前提下,设置一些额外的 iptables 规则,假设我需要在 ss-tproxy 启动后添加某些规则,然后在 ss-tproxy 停止后再删除这些规则,则修改 ss-tproxy.conf,添加以下内容:post_start() {
iptables -A ...
iptables -A ...
iptables -A ...
}
post_stop() {
iptables -D ...
iptables -D ...
iptables -D ...
}
post_start() 钩子函数的内容;目前有这几个自定义链:$ipts -t mangle -N SSTP_PREROUTING
$ipts -t mangle -N SSTP_OUTPUT
$ipts -t nat -N SSTP_PREROUTING
$ipts -t nat -N SSTP_OUTPUT
$ipts -t nat -N SSTP_POSTROUTING
SSTP_ 前缀的同名预定义链上,如下:$ipts -t mangle -A PREROUTING -j SSTP_PREROUTING
$ipts -t mangle -A OUTPUT -j SSTP_OUTPUT
$ipts -t nat -A PREROUTING -j SSTP_PREROUTING
$ipts -t nat -A OUTPUT -j SSTP_OUTPUT
$ipts -t nat -A POSTROUTING -j SSTP_POSTROUTING
SysVinit 发行版,直接在 /etc/rc.d/rc.local 开机脚本中加上 ss-tproxy 的启动命令即可:/usr/local/bin/ss-tproxy start
Systemd 发行版,将 ss-tproxy.service 服务文件放到 /etc/systemd/system/ss-tproxy.service,然后执行:systemctl daemon-reload
systemctl enable ss-tproxy
Systemd 管理 ss-tproxy,应避免使用 ss-tproxy start|stop|restart 这几个命令,当然除了这几个命令外,其它命令都是可以执行的,比如 ss-tproxy status、ss-tproxy update-gfwlist,为什么呢?因为 systemctl 启动一个脚本之后,systemctl 会在内部保存一个状态,即脚本已经 running,然后只有当你下次使用 systemctl 停止该脚本的时候,systemctl 内部才会将这个状态改为 stopped。所以当你执行 systemctl start ss-tproxy 后,这个服务的状态就是 running,如果你执行 ss-tproxy stop 来停止脚本,那么这个服务状态是不会变的,依旧是 running,但实际上它已经 stopped 了,而当你执行 systemctl start ss-tproxy 来启动脚本时,systemctl 并不会在内部执行 ss-tproxy start,因为这个服务的状态是 running,说明已经启动了,就不会再次启动了。这样一来就完全混乱了,你以为执行完毕后 ss-tproxy 就启动了,然而实际上,执行 ss-tproxy status 看下还是 stopped 的。为避免这种情况,请务必使用 systemctl start|stop|restart ss-tproxy,而不是 ss-tproxy start|stop|restart,换句话说,不要交叉使用这两套命令。ss-tproxy help:查看帮助信息ss-tproxy version:查看版本号ss-tproxy start:启动透明代理ss-tproxy stop:关闭透明代理ss-tproxy restart:重启透明代理ss-tproxy status:查看代理状态ss-tproxy show-iptables:查看当前的 iptables 规则ss-tproxy flush-postrule:清空遗留的 iptables 规则ss-tproxy flush-dnscache:清空 dnsmasq 的查询缓存ss-tproxy delete-gfwlist:删除 gfwlist 黑名单 ipsetss-tproxy update-chnlist:更新 chnlist(restart 生效)ss-tproxy update-gfwlist:更新 gfwlist(restart 生效)ss-tproxy update-chnroute:更新 chnroute(restart 生效)- 在任意位置指定
-x选项可启用调试,如ss-tproxy start -x
ss-tproxy delete-gfwlist 的作用:在 gfwlist/chnlist 模式下,ss-tproxy restart、ss-tproxy stop; ss-tproxy start 并不会移除 gfwlist 这个 ipset,如果你进行了 ss-tproxy update-gfwlist、ss-tproxy update-chnlist 操作,或者修改了 /etc/ss-tproxy/gfwlist.ext 文件,建议在 start 前执行一下此步骤,防止因为之前遗留的 gfwlist 列表导致奇怪的问题。注意,如果执行了 ss-tproxy delete-gfwlist 那么你可能还需要清空内网主机的 dns 缓存,并重启浏览器等被代理的应用。ss-tproxy.conf 的特殊配置项,请先执行 ss-tproxy stop,然后再修改配置文件,最后再执行 ss-tproxy start 来生效,而不是改好配置后执行 ss-tproxy restart,这会出现不可预估的错误,需要遵循这个约定的配置项有:ipv4ipv6proxy_stopcmdipts_rt_tabipts_rt_markopts_overwrite_resolvfile_dnsserver_pid
ss-tproxy restart 命令来生效,无需遵循上述约定。pre_start() 钩子来加载它:pre_start() {
# 加载 TPROXY 模块
modprobe xt_TPROXY
}
post_start() 将它们加到 ipset 中:post_start() {
# 定义要放行的 IPv4 地址
local chnroute_append_list=(11.22.33.44 44.33.22.11)
for ipaddr in "${chnroute_append_list[@]}"; do
ipset add chnroute $ipaddr &>/dev/null
done
# 定义要放行的 IPv6 地址
local chnroute_append_list6=(2400:da00::6666 2001:dc7:1000::1)
for ipaddr in "${chnroute_append_list6[@]}"; do
ipset add chnroute6 $ipaddr &>/dev/null
done
}
dnsmasq_conf_file/dnsmasq_conf_dir 选项,首先创建一个 dnsmasq 配置文件,比如在 /etc/ss-tproxy 目录下创建 chnroute_ignore.conf,假设想放行 github.com 以及 github.io 两个域名,则配置内容如下:server = /github.com/114.114.114.114
server = /github.io/114.114.114.114
ipset = /github.com/chnroute,chnroute6
ipset = /github.io/chnroute,chnroute6
dnsmasq_conf_file 数组中写上该配置文件的绝对路径,如 dnsmasq_conf_file=(/etc/ss-tproxy/chnroute_ignore.conf),注意这只适合 chnroute 模式,如果想让配置更加智能些,即只在 chnroute 模式下加载该 dnsmasq 配置,可以将原有的 dnsmasq_conf_file 注释掉,然后在它下面写上一个简单的判断语句即可:if [ "$mode" = 'chnroute' ]; then
dnsmasq_conf_file=(/etc/ss-tproxy/chnroute_ignore.conf)
else
dnsmasq_conf_file=()
fi
post_start() {
# 定义要放行的 IPv4 地址
local intranet_ignore_list=(192.168.1.100 192.168.1.200)
for ipaddr in "${intranet_ignore_list[@]}"; do
iptables -t mangle -I SSTP_PREROUTING -s $ipaddr -j RETURN
iptables -t nat -I SSTP_PREROUTING -s $ipaddr -j RETURN
done
# 定义要放行的 IPv6 地址
local intranet_ignore_list6=(fd00:abcd::1111 fd00:abcd::2222)
for ipaddr in "${intranet_ignore_list6[@]}"; do
ip6tables -t mangle -I SSTP_PREROUTING -s $ipaddr -j RETURN
ip6tables -t nat -I SSTP_PREROUTING -s $ipaddr -j RETURN
done
}
proxy_startcmd 和 proxy_stopcmd 改为空调用,即 proxy_startcmd='true'、proxy_stopcmd='true',然后配置好 proxy_svraddr4/6,将所有可能会用到的服务器地址都放进去,最后执行 ss-tproxy start 启动,因为我们没有填写任何代理进程的启动和停止命令,所以会显示代理进程未运行,没关系,现在我们要做的就是启动对应的代理进程,假设为 ss-redir 且使用 systemd 管理,则执行 systemctl start ss-redir,现在你再执行 ss-tproxy status 就会看到对应的状态正常了,当然代理也是正常的,如果需要换为 v2ray,假设也是使用 systemd 管理,那么只需要先关闭 ss-redir,然后再启动 v2ray 就行了,即 systemctl stop ss-redir、systemctl start v2ray,这相当于启动了一个代理框架,切换代理无需操作 ss-tproxy,直接切换进程即可。- 检查 ss-tproxy.conf 以及代理软件的配置是否正确,此文详细说明了许多配置细节,它们并不是废话,请务必仔细阅读此文。如果确认配置无误,那么请务必开启代理进程的详细日志(debug/verbose logging),以及 dnsmasq、chinadns-ng 的详细日志(ss-tproxy.conf),日志是调试的基础。
- 如果 ss-tproxy 在配置正确的情况下出现运行时报错,请在执行 ss-tproxy 相关命令时带上
-x调试选项,以查看是哪条命令报的错。出现这种错误通常是脚本自身的问题,可直接通过 issue 报告此错误,但是你需要提供尽可能详细的信息,别一句话就应付了我,这等同于应付了你自己。 - 如果 ss-tproxy status 显示的状态不正常,那么通常都是配置问题,
pxy/tcp显示 stopped 表示代理进程的 TCP 端口未监听,pxy/udp显示 stopped 表示代理进程的 UDP 端口未监听,dnsmasq和chinadns-ng显示 stopped 时请查看它们各自的日志文件,可能是监听端口被占用了,等等。 - 在 ss-tproxy 主机上检查 DNS 是否工作正常,域名解析是访问互联网的第一步,这一步如果出问题,后面的就不用测试了。这里选择 dig 作为 DNS 调试工具,因此请先安装 dig 工具。在调试 DNS 之前,先开启几个终端,分别
tail -f代理进程、dnsmasq、chinadns-ng 的日志文件;然后再开一个终端,执行dig www.baidu.com、dig www.google.com,观察 dig 以及前面几个终端的日志输出,发现不对的地方可以先尝试自行解决,如果解决不了,请通过 issue 报告它。对于 ss/ssr,最常见的错误就是代理的 udp relay 未开启,因此请先确保 udp relay 是否正常,udp relay 不正常会导致dig www.google.com解析失败;如果确认已开启 udp relay,那么你还要注意是否出现了 udp 丢包,某些 ISP 会对 udp 数据包进行恶意性丢弃,检查 udp 是否丢包通常需要检查本地以及 vps 上的代理进程的详细日志输出。 - 如果 ss-tproxy 主机的 DNS 工作正常,说明 UDP 透明代理应该是正常的,那么接下来应该检查 TCP 透明代理,最简单的方式就是使用 curl 工具进行检测,首先安装 curl 工具,然后执行
curl -4vsSkL https://www.baidu.com、curl -4vsSkL https://www.google.com,如果启用了 ss-tproxy 的 IPv6 透明代理支持,则还应该进行 IPv6 的网页浏览测试,即执行curl -6vsSkL https://ipv6.baidu.com、curl -6vsSkL https://ipv6.google.com,观察它们的输出是否正常(即是否能够正常获取 HTML 源码),同时观察代理进程、dnsmasq、chinadns-ng 的日志输出。 - 如果 ss-tproxy 主机的 DNS 以及 curl 测试都没问题,那么就进行最后一步,在其它内网主机上分别测试 DNS 以及 TCP 透明代理(最简单的就是浏览器访问百度、谷歌),同时你也应该观察代理进程、dnsmasq、chinadns-ng 的日志输出。对于某些系统,可能会优先使用 IPv6 网络(特别是解析 DNS 时),因此如果你没有启用 ss-tproxy 的 IPv6 透明代理,那么请通过各种手段禁用 IPv6(或者进行其它一些妥当的处理),否则会影响透明代理的正常使用。
在报告问题时,请务必提供详细信息,而不是单纯一句话,xxx 不能工作,这对于问题的解决没有任何帮助。
from https://github.com/zfl9/ss-tproxy
--------------------
当然,ss/ssr 透明代理并不是只能用 ss-redir 来实现,使用 ss-local + redsocks2 同样可以实现 socks5(ss-local 是 socks5 服务器)全局透明代理;ss-local + redsocks2 实际上是 ss-redir 的分体实现,TCP 使用 REDIRECT 方式实现,UDP 使用 TPROXY 方式实现。
最后说一下 v2ray 的透明代理,其实原理和 ss/ssr-libev 一样,v2ray 可以看作是 ss-local、ss-redir、ss-server 的合体,同一个 v2ray 程序既可以作为 server 端,也可以作为 client 端。所以 v2ray 的透明代理也有两种实现方式,一是利用对应的 “ss-redir”(
dokodemo-door入站协议),二是利用对应的 “ss-local”(socks入站协议) + redsocks2(redsocks2 可与任意 socks5 代理组合以实现透明代理)。方案说明
curl -4sSkL -x socks5h://127.0.0.1:1080 https://www.google.com。http_proxy、https_proxy 环境变量,假设存在一个 http 代理(支持 CONNECT 请求方法),监听地址是 127.0.0.1:8118,可以这样做:export http_proxy=http://127.0.0.1:8118; export https_proxy=$http_proxy。执行完后,git、curl、wget 等命令会自动从环境变量中读取 http 代理信息,然后通过 http 代理连接目的服务器。/etc/privoxy/config 里面添加一行 forward-socks5 / 127.0.0.1:1080 .,启动 privoxy,默认监听 127.0.0.1:8118 端口,注意别搞混了,8118 是 privoxy 提供的 http 代理地址,而 1080 是 ss-local 提供的 socks5 代理地址,发往 8118 端口的数据会被 privoxy 处理并转发给 ss-local。所以我们现在可以执行 export http_proxy=http://127.0.0.1:8118; export https_proxy=$http_proxy 来配置当前终端的 http 代理,这样 git、curl、wget 这些就会自动走 ss-local 出去了。/etc/privoxy 目录,然后在 config 中添加一行 actionsfile gfwlist.action(当然之前 forward-socks5 那行要注释掉),重启 privoxy 就可以实现 gfwlist 分流了。http_proxy、https_proxy 环境变量实现的终端代理效果不是很好,因为有些命令根本不理会你的 http_proxy、https_proxy 变量,它们依旧走的直连。但又有大神想出了一个巧妙的方法,即 rofl0r/proxychains-ng,其原理是通过 LD_PRELOAD 特殊环境变量提前加载指定的动态库,来替换 glibc 中的同名库函数。这个 LD_PRELOAD 指向的其实就是 proxychains-ng 实现的 socket 包装库,这个包装库会读取 proxychains-ng 的配置文件(这里面配置代理信息),之后执行的所有命令调用的 socket 函数其实都是 proxychains-ng 动态库中的同名函数,于是就实现了全局代理,而命令对此一无所知。将 proxychains-ng 与 privoxy 结合起来基本上可以完美实现 ss/ssr 的本地全局 gfwlist 代理(小技巧,在 shell 中执行 exec proxychains -q bash 可以实现当前终端的全局代理,如果需要每个终端都自动全局代理,可以在 bashrc 文件中加入这行)。代理脚本
安装依赖
curl
curl --version 可查看(Protocols)perl5
perl -v 命令可查看)ipset
TPROXY
iproute2
dnsmasq
对于 gfwlist/chnlist 模式,需要确保该 dnsmasq 支持--ipset选项。
chinadns
这是原版 chinadns,适用于 ss-tproxy v3.0,ss-tproxy v4.0 请用 chinadns-ng。
chinadns-ng
chinadns-ng 是我利用业余时间用 C 语言编写的另一个 chinadns,修复若干问题,优化了性能。
v2ray
ss-libev
pacman -S shadowsocks-libev 安装,方便快捷,更新也及时。CentOS/RHEL 或其它发行版,强烈建议 编译安装,仓库安装的可能会有问题(版本太老或者根本用不了)。
下面的代码完全摘自 ss-libev 官方 README.md,随着时间的推移可能有变化,最好照着最新 README.md 来做。
ssr-libev
https://github.com/shadowsocksrr/shadowsocksr-libev/tree/Akkariiin/master,另一个 ssr-libev 源,
Akkariiin-* 分支目前仍在更新本文仍以 shadowsocksr-backup/shadowsocks-libev 为例,毕竟另一个源我没试过,但是这个源我自己用过大半年,没有任何问题,很稳定
解决方法就是使用此分支:
git clone -b Akkariiin/develop https://github.com/shadowsocksrr/shadowsocksr-libev.githaveged
代理测试
这里就简单的使用 curl 进行测试,如果有网页源码输出,基本就没什么问题:
对于 ss-tproxy v4.0,如果启用了 ipv6 透明代理,可进行一些简单的 ipv6 测试:
也可以使用 curl 进行一个简单的分流模式验证,原理就是检查访问网站用的外部 IP:
原理解析
这里的脚本解析仅针对 ss-tproxy v3.0,ss-tproxy v4.0 变化太多了,暂时没时间整理。
脚本浅析
dns 解析模块
遍历 proxy_server 数组,如果是域名,则解析为对应 IP,稍后会加到 dnsmasq 的静态解析列表中(相当于 hosts 文件),之所以要这么做,是因为 v2ray 的一个特性造成的,如果给 v2ray 配置的代理服务器为域名,那么 v2ray 每次连接到代理服务器之前,都会去解析这个域名(而不是像 ss-libev、ssr-libev 那样,启动的时候就先解析出对应的服务器 IP),如果没有把这个域名加入静态解析列表,那么此刻代理就会陷入死循环,因为 v2ray 自己发出去的 dns 解析请求被导向代理隧道了(global 模式、chnroute 模式),而代理本身就是要先解析出这个域名对应的 IP 才能连接到我们的代理服务器;而如果我们在启动代理之前就先解析出对应的 IP,并加入 dnsmasq 的静态解析列表,就不会有问题了,因为当 v2ray 发出的 dns 解析请求到达 dnsmasq 时,dnsmasq 会从静态解析列表中返回这个 IP,然后就能正常连接 v2ray 代理服务器了。
比较简单,因为不需要分流,全部解析都交给远程 dns 去解析(8.8.8.8,走代理),之所以加个 dnsmasq,而不是直接用 iptables 代理到 8.8.8.8,是为了利用 dnsmasq 的缓存功能来加速 DNS 解析,不然每次解析都要请求远程服务器,多慢啊,有了 DNS 缓存,我第二次解析同一个域名就直接可以返回给请求客户端了,因此,所有 mode 我都加入了 dnsmasq 来作缓存。
和 global 模式的配置差不多,只不过默认使用国内 dns 进行解析(114.114.114.114,走直连),然后对位于 gfwlist.txt、gfwlist.ext 中的域名使用远程 dns 进行解析(8.8.8.8,走代理),也就是所谓的黑名单模式,当然这里还使用了 dnsmasq 的 ipset 功能,黑名单中的这些域名解析出的 IP 地址会自动加入到我们指定的 ipset 列表中,这样我们在 iptables 规则中就可以动态的让这些 IP 走代理,从而完成分流(域名到 IP 的映射)。
这里的 dnsmasq 就是起到一个缓存的作用,因为 chinadns 不支持 dns 缓存,为了提高解析性能(抗住大并发的 dns 解析请求),所以很有必要加上 dnsmasq;这里解释一下第一段代码的作用,为什么要将直连 dns 加入 chnroute 列表,要理解这个,首先要理解 chinadns 的分流原理(个人理解,有错误还请指出);chinadns 要运行,首先要给它配置两组 dns 服务器,一组是 国内 dns,一组是 可信 dns(国外 dns),所以至少需要给它配置两个上游 dns,就假设为 114.114.114.114(国内 dns)、8.8.8.8(可信 dns,走代理),然后还要给它指定一个 chnroute 列表(大陆地址段);当 chinadns 收到一个解析请求时,它会同时向这两组 dns 发出请求,然后:
- 如果国内 dns 先返回(正常情况,因为直连肯定比代理快),那么 chinadns 会检查国内 dns 返回的 ip 是否为大陆地址(chnroute 列表),如果是,则 chinadns 会直接将这个解析出来的 IP 返回给请求客户端,然后完成解析(忽略可信 dns 的结果);如果国内 dns 返回的 ip 不是大陆地址(chnroute 列表),那么 chinadns 会过滤掉国内 dns 的解析结果,然后等待可信 dns 的解析结果并将其返回给请求客户端,完成解析。
- 如果可信 dns 先返回(非正常情况,比如给可信 dns 加了本地缓存,导致它最先返回),那么 chinadns 会直接返回可信 dns 的解析结果,而不会考虑国内 dns 解析结果,如果是这样的话,那么其实 chinadns 的分流就完全出问题了,根本就没有分流,全都是返回远程 dns 解析出来的结果,所以一定不能给 chinadns 的可信 dns 设置 dns 缓存(如给它套一层 dnsmasq/pdnsd/dnsforwarder)。
iptables 规则
start_iptables() 这个函数基本上是最复杂的函数了,但只要理清楚了这里面的关系和执行逻辑,就很容易理解。常见问题
这里有些问答可能仅适用于 ss-tproxy v3.0,请仔细甄别,切勿盲目照搬照抄。
首先排查是不是
ipts_non_snat 选项的问题,默认我设置的是 false,双重否定其实就是肯定,也就是说设置为 false 的话就表示会设置 SNAT 规则,通常情况下,只有你真的需要 SNAT 规则时你才需要将其设置为 false,比如你在网络出口位置使用 ss-tproxy(一头连接内网,一头连接公网),那么就需要设置 SNAT 规则,但其实这种情况下你的系统上早就已经设置好了 SNAT 规则,不然你是怎么上网的,对吧。因此,无论什么情况,都先尝试将 ipts_non_snat 选项设为 true,除非你在设置为 true 的情况下代理有问题,那么你才需要将其设置为 false。另外,这个选项如果你设置过 false,并启动了 ss-tproxy,那么除非你手动清除这个 SNAT 规则或者重启系统(nat 表,POSTROUTING 链),否则系统中还是会存在这个 SNAT 规则的,保险起见,在切换 ipts_non_snat 选项后,先执行一遍 ss-tproxy flush-iptables 命令(ss-tproxy v4.0 无此问题)。如果你对 iptables 规则不是很了解,请在启动 ss-tproxy 之前将已有的 iptables 规则清空,通常情况下执行命令
ss-tproxy flush-iptables 即可清空,但最好自己再检查一下,因为据反馈有些系统的规则还是无法彻底清除,那么怎么检查呢?执行 flush-iptables 之后,手动执行下面几个命令,查看 raw、mangle、nat、filter 表的规则,如果都是空的那说明就是彻底清空了:ss-tproxy flush-iptables 清理命令,如下,这样每次启动 ss-tproxy 都会自动清空规则:首先检查 ss-tproxy.conf 中的 opts_ss_netstat 选项值是否设置正确,默认是 auto 自选选择模式,即如果有 ss 就优先使用 ss 命令,如果没有才会去使用 netstat 命令;如果自动选择模式对你不适用,那么可以改为 ss 或 netstat 来明确告诉 ss-tproxy 你要使用哪个端口检测命令(有些系统没有 ss,而有些系统却只有 ss);如果确定不是这个选项的问题,那么我估计你遇到了这个问题:执行 ss-tproxy start|restart 后,发现 pxy/tcp 和 pxy/udp 的状态是 stopped 的,然后再次执行 ss-tproxy status 查看状态,却又发现是 running 的,且代理进程也正常启动了,代理也是正常的;这个其实不是 ss-tproxy 的问题,应该是 ss、netstat 的检测延迟问题,因为第一次状态检测(start|restart)是在 proxy_runcmd 运行之后立即执行的,因为某些原因(具体什么原因我也没详细了解),导致 ss/netstat 没检测到对应的监听端口(或者还有一种情况,就是代理进程此时可能还没监听端口,还在处理其它事,如还在处理命令行选项等等,反正都有可能),然后你再次执行 status 命令查看状态时,因为存在一个时间间隔,所以基本上就能正常检测到了。
ipv6 已经在 ss-tproxy v4.0 中实现,欢迎大家进行测试,我目前并没有 ipv6 环境,测试是在某位热心网友协助下进行的,在此表示感谢。
就拿 ss/ssr 来说,ss-redir/ssr-redir 需要开启 udp relay 功能,然后 ss-server/ssr-server 也需要开启 udp relay 功能,如果服务器还有防火墙规则,请注意放行对应的 udp 端口,此外还请确认你当地的 ISP 没有对 udp 流量进行恶意丢包。对于 v2ray(vmess),因为它的 udp 是通过 tcp 转发出去的(即
udp over tcp),所以不需要放行服务器的防火墙端口,也不需要担心 ISP 对 udp 流量的恶意干扰,因为根本没有走 udp,而是走的 tcp。如果你因为各种原因无法使用 udp relay,请考虑使用 v2ray,而且现在网络环境越来越差,ss/ssr 貌似有些顶不住了。其实非常简单,使用 gfwlist 模式即可;gfwlist 模式会读取 gfwlist.txt、gfwlist.ext 两个黑名单文件,如果你只想代理某些域名、IP、网段,其它的都不想代理,可以直接将 gfwlist.txt 文件清空(执行命令
true >/etc/ss-tproxy/gfwlist.txt),然后编辑 gfwlist.ext 文件,填写要代理的域名、IP、网段即可(文件中有格式说明)。注意,在这种模式下就不要执行 update-chnonly、update-gfwlist 命令了,因为它们会操作 gfwlist.txt 文件。如果你因为各种原因无法编译 ss-libev、ssr-libev,但又想使用 ss-tproxy 的透明代理功能,也可以使用 redsocks2 来将任意支持 udp 的 socks5 代理转换为透明代理,这样即使你没有 ss-libev、ssr-libev,也可以使用 ss-tproxy 的透明代理功能(即使用 python 版 ss/ssr + redsocks2 来做透明代理)。当然因为我的系统只安装了 libev 版本,没有安装 python 版本,所以这里依旧使用 ssr-local 作为例子讲解(如果使用 python 版的 ss/ssr,那么你只需要将对应的 ssr-local 替换为 sslocal 命令,但记得开启 udp relay),怎么编译 redsocks2(注意是 redsocks2,不是原版 redsocks)这里就不多说了,官方 readme 有详细说明;我们只需要关注 redsocks2 的配置文件(假设文件路径为 /etc/redsocks2.conf):
start_ssrlocal_redsocks2 函数,比如在文件末尾添加:如果是 iptables -j TPROXY 这条命令报的错(使用
bash -x /usr/local/bin/ss-tproxy start 查看调试信息),那就是没有 TPROXY 模块。如果运行脚本时报了这个错误,你应该检查一下你的 bash 是不是正常版本,或者使用
ls -l /bin/bash 看下这个文件是否软连接到了其它 shell。特别注意,因为 ss-tproxy 和 ss-tproxy.conf 都是一个 bash 脚本,所以这两个文件的内容也必须符合 bash 的语法规则,比如你不能在里面重复定义一个函数,虽然这不会报错,但是只有最后一个函数才会生效,这可能会坑死你,如果你定义了多个同名的 bash 函数,请将它们合并为一个!
如果你经常使用 BT/PT 下载,请务必使用 gfwlist 模式,如果使用 global/chnroute 模式,可能会消耗大量的 VPS 流量,甚至可能导致 VPS 被封(因为很多主机商都不允许 BT/PT 下载)。因为使用 iptables 来识别 BT/PT 流量的效率太低(基本都是使用 string 模块来匹配,我个人是无法接受的),所以最好的办法还是使用 gfwlist 模式,因为 gfwlist 模式下只有被墙了的网站才会走代理,其它的都是走直连(绝大多数 BT/PT 流量)。
对于 ss-tproxy v4.0,你可以指定要代理的目的端口,可以利用此选项来避免 BT/PT 流量走代理的问题,具体请看 4.0 的 README。
8.8.8.8:53 DNS 有问题请关闭 chinadns 的压缩指针,即将 ss-tproxy.conf 中的 chinadns_mutation 改为 false(新版已默认关闭),启用压缩指针时,有时候使用 1.1.1.1、8.8.8.8、8.8.4.4 这些国外 DNS 会有问题,无法正常解析 DNS,导致的现象就是国内网站可以上,但是国外网站不能上。ss-tproxy v4.0 无此问题。
如果是 dnsmasq 或 chinadns 启动失败,请先检查 /var/log 下面的日志,看看是不是监听地址被占用了(按道理来说,v3 最新版本已经将它们两个的监听端口调的很高了,基本没有与之冲突的监听地址);如果是 pxy/tcp 或 pxy/udp 启动失败,请检查 ss-tproxy.conf 里面的 proxy_tcport 和 proxy_udport 端口是否与 proxy_runcmd 启动的进程的监听端口一致,因为默认情况下,ss-redir 或 ssr-redir 的监听端口是 1080,而 ss-tproxy 设置的是 60080,当然这个端口是可以随便改的,但是我觉得还是使用高位端口好一些,省得那么多端口冲突。
从其它模式切换到 gfwlist 模式时可能出现这个问题,原因还是因为内网主机的 DNS 缓存。在访问被墙网站时,比如 www.google.com,客户机首先会进行 DNS 解析,由于存在 DNS 缓存,这个 DNS 解析请求并不会被 ss-tproxy 主机的 dnsmasq 处理(因为根本没从客户机发出来),所以对应 IP 不会添加到 ipset-gfwlist 列表中,导致客户机发给该 IP 的数据包不会被 ss-tproxy 处理,也就是走直连出去了,GFW 当然不会让它通过了,也就出现了连接被重置等问题。解决方法也很简单,对于 Windows,请先关闭浏览器,然后打开 cmd.exe,执行
ipconfig /flushdns 来清空 DNS 缓存,然后重新打开浏览器,应该正常了;对于 Android,可以先打开飞行模式,然后再关闭飞行模式,或许可以清空 DNS 缓存。如果你在 ss-tproxy 中使用的是自己的 VPS 的代理服务,那么在除 ss-tproxy 主机外的其他主机上会可能会出现无法访问这台 VPS 的情况(比如 SSH 连不上,但是 ping 没问题),具体表现为连接超时。起初怀疑是 ss-tproxy 主机的 iptables 规则设置不正确,然而使用 TRACE 追踪后却什么都没发现,一切正常;在 VPS 上使用 tcpdump 抓包后,发现一个很奇怪的问题:VPS 在收到来自客户端的 SYN 请求后并没有进行 SYN+ACK 回复,客户端在尝试了几次后就会显示连接超时。于是怀疑是不是 VPS 的问题,谷歌之后才知道,原来是因为两个内核参数设置不正确导致的,这两个内核参数是:
net.ipv4.tcp_tw_reuse、net.ipv4.tcp_tw_recycle,将它们都设为 0(也就是禁用)即可解决此问题。其实这两个内核参数默认都是为 0 的,也就是说,只要你没动过 VPS 的内核参数,那么基本不会出现这种诡异的问题。这里说的 DHCP 配置仅针对“代理网关”模式,其实如何配置 DHCP 完全取决于你自己的需求,第一种:将路由器 DHCP 分配的 Gateway 和 DNS 改为 ss-tproxy 主机的地址,然后给 ss-tproxy 主机配置静态 IP,注意不能使用 DHCP 来获取,因为获取到的 Gateway 是指向自己的,显然有问题,这种方式下,所有内网主机默认通过 ss-tproxy 代理上网,如果某些主机不想走代理,可以手动将这些主机的 Gateway 和 DNS 改为原来的,就可以恢复直连了,不会走代理。第二种:不改变任何 DHCP 配置,默认情况下除 ss-tproxy 主机本身外,其它主机都是走直连的,如果你想让某些主机走代理上网,可以手动将这些主机的 Gateway 和 DNS 改为 ss-tproxy 主机的 IP,这样就可以走代理上网了。当然如果你的路由器支持为不同的主机设置不同的 Gateway 和 DNS,那么也可以不修改任何内网主机的配置,直接在路由上配置对应的 DHCP 规则就行了。
一般都支持,没有限制,因为没有使用与特定发行版相关的命令和特性(我自己用的是 ArchLinux),当然我说的是普通 x86、arm 发行版,如果是路由器的那种系统,应该会有点问题,但是移植起来应该不难。我测试过的系统有:ArchLinux、RHEL、CentOS、Debian、Alpine;经过几个网友测试,OpenWrt 貌似也可以,当然需要自己改一些东西,比如 OpenWrt 自带的 bash 是有问题的,阉割版,运行起来会报错,换为标准版 bash 就没问题。
显然不是,你可以在一台普通的 linux 主机(甚至是桥接模式下的虚拟机)上运行,并且这种方式也是能够透明代理其它主机的 TCP 和 UDP 的哦。
可以。假设你有两个路由器,一主一副,主路由通过 PPPOE 拨号上网,其它设备连接到主路由可以上外网(无科学上网),副路由的 WAN 口连接到主路由的 LAN 口,副路由的 WAN 网卡 IP 可以动态获取,也可以静态分配,此时,副路由自己也是能够上外网的。然后,在副路由上运行 ss-tproxy,此时,副路由已经能够科学上网了,然后,我们在副路由上配置一个 LAN 网段(不要与主路由的 LAN 网段一样),假设主路由的 LAN 网段是 192.168.1.0/24,副路由的 LAN 网段是 10.10.10.0/24。然后指定一个网关 IP 给副路由的 LAN 口,假设为 10.10.10.1,开启副路由上的 DHCP,分配的地址范围为 10.10.10.100-200,分配的网关地址为 10.10.10.1,分配的 DNS 服务器为 10.10.10.1。现在,修改 ss-tproxy.conf 的内网网段为 10.10.10.0/24,重启 ss-tproxy,然后连接到副路由的设备应该是能够科学上网的。你可能会问,为什么不直接在主路由上安装 ss-tproxy 呢?假设这里的副路由是一个树莓派,那么我不管在什么网络下(公司、酒店),只要将树莓派插上,然后我的设备(手机、笔记本)只需要连接树莓派就能无缝上网了,同时又不会影响内网中的其它用户,一举两得(当然我只是举个栗子,实际上可能没想的这么方便)。
可以。先解释一下这里的“代理网关”(不知道叫什么好),由网友 @feiyu 启发。他的意思是,将 ss-tproxy 部署在一台普通的内网主机上(该主机的网络配置不变),然后将其他内网主机的网关和 DNS 指向这台部署了 ss-tproxy 的主机,进行代理。方案是可行的,我在 VMware 环境中测试通过。注意,这个“代理网关”可以是一台真机,也可以是一台虚拟机(桥接模式),比如在 Windows 系统中运行一个 VMware 或 VirtualBox 的 Linux 虚拟机,在这个虚拟机上跑 ss-tproxy 当然也是可以的(你还别说,真有不少人是这样用的,我在公司也是这么用的)。
这确实是个问题,切换节点需要修改配置文件,切换模式需要修改配置文件,有没有更加简便一些的方式?抱歉,没有。不过因为 ss-tproxy.conf 是一个 shell 脚本,所以我们可以在这里面做些文章。如果你有很多个节点(付费机场一般都是,当然 ss-tproxy 可能更适合自建代理的用户),可以这样做:
当然是可以的,比如你想将 /etc/ss-tproxy 默认目录改为 /opt/ss-tproxy,只需要修改两个地方,一个是 ss-tproxy 脚本的第 3 行,将
main_conf 变量改为 /opt/ss-tproxy/ss-tproxy.conf;另一个是 /opt/ss-tproxy/ss-tproxy.conf 里面的 file_* 变量,改为 /opt/ss-tproxy 目录下的就行了。顺便说一句,ss-tproxy 脚本本身也并不是说一定要放到 /usr/local/bin 目录下,只是我个人喜欢将第三方命令放到这个目录而已。当然 RHEL 7.x 也一样,因为 iptables 和 firewalld 都是 netfilter 的用户空间配置工具,而默认情况下,RHEL/CentOS 7.x 会将 firewalld 服务设置为开机自启动,而且还会设置一些防火墙规则,如果你不关闭这个服务,可能在做代理网关时,会遇到无法上网的情况,所以请务必执行
systemctl disable firewalld 来关闭它(然后重启系统)。当然也不是说一定要关闭 firewalld,如果你对 iptables 和 firewalld 比较熟悉,完全可以自由支配它们。因为 ss-tproxy 脚本里面用到了非常多的 bash 高级重定向,而且有些 built-in 命令和 sh、zsh 的用法不同,无法兼容。
这个怎么说呢,ipip.net 的源我觉得挺好的,用了很久也没啥问题,当然如果需要,你也可以自己改为其它的 chnroute 源,比如改为 APNIC 的大陆地址段列表。但是 ss-tproxy.conf 中并未提供这个选项,该怎么改呢?其实不难,你不需要去修改脚本,只需要在 ss-tproxy.conf 文件末尾添加以下内容(基本框架可以照抄,具体的更新命令可以自定义),ss-tproxy v4.0 已切换至 APNIC 源:
首先,优先选择 C 语言版的 SS/SSR,当然 Python 版也没问题,然后服务器的监听端口我个人觉得 80 和 443 比较好一点,8080 也可以,貌似这些常用端口可以减少 QoS 的影响,当然这只是我个人的一些意见,然后就是修改内核参数,ss-tproxy 主机的 sysctl.conf 以及 vps 的 sysctl.conf 都建议修改一下,最好同步设置。另外我还有一个提速小技巧,那就是在 ss-tproxy 中启动多个 ss-redir、ssr-redir,它们都监听同一个地址和端口(是的你没听错),对于 ss-redir,需要添加一个
--reuse-port 选项来启用端口重用,而对于 ssr-redir,默认情况下就启用了端口重用,而且也没有这个选项。为了简单,这里就以 ss-redir 为例,老规矩,修改 ss-tproxy.conf,添加一个函数,用来启动 N 个 ss-redir 进程:proxy_runcmd,将它改为 proxy_runcmd='start_multiple_ssredir 4',其中 4 可以改为任意正整数,这个数值的意思是启动多少个 ss-redir 进程,一般建议最多启动 CPU 核心数个 ss-redir 进程,太多了性能反而会下降,当然你也可以将它改为 1,此时只会启动一个进程,也就没有所谓的加速了(多个 ss-redir 进程的加速仅针对多线程下载、多终端并发访问的情况,话虽如此,但是效果还是很明显的)。其实非常简单,和上面的多进程 ss-libev、ssr-libev 加速差不多,只不过 ss_addr 不同而已,反正只要这些 ss-redir、ssr-redir 进程监听同一个 addr:port(
127.0.0.1:60080),就可以正常使用,实际上 ss-tproxy 并不关心你使用的是哪个 proxy_server,也不关心你使用的是 ss-libev 还是 ssr-libev 还是 v2ray。有必要声明是,通过 SO_REUSEPORT 端口重用实现的负载均衡是“平均分配”的,假设有 4 个进程同时监听 127.0.0.1:60080,那么内核会将客户端连接平均分配给这 4 个进程(每个进程分配到的概率为 25%)。例子:假设我有 2 个 ss 服务器(1.1.1.1、2.2.2.2),2 个 ssr 服务器(3.3.3.3、4.4.4.4),我想同时使用这 4 个服务器(负载均衡),该如何做?如果 ss-tproxy 主机上没有运行 DNS 服务器(注意,如果代理网关上已经有一个运行在 53 端口上的 dns 服务器,就不要再执行这里的操作了,有些人看都不没看清就直接照抄过去),那就会出现这个问题,因为你的 DNS 设为了 ss-tproxy 主机的 IP,而你执行 stop 操作后,ss-tproxy 上的 dnsmasq 就会被 kill(注意 kill 的是 ss-tproxy 运行的那个 dnsmasq 进程,系统运行的或者你自己运行的 dnsmasq 进程不会被 kill),使得内网主机无法解析 DNS,从而无法上网。解决方法也很简单,修改 ss-tproxy.conf,添加两个钩子函数,
post_stop 钩子函数的作用是在 stop 之后启动一个 dnsmasq,监听 0.0.0.0:53 地址,给内网主机提供普通的 DNS 服务,pre_start 钩子函数的作用是在 start 之前 kill 这个 53 端口的 dnsmasq,因为 ss-tproxy 代理启动后,这个 dnsmasq 进程就没有存在的必要了。ss-tproxy v4.0 自带重定向选项,不需要这么麻烦。起初我是使用
getent hosts $domain_name 来解析域名的,但是后来我发现在某些系统上没有 getent 命令,所以我就改为了 ping 来解析。因为没有这个必要,默认情况下,dnsmasq 监听 60053 端口,chinadns 监听 65353 端口,基本上没哪个进程会监听这两个高位端口,我之所以设置为高位端口也是为了尽可能避免端口冲突问题,在早期版本中,dnsmasq 是监听在 53 端口的,但是我收到了很多关于 dnsmasq 监听端口冲突的反馈,虽然端口冲突问题不难解决,但是我为了一劳永逸,直接将这个端口改为了 60053,从根本上避免了这个问题。ss-tproxy v4.0 支持自定义 dnsmasq、chinadns-ng 监听端口,支持加载外部的 dnsmasq 配置,只要这些配置与 ss-tproxy 使用的配置不冲突就行。
因为 Perl 的正则表达式真的很强大,而且没有兼容性问题,sed、awk、grep 基本都有兼容性问题。注:ss-tproxy v4.0 中 Perl 不再是必要依赖。
可以,当然需要进行一些特殊改造。ss-libev + kcptun 和 ssr-libev + kcptun 操作起来都差不多,为了简单,这里就以 ss-libev 为例。首先我假设你已经在 vps 上运行了 ss-server 和 kcptun-server,并且 ss-server 监听 0.0.0.0:8053/tcp+udp(监听 0.0.0.0 是为了处理 ss-redir 的 udp relay,因为 kcptun 只支持 tcp 协议的加速),kcptun-server 监听 0.0.0.0:8080/udp(用来加速 ss-redir 的 tcp relay,会被封装为 kcp 协议,使用 udp 传输);当然这些端口都是可以自定义的,我并没有规定一定要使用这两个端口!然后编辑 ss-tproxy.conf,修改这几条配置(假设 vps 地址为 1.2.3.4):
kcptun-client、kcptun-server,而是一个很难听的名字,如 client_linux_amd64、server_linux_amd64,我为了好记,将它改为了 kcptun-client、kcptun-server;如果你没有改这个名字,那么你就需要修改一下上面的 kcptun-client 为对应的 client 二进制文件名,但是我建议你改一下,可以省去不少麻烦。然后你可能注意到了 start_sslibev_kcptun 这个命令,这实际上是我们待会要定义的一个函数,方便启动 ss-redir 和 kcptun-client,而不用在 proxy_runcmd 中写很长的启动命令;然后,在 ss-tproxy.conf 的任意位置添加以下配置(我个人喜欢在文件末尾添加),假设 method 为 aes-128-gcm,password 为 passwd.for.test:首先你要清楚一点:ss-tproxy 并不关心你使用什么代理,它关心的仅仅是
proxy_tcport、proxy_udport、proxy_server、proxy_dports:- proxy_tcport:用来接收 TCP 透明代理数据包的端口(REDIRECT/TPROXY),随便填,只要这个端口能处理 TCP 透明代理数据包
- proxy_udport:用来接收 UDP 透明代理数据包的端口(TPROXY),随便填,只要这个端口能处理 UDP 透明代理数据包
- proxy_server:告诉 ss-tproxy,哪些目标地址需要放行,显然,与代理有关的目标 IP 必须填上,如 VPS 的 IP/域名
- proxy_dports:告诉 ss-tproxy,proxy_server 上的哪些端口需要放行,默认是 proxy_server 上的全部端口都放行
我在 README 里面强调过,ss-redir 和 ssr-redir 的监听地址需要指定为 0.0.0.0(当然其它代理软件也一样,如果是 REDIRECT + TPROXY 组合方式的话),如果你不指定这个监听地址,或者指定为监听 127.0.0.1,那么你会发现内网主机是无法正常代理上网的,为什么呢?据我个人猜测,应该是 iptables 的 REDIRECT 的问题(听说改为 DNAT 可以避免这个问题,但经过验证貌似也是有问题的),具体什么原因我也不想深究了,没多大意义。
如果只代理 ss-tproxy 本机的流量,不关心其它内网主机,那么完全可以将监听地址改为 127.0.0.1、::1。
ss-tproxy v4.0 规则变动较大,下面的规则可能不再适用,个人觉得使用浏览器插件进行广告过滤也挺好的。
/opt/koolproxy 目录(当然放哪里没要求),并命名为 koolproxy,然后加上可执行权限;进入 /opt/koolproxy 目录,执行 ./koolproxy --cert 生成 koolproxy HTTPS 证书等文件;因为待会我们需要用一个非 root 用户来运行 koolproxy 进程(可以从 /etc/passwd 中随便找一个已存在的用户,比如 daemon),所以我们要先将 /opt/koolproxy 目录的所有者改为 daemon,不然 koolproxy 自动更新广告过滤规则时会遇到权限问题,即执行命令 chown -R daemon:daemon /opt/koolproxy;最后编辑 ss-tproxy.conf,在文件末尾添加这两个钩子函数,就可以实现 koolproxy + ss-tproxy 组合方式的 广告过滤 + 透明代理(广告过滤或多或少都会影响性能,如果设备性能不太好,不建议集成 koolproxy 等广告过滤软件,这种情况下在客户端进行广告过滤会好一些):from https://www.zfl9.com/ss-redir.html
------
debian desktop os上的透明代理网关
ESXi 透明代理虚拟机
0. 项目背景
由于工作的环境是
ESXi ,上面运行着一堆虚拟机,用来做部署方案测试使用。因为要经常访问 GitHub 以及要去 gcr.k8s.io 上拉去镜像;而且在写
Dockerfile build 镜像的时候,也需要去 GitHub 下载 release 包;使用helm初始化时需要的docker
镜像无法pull那个速度比百度网盘还慢啊啊啊啊,气死人。我觉着 GFW
的存在严重第影响了我的工作效率,遂决定搓一个虚拟机来当代理网关,或者叫旁路网关。被需要代理的机器仅仅需要修改网关和 DNS 为透明代理服务器
IP 即可。
题外话:其实用软路由 LEDE/OpenWrt 实现最合适,而且占用资源也极低,但因为使用软路由发生了一次事故,所以就不再用软路由了。那时候刚入职实习,在 ESXi 上装了个 LEDE 软路由,然后办公室的网络就瘫痪了。。
1.实现功能
- 透明代理,客户端仅仅需要修改默认网关为上游透明网关即可,无需安装其他代理软件
- 国外/国内域名分开解析,解决运营商DNS域名污染问题
- 加快客户端访问GitHub、Google等网站速度,clone速度峰值 15MB/S
- Docker pull 镜像速度 15MB/S,clone torvalds/linux
- 需要代理的内网机器仅仅需要修改网关和 DNS 即可实现透明代理
2. 实现效果
1. wget 下载 GitHub release 上的文件,以 Linux为例
163M Aug 23 21:35 v5.3-rc5.tar.gz 163M 的文件用时不到 30s
3. 实现过程
0. project
主要使用到 ss-tproxy 这个项目,按照项目上的 README 部署部署起来就 ojbk
大佬的博客ss/ssr/v2ray/socks5 透明代理 ,很详细,建议认真读完
1. OS
首先虚拟机的系统我是使用的 Debian 10,使用 netinst 镜像安装好的,当然你也可以使用 Ubuntu ,选择 Debian 是因为 Debian 可以再精简一些,安装后的占用不到 700MB 。至于 Alpine 可能要费点功夫,因为编译需要的包比较麻烦。
2. 安装编译环境和依赖
Debian 和 Ubuntu 的话就一把梭子就行哈
3. 安装爱国软件
这里根据你的代理软件安装配置好就行,我就剽窃一下 shadowsocks-libev 官方的 wiki
4. 安装 Chinadns
安装 Chinadns 实现域名分流,国内的域名交给国内的 DNS (119.29.29.29 或 223.6.6.6) 来解析,国外的域名交给 国外的 DNS (8.8.8.8 或 1.1.1.1)来解析
5. 安装 ss-tproxy
6. 配置 ss-redir
7. 配置 ss-tproxy
剽窃一下官方的配置文件 /etc/ss-tproxy/ss-tproxy.conf
## dnsmasq
dnsmasq_bind_port='53' # dnsmasq 服务器监听端口,见 README。
dnsmasq_cache_size='4096' # DNS 缓存条目,不建议过大,4096 足够
dnsmasq_cache_time='3600' # DNS 缓存时间,单位是秒,最大 3600 秒
dnsmasq_log_enable='false' # 记录详细日志,除非进行调试,否则不建议启用
dnsmasq_log_file='/var/log/dnsmasq.log' # 日志文件,如果不想保存日志可以改为 /dev/null
dnsmasq_conf_dir=() # `--conf-dir` 选项的参数,可以填多个,空格隔开
dnsmasq_conf_file=() # `--conf-file` 选项的参数,可以填多个,空格隔开
## chinadns
chinadns_bind_port='65353' # chinadns-ng 服务器监听端口,通常不用改动
chinadns_verbose='false' # 记录详细日志,除非进行调试,否则不建议启用
chinadns_logfile='/var/log/chinadns.log' # 日志文件,如果不想保存日志可以改为 /dev/null
## dns
dns_direct='119.29.29.29' # 本地 IPv4 DNS,不能指定端口,也可以填组织、公司内部 DNS
dns_direct6='240C::6666' # 本地 IPv6 DNS,不能指定端口,也可以填组织、公司内部 DNS
dns_remote='8.8.8.8#53' # 远程 IPv4 DNS,必须指定端口,提示:访问远程 DNS 会走代理
dns_remote6='2001:4860:4860::8888#53' # 远程 IPv6 DNS,必须指定端口,提示:访问远程 DNS 会走代理
## ipts
ipts_rt_tab='233' # iproute2 路由表名或表 ID,除非产生冲突,否则不建议改动该选项
ipts_rt_mark='0x2333' # iproute2 策略路由的防火墙标记,除非产生冲突,否则不建议改动该选项
ipts_set_snat='false' # 设置 iptables 的 MASQUERADE 规则,布尔值,`true/false`,详见 README
ipts_set_snat6='true' # 设置 ip6tables 的 MASQUERADE 规则,布尔值,`true/false`,详见 README
ipts_intranet=(10.20.172.0/24) # 要代理的 IPv4 内网网段,可填多个,空格隔开,该选项的具体说明请看 README
ipts_intranet6=(fd00::/8) # 要代理的 IPv6 内网网段,可填多个,空格隔开,该选项的具体说明请看 README
ipts_reddns_onstop='true' # ss-tproxy stop 后,是否将其它主机发至本机的 DNS 请求重定向至本地直连 DNS,详见 README
ipts_proxy_dst_port='1:65535' # 目标 IP 的哪些端口走代理,目标 IP 就是黑名单 IP,多个用逗号隔开,冒号为端口范围(含边界)
## opts
opts_ss_netstat='auto' # auto/ss/netstat,用哪个端口检测命令,见 README
opts_overwrite_resolv='false' # true/false,定义如何修改 resolv.conf,见 README
opts_ip_for_check_net='114.114.114.114' # 用来检测外网是否可访问的 IP,该 IP 需要允许 ping
## file
file_gfwlist_txt='/etc/ss-tproxy/gfwlist.txt' # gfwlist 黑名单文件 (默认规则)
file_gfwlist_ext='/etc/ss-tproxy/gfwlist.ext' # gfwlist 黑名单文件 (扩展规则)
file_chnroute_set='/etc/ss-tproxy/chnroute.set' # chnroute 地址段文件 (iptables)
file_chnroute6_set='/etc/ss-tproxy/chnroute6.set' # chnroute6 地址段文件 (ip6tables)
file_dnsserver_pid='/etc/ss-tproxy/.dnsserver.pid' # dnsmasq 和 chinadns-ng 的 pid 文件
8. 启动
启动前,需先关闭本机的 dnsmasq 进程,不然会提示 53 端口已占用。4. 结语
完成以上该能跑起来了,需要注意的是,透明网关要和需要代理的机器在同一网段,不可跨网段,只能在一个 LAN 局域网里。最后祝 GFW 早点倒吧。完整脚本,在 Debian 10 下测试通过:
-----
基于shadowsocks构建局域网翻墙
理论概述
大致的思路- NAT实现局域网机器与internet联通
- dnsmasq+China DNS+ss-tunnel 解决DNS污染
- iptables+ipset+shadowsocks实现数据翻墙
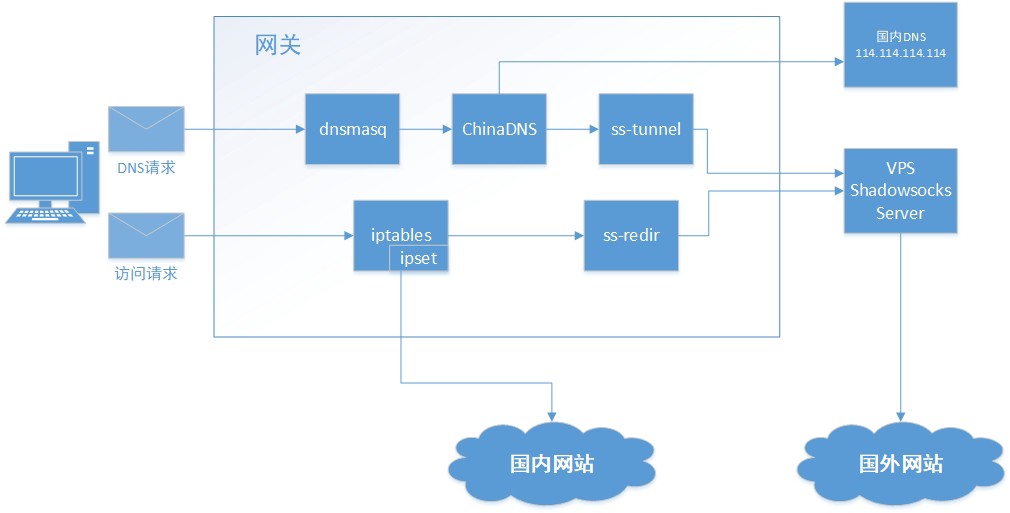
基础环境
基本的网络结构是,用一台最小规格的centos服务器用于网关服务器,只是用于网络流量转发。购买EIP访问外部internet,局域网中的所有数据流量通过该服务器进行中转。局域网中的机器通过NAT转发到网关服务器中的EIP网卡上,从而实现访问internet网络。外部的机器如果要访问局域网内的某个服务端口,采用DNAT映射的方式访问。
dns污染
大致原理,利用dnsmasq在网关服务器上搭建一个dns服务中转&缓存,局域网内所有机器均设置网络为第一dns服务器。dns服务器的搭建模式,使用dnsmasq作为dns的缓存服务器,dnsmasq默认dns解析采用chinadns,chinadns在解析的使用默认使用两个地址解析,一个使用电信默认的dns服务器114.114.114.114. 另一个使用ss-tunnel转发到境外服务器上的shadowsocks服务器利用境外地址解析,对比后获得是否已经污染,从而获取没有污染的域名地址。
数据穿墙
利用ipset构建一个国内地址池,将局域网内网地址及国内地址直接通过网关服务器转发至公网,其余地址数据通过shadowsocks转发境外的shadowsock服务器。搭建基础网络环境
搭建dns
安装dnsmasqyum update
yum install dnsmasq
no-resolv
server=127.0.0.1#5353 #注意这里的端口是chinadns的监听端口
service dnsmasq start
下载并解压chinadns,下载地址
wget https://github.com/shadowsocks/ChinaDNS/releases/download/1.3.2/chinadns-1.3.2.tar.gz
tar -xvf chinadns-1.3.2.tar.gz
./configure && make
src/chinadns -m -c chnroute.txt
cp ./src/chinadns /usr/local/bin/
chinadns -c ./chinadns-1.3.2/chnroute.txt \
-m -p 5353 \ #这里的端口号要与前面配置dnsmasq一致
-s 114.114.114.114,127.0.0.1:5300 \
1> /var/log/$NAME.log \
2> /var/log/$NAME.err.log &
安装ss-redir
安装依赖库
yum install epel-release -y
yum install gcc gettext libtool automake make pcre-devel asciidoc xmlto \
c-ares-devel libev-devel libsodium-devel mbedtls-devel -y
下载shadowsocks-libdev
git clone https://github.com/shadowsocks/shadowsocks-libev.git
cd shadowsocks-libdev
# Installation of Libsodium
export LIBSODIUM_VER=1.0.13
wget https://download.libsodium.org/libsodium/releases/libsodium-$LIBSODIUM_VER.tar.gz
tar xvf libsodium-$LIBSODIUM_VER.tar.gz
pushd libsodium-$LIBSODIUM_VER
./configure --prefix=/usr && make
sudo make install
popd
sudo ldconfig
# Installation of MbedTLS
export MBEDTLS_VER=2.6.0
wget https://tls.mbed.org/download/mbedtls-$MBEDTLS_VER-gpl.tgz
tar xvf mbedtls-$MBEDTLS_VER-gpl.tgz
pushd mbedtls-$MBEDTLS_VER
make SHARED=1 CFLAGS=-fPIC
sudo make DESTDIR=/usr install
popd
sudo ldconfig
# Start building
./autogen.sh && ./configure && make
sudo make install
nohup ss-tunnel -s -p -b 0.0.0.0 -l 5300 \
-k -m aes-256-cfb -L 8.8.8.8:53 -u &
配置转发
开启转发规则
修改/etc/sysctl.confnet.ipv4.ip_forward=1
sysctl -p
配置IPSET
curl -sL http://f.ip.cn/rt/chnroutes.txt | egrep -v '^$|^#' > cidr_cn
sudo ipset -N cidr_cn hash:net
for i in `cat cidr_cn`; do echo ipset -A cidr_cn $i >> ipset.sh; done
chmod +x ipset.sh && sudo ./ipset.sh
rm -f ipset.cidr_cn.rules
sudo ipset -S > ipset.cidr_cn.rules
sudo cp ./ipset.cidr_cn.rules /etc/ipset.cidr_cn.rules
配置IPTables
iptables -t nat -N shadowsocks
# 保留地址、私有地址、回环地址 不走代理
iptables -t nat -A shadowsocks -d 0/8 -j RETURN
iptables -t nat -A shadowsocks -d 127/8 -j RETURN
iptables -t nat -A shadowsocks -d 10/8 -j RETURN
iptables -t nat -A shadowsocks -d 169.254/16 -j RETURN
iptables -t nat -A shadowsocks -d 172.16/12 -j RETURN
iptables -t nat -A shadowsocks -d 192.168/16 -j RETURN
iptables -t nat -A shadowsocks -d 224/4 -j RETURN
iptables -t nat -A shadowsocks -d 240/4 -j RETURN
# 以下IP为局域网内不走代理的设备IP
iptables -t nat -A shadowsocks -s 10.0.0.111 -j RETURN
# 发往shadowsocks服务器的数据不走代理,否则陷入死循环
# 替换111.111.111.111为你的ss服务器ip/域名
iptables -t nat -A shadowsocks -d 111.111.111.111 -j RETURN
# 大陆地址不走代理,因为这毫无意义,绕一大圈很费劲的
iptables -t nat -A shadowsocks -m set --match-set cidr_cn dst -j RETURN
# 其余的全部重定向至ss-redir监听端口1080(端口号随意,统一就行)
iptables -t nat -A shadowsocks ! -p icmp -j REDIRECT --to-ports 1080
# OUTPUT链添加一条规则,重定向至shadowsocks链
iptables -t nat -A OUTPUT ! -p icmp -j shadowsocks
iptables -t nat -A PREROUTING ! -p icmp -j shadowsocks
配置默认网关
有两种方式都可以:- 修改默认的route关系
route del default
route add default gw 10.0.0.111 eth0
- 增加一个NAT转发规则:
iptables -t nat -A POSTROUTING -o eth0 -s 10.0.0.0/16 -j SNAT --to 10.0.0.111
if [ -f china_cidr.txt ]; then
echo "cidr txt existing, try to delete it..."
rm -f china_cidr.txt
fi
echo "try to get cidr from apnic..."
wget
-O- 'http://ftp.apnic.net/apnic/stats/apnic/delegated-apnic-latest' |
awk -F\| '/CN\|ipv4/ { printf("%s/%d\n", $4, 32-log($5)/log(2)) }' >
china_cidr.txt
echo "cidr generated in china_cidr.txt"
if [ -f china_ipset.sh ]; then
echo "ipset script exiting, try to delete it..."
rm -f china_ipset.sh
fi-------------------------
https://github.com/chaosworld/global-proxy-for-linux-with-shadowsocks-libev
----------------------
ipt2socks
utility for converting iptables(redirect/tproxy) to socks5
keep it simple, stupid,保持简单和愚蠢)。ipt2socks 可以为仅支持 socks5 传入协议的“本地代理”提供 iptables 透明代理 传入协议的支持,比如 ss/ssr 的 ss-local/ssr-local、v2ray 的 socks5 传入协议、trojan 的 socks5 客户端等等。简要说明
- IPv4 和 IPv6 双栈支持,支持 纯 TPROXY 透明代理模式,专为 ss-tproxy 而写。
- TCP 透明代理提供 REDIRECT、TPROXY 两种方式,UDP 透明代理为 TPROXY 方式。
- UDP 透明代理支持 Full Cone NAT,前提是后端的 socks5 服务器支持 Full Cone NAT。
- 多线程 + SO_REUSEPORT 端口重用,每个线程运行各自独立的事件循环,性能提升显著。
如何编译
git clone https://github.com/zfl9/ipt2socks
cd ipt2socks
make && sudo make install
/usr/local/bin/ipt2socks,可安装到其它目录,如 make install DESTDIR=/opt/local/bin。ipt2socks 不依赖任何第三方库,可直接拷贝到目标系统运行:# 进入某个目录
cd /opt
# 获取 libuv 源码包
libuv_version="1.32.0" # 定义 libuv 版本号
wget https://github.com/libuv/libuv/archive/v$libuv_version.tar.gz -Olibuv-$libuv_version.tar.gz
tar xvf libuv-$libuv_version.tar.gz
# 进入源码目录,编译
cd libuv-$libuv_version
./autogen.sh
./configure --prefix=/opt/libuv --enable-shared=no --enable-static=yes CC="gcc -O3"
make && sudo make install
cd ..
# 获取 ipt2socks 源码
git clone https://github.com/zfl9/ipt2socks
# 进入源码目录,编译
cd ipt2socks
make INCLUDES="-I/opt/libuv/include" LDFLAGS="-L/opt/libuv/lib" && sudo make install
如何运行
# -s 指定 socks5 服务器 ip
# -p 指定 socks5 服务器端口
ipt2socks -s 127.0.0.1 -p 1080
ipt2socks 启动后,配置相应的 iptables 规则即可。这里就不详细介绍了,有兴趣的请戳 ss-tproxy。
$ ipt2socks --help
usage: ipt2socks <options...>. the existing options are as follows:
-s, --server-addr <addr> socks5 server ip address, <required>
-p, --server-port <port> socks5 server port number, <required>
-a, --auth-username <user> username for socks5 authentication
-k, --auth-password <passwd> password for socks5 authentication
-b, --listen-addr4 <addr> listen ipv4 address, default: 127.0.0.1
-B, --listen-addr6 <addr> listen ipv6 address, default: ::1
-l, --listen-port <port> listen port number, default: 60080
-j, --thread-nums <num> number of worker threads, default: 1
-n, --nofile-limit <num> set nofile limit, maybe need root priv
-o, --udp-timeout <sec> udp socket idle timeout, default: 300
-c, --cache-size <size> max size of udp lrucache, default: 256
-f, --buffer-size <size> buffer size of tcp socket, default: 8192
-u, --run-user <user> run the ipt2socks with the specified user
-G, --graceful gracefully close the tcp connection pair
-R, --redirect use redirect instead of tproxy (for tcp)
-T, --tcp-only listen tcp only, aka: disable udp proxy
-U, --udp-only listen udp only, aka: disable tcp proxy
-4, --ipv4-only listen ipv4 only, aka: disable ipv6 proxy
-6, --ipv6-only listen ipv6 only, aka: disable ipv4 proxy
-v, --verbose print verbose log, default: <disabled>
-V, --version print ipt2socks version number and exit
-h, --help print ipt2socks help information and exit
- -s 选项指定 socks5 服务器的监听地址。
- -p 选项指定 socks5 服务器的监听端口。
- -a 选项指定 socks5 服务器的认证用户。
- -k 选项指定 socks5 服务器的认证密码。
- -b 选项指定 ipt2socks 的 IPv4 监听地址。
- -B 选项指定 ipt2socks 的 IPv6 监听地址。
- -l 选项指定 ipt2socks 的透明代理监听端口。
- -j 选项指定 ipt2socks 的线程数,默认为 1。
- -n 选项设置 ipt2socks 进程的 nofile 限制值。
- -o 选项设置 ipt2socks 的 UDP 空闲超时(秒)。
- -c 选项设置 ipt2socks 的 UDP 缓存最大大小。
- -f 选项设置 ipt2socks 的 TCP 接收缓冲区大小。
- -u 选项设置 ipt2socks 的用户ID,
run_as_user。 - -G 选项指示 ipt2socks 优雅地关闭 TCP 代理连接对。
- -R 选项指示 ipt2socks 使用 REDIRECT 而非 TPROXY。
- -T 选项指示 ipt2socks 仅启用 TCP 透明代理监听端口。
- -U 选项指示 ipt2socks 仅启用 UDP 透明代理监听端口。
- -4 选项指示 ipt2socks 仅启用 IPv4 协议栈的透明代理。
- -6 选项指示 ipt2socks 仅启用 IPv6 协议栈的透明代理。
- -v 选项指示 ipt2socks 在运行期间打印详细的日志信息。
- -V 选项打印 ipt2socks 的版本号,然后退出 ipt2socks 进程。
- -h 选项打印 ipt2socks 的帮助信息,然后退出 ipt2socks 进程。
sudo setcap cap_net_bind_service,cap_net_admin+ep /usr/local/bin/ipt2socks- 如果以 root 用户启动 ipt2socks,也可以指定
-u nobody选项切换至nobody用户
----
ip2socks go version, utility for converting iptables(redirect/tproxy) to socks5.
ip2socks-go
$ ipt2socks-go --help // no help option and use long style please ... ~~~~
usage: ipt2socks <options...>. the existing options are as follows:
-s, --server-addr <addr> socks5 server ip address, <required>
-p, --server-port <port> socks5 server port number, <required>
-a, --auth-username <user> username for socks5 authentication
-k, --auth-password <passwd> password for socks5 authentication
-b, --listen-addr4 <addr> listen ipv4 address, default: 127.0.0.1
-B, --listen-addr6 <addr> listen ipv6 address, default: ::1
-l, --listen-port <port> listen port number, default: 60080
-j, --thread-nums <num> number of worker threads, default: 1
-n, --nofile-limit <num> set nofile limit, maybe need root priv
-o, --udp-timeout <sec> udp socket idle timeout, default: 300
-c, --cache-size <size> max size of udp lrucache, default: 256
-f, --buffer-size <size> buffer size of tcp socket, default: 8192
-u, --run-user <user> run the ipt2socks with the specified user
-G, --graceful gracefully close the tcp connection pair
-R, --redirect use redirect instead of tproxy (for tcp)
-T, --tcp-only listen tcp only, aka: disable udp proxy
-U, --udp-only listen udp only, aka: disable tcp proxy
-4, --ipv4-only listen ipv4 only, aka: disable ipv6 proxy
-6, --ipv6-only listen ipv6 only, aka: disable ipv4 proxy
-v, --verbose print verbose log, default: <disabled>
-V, --version print ipt2socks version number and exit
-h, --help print ipt2socks help information and exit
from https://github.com/lcdbin/ip2socks-go-----linux全局智能分流方案,也可用于路由器上.
介绍
这里有两种方案,都可以实现全局智能分流。第一种方案的思路是使用 ipset 载入 chnroute 的 IP 列表并使用 iptables 实现带自动分流国内外流量的全局代理。为什么不用 PAC 呢?因为 PAC 这种东西只对浏览器有用。难道你在浏览器之外就不需要科学上网了吗?反正我是不信的…… <br > 首先将本项目克隆到你的机器上,比如在/home/yang/目录下执行:
$ git clone https://github.com/yangchuansheng/turn-socks-to-vpn.git
方案一
安装相关软件(本教程为Archlinux平台)
- shadowsocks-libev
- ipset
$ pacman -S badvpn shadowsocks-libev ipset配置shadowsocks-libev(略过)
假设shadowsocks配置文件为/etc/shadowsocks1.json
获取中国IP段
保存在cn_rules.conf中
修改启动和关闭脚本
$ vim ss-up.sh#!/bin/bash
SOCKS_SERVER=$SERVER_IP # SOCKS 服务器的 IP 地址,改成你自己的服务器地址
# Setup the ipset
ipset -N chnroute hash:net maxelem 65536
for ip in $(cat '/home/yang/turn-socks-to-vpn/cn_rules.conf'); do
ipset add chnroute $ip
done
# 在nat表中新增一个链,名叫:SHADOWSOCKS
iptables -t nat -N SHADOWSOCKS
# Allow connection to the server
iptables -t nat -A SHADOWSOCKS -d $SOCKS_SERVER -j RETURN
# Allow connection to reserved networks
iptables -t nat -A SHADOWSOCKS -d 0.0.0.0/8 -j RETURN
iptables -t nat -A SHADOWSOCKS -d 10.0.0.0/8 -j RETURN
iptables -t nat -A SHADOWSOCKS -d 127.0.0.0/8 -j RETURN
iptables -t nat -A SHADOWSOCKS -d 169.254.0.0/16 -j RETURN
iptables -t nat -A SHADOWSOCKS -d 172.16.0.0/12 -j RETURN
iptables -t nat -A SHADOWSOCKS -d 192.168.0.0/16 -j RETURN
iptables -t nat -A SHADOWSOCKS -d 224.0.0.0/4 -j RETURN
iptables -t nat -A SHADOWSOCKS -d 240.0.0.0/4 -j RETURN
# Allow connection to chinese IPs
iptables -t nat -A SHADOWSOCKS -p tcp -m set --match-set chnroute dst -j RETURN
iptables -t nat -A SHADOWSOCKS -p icmp -m set --match-set chnroute dst -j RETURN
# Redirect to Shadowsocks
# 把1081改成你的shadowsocks本地端口
iptables -t nat -A SHADOWSOCKS -p tcp -j REDIRECT --to-port 1081
iptables -t nat -A SHADOWSOCKS -p icmp -j REDIRECT --to-port 1081
# 将SHADOWSOCKS链中所有的规则追加到OUTPUT链中
iptables -t nat -A OUTPUT -p tcp -j SHADOWSOCKS
iptables -t nat -A OUTPUT -p icmp -j SHADOWSOCKS这是在启动 shadowsocks 之前执行的脚本,用来设置 iptables 规则,对全局应用代理并将 chnroute 导入 ipset 来实现自动分流。注意要把服务器 IP 和本地端口相关的代码全部替换成你自己的。 这里就有一个坑了,就是在把 chnroute.txt 加入 ipset 的时候。因为 chnroute.txt 是一个 IP 段列表,而中国持有的 IP 数量上还是比较大的,所以如果使用 hash:ip 来导入的话会使内存溢出。我在第二次重新配置的时候就撞进了这个大坑…… 但是你也不能尝试把整个列表导入 iptables。虽然导入 iptables 不会导致内存溢出,但是 iptables 是线性查表,即使你全部导入进去,也会因为低下的性能而抓狂。 <br > ss-down.sh是用来清除上述规则的脚本,不用作任何修改 <br > 接着执行
$ chmod +x ss-up.sh
$ chmod +x ss-down.sh配置ss-redir服务
首先,默认的 ss-local 并不能用来作为 iptables 流量转发的目标,因为它是 socks5 代理而非透明代理。我们至少要把 systemd 执行的程序改成 ss-redir。其次,上述两个脚本还不能自动执行,必须让 systemd 分别在启动 shadowsocks 之前和关闭之后将脚本执行,这样才能自动配置好 iptables 规则。
$ vim /usr/lib/systemd/system/shadowsocks-libev@.service[Unit]
Description=Shadowsocks-Libev Client Service
After=network.target
[Service]
User=root
CapabilityBoundingSet=~CAP_SYS_ADMIN
ExecStart=
ExecStartPre=/home/yang/turn-socks-to-vpn/ss-up.sh
ExecStart=/usr/bin/ss-redir -u -c /etc/%i.json
ExecStopPost=/home/yang/turn-socks-to-vpn/ss-down.sh
[Install]
WantedBy=multi-user.target然后启动服务
$ systemctl start shadowsocks-libev@shadowsocks1开机自启
$ systemctl enable shadowsocks-libev@shadowsocks1六、配置ss-tunnel服务,用来提供本地DNS解析
$ vim /usr/lib/systemd/system/shadowsocks-libev-tunnel@.service[Unit]
Description=Shadowsocks-Libev Client Service Tunnel Mode
After=network.target
[Service]
Type=simple
User=nobody
CapabilityBoundingSet=CAP_NET_BIND_SERVICE
ExecStart=/usr/bin/ss-tunnel -c /etc/%i.json -l 53 -L 8.8.8.8:53 -u
[Install]
WantedBy=multi-user.target启动服务
$ systemctl start shadowsocks-libev-tunnel@shadowsocks1开机自启
$ systemctl enable shadowsocks-libev-tunnel@shadowsocks1配置系统 DNS 服务器设置
可参见 https://developers.google.com/speed/public-dns/docs/using 中 Changing your DNS servers settings 中 Linux 一节
图形界面以 GNOME 3 为例:
打开所有程序列表,并 -> 设置 – 硬件分类 – 网络
如果要对当前的网络配置进行编辑 -> 单击齿轮按钮
选中 IPv4
DNS 栏目中,将自动拨向关闭
在服务器中填入 127.0.0.1 (或103.214.195.99:7300)并应用
选中 IPv6
DNS 栏目中,将自动拨向关闭
在服务器中填入 ::1 并应用
请务必确保只填入这两个地址,填入其它地址可能会导致系统选择其它 DNS 服务器绕过程序的代理
重启网络连接
直接修改系统文件修改 DNS 服务器设置:
自动获取地址(DHCP)时:
以 root 权限进入 /etc/dhcp 或 /etc/dhcp3 目录(视乎 dhclient.conf 文件位置)
直接修改 dhclient.conf 文件,修改或添加 prepend domain-name-servers 一项即可
如果 prepend domain-name-servers 一项被 # 注释则需要把注释去掉以使配置生效,不需要添加新的条目
dhclient.conf 文件可能存在多个 prepend domain-name-servers 项,是各个网络接口的配置项目,直接修改总的配置项目即可
使用 service network(/networking) restart 或 ifdown/ifup 或 ifconfig stop/start 重启网络服务/网络端口
非自动获取地址(DHCP)时:
以 root 权限进入 /etc 目录
直接修改 resolv.conf 文件里的 nameserver 即可
如果重启后配置被覆盖,则需要修改或新建 /etc/resolvconf/resolv.conf.d 文件,内容和 resolv.conf 一样
使用 service network(/networking) restart 或 ifdown/ifup 或 ifconfig stop/start 重启网络服务/网络端口
打开流量转发
$ cat /etc/sysctl.d/30-ipforward.confnet.ipv4.ip_forward=1
net.ipv6.conf.all.forwarding = 1
net.ipv4.tcp_congestion_control=westwood
net.ipv4.tcp_syn_retries = 5
net.ipv4.tcp_synack_retries = 5编辑完成后,执行以下命令使变动立即生效
$ sysctl -p
方案一固然可以实现全局智能分流,可这里有一个问题,它并不能让连接到此电脑上的设备也实现智能分流,也就是说,它还不能当成一个翻墙路由器使用,下面我们介绍的方案二便可以解决这个问题。前面的步骤大致相似,到后面略有不同。
方案二
安装相关软件(本教程为Archlinux平台)
- badvpn
- pdnsd
- shadowsocks
$ pacman -S badvpn pdnsd shadowsocks配置shadowsocks(略过)
假设shadowsocks配置文件为/etc/shadowsocks1.json
获取中国IP段
保存在cn_rules.conf中
修改iptables启动和关闭脚本
$ vim sstunnel-up.sh#!/bin/bash
# 后面将会用ss-tunnel开启本地dns解析服务,所以将本地dns的udp请求转发到pdnsd的dns端口
# 至于为什么多此一举,而不直接将pdnsd的本地端口设置为53,是因为53端口已经被污染了,所以通过此方法来欺骗GFW
iptables -t nat -A OUTPUT -p udp --dport 53 -j DNAT --to 127.0.0.1:10053<br > sstunnel-down.sh是用来清除上述规则的脚本
#!/bin/bash
iptables -t nat -F OUTPUT配置pdnsd服务,用来提供本地DNS解析
将pdnsd.conf复制到/etc目录下,然后修改pdnsd.service
$ vim /usr/lib/systemd/system/pdnsd.service[Unit]
Description=proxy name server
Wants=network-online.target
After=network-online.target
[Service]
ExecStartPre=/home/yang/turn-socks-to-vpn/sstunnel-up.sh
ExecStart=/usr/bin/pdnsd
ExecStopPost=/home/yang/turn-socks-to-vpn/sstunnel-down.sh
[Install]
WantedBy=multi-user.target启动服务
$ systemctl start pdnsd开机自启
$ systemctl enable pdnsd配置系统 DNS 服务器设置
可参见 https://developers.google.com/speed/public-dns/docs/using 中 Changing your DNS servers settings 中 Linux 一节
图形界面以 GNOME 3 为例:
打开所有程序列表,并 -> 设置 – 硬件分类 – 网络
如果要对当前的网络配置进行编辑 -> 单击齿轮按钮
选中 IPv4
DNS 栏目中,将自动拨向关闭
在服务器中填入 127.0.0.1 (或103.214.195.99:7300)并应用
选中 IPv6
DNS 栏目中,将自动拨向关闭
在服务器中填入 ::1 并应用
请务必确保只填入这两个地址,填入其它地址可能会导致系统选择其它 DNS 服务器绕过程序的代理
重启网络连接
直接修改系统文件修改 DNS 服务器设置:
自动获取地址(DHCP)时:
以 root 权限进入 /etc/dhcp 或 /etc/dhcp3 目录(视乎 dhclient.conf 文件位置)
直接修改 dhclient.conf 文件,修改或添加 prepend domain-name-servers 一项即可
如果 prepend domain-name-servers 一项被 # 注释则需要把注释去掉以使配置生效,不需要添加新的条目
dhclient.conf 文件可能存在多个 prepend domain-name-servers 项,是各个网络接口的配置项目,直接修改总的配置项目即可
使用 service network(/networking) restart 或 ifdown/ifup 或 ifconfig stop/start 重启网络服务/网络端口
非自动获取地址(DHCP)时:
以 root 权限进入 /etc 目录
直接修改 resolv.conf 文件里的 nameserver 即可
如果重启后配置被覆盖,则需要修改或新建 /etc/resolvconf/resolv.conf.d 文件,内容和 resolv.conf 一样
使用 service network(/networking) restart 或 ifdown/ifup 或 ifconfig stop/start 重启网络服务/网络端口
修改路由表启动和终止脚本
将socksfwd复制到/usr/local/bin目录下,然后修改相关参数
$ vim /usr/local/bin/socksfwd#!/bin/bash
SOCKS_SERVER=$SERVER_IP # SOCKS 服务器的 IP 地址
SOCKS_PORT=1081 # 本地SOCKS 服务器的端口
GATEWAY_IP=172.16.68.254 # 家用网关(路由器)的 IP 地址
TUN_NETWORK_DEV=tun0 # 选一个不冲突的 tun 设备号
TUN_NETWORK_PREFIX=10.0.0 # 选一个不冲突的内网 IP 段的前缀
start_fwd() {
ip tuntap del dev "$TUN_NETWORK_DEV" mode tun
# 添加虚拟网卡
ip tuntap add dev "$TUN_NETWORK_DEV" mode tun
# 给虚拟网卡绑定IP地址
ip addr add "$TUN_NETWORK_PREFIX.1/24" dev "$TUN_NETWORK_DEV"
# 启动虚拟网卡
ip link set "$TUN_NETWORK_DEV" up
ip route del default via "$GATEWAY_IP"
ip route add "$SOCKS_SERVER" via "$GATEWAY_IP"
# 特殊ip段走家用网关(路由器)的 IP 地址(如局域网联机)
# ip route add "172.16.39.0/24" via "$GATEWAY_IP"
# 国内网段走家用网关(路由器)的 IP 地址
for i in $(cat /home/yang/turn-socks-to-vpn/cn_rules.conf)
do
ip route add "$i" via "$GATEWAY_IP"
done
# 将默认网关设为虚拟网卡的IP地址
ip route add 0.0.0.0/1 via "$TUN_NETWORK_PREFIX.1"
ip route add 128.0.0.0/1 via "$TUN_NETWORK_PREFIX.1"
# 将socks5转为vpn
badvpn-tun2socks --tundev "$TUN_NETWORK_DEV" --netif-ipaddr "$TUN_NETWORK_PREFIX.2" --netif-netmask 255.255.255.0 --socks-server-addr "127.0.0.1:$SOCKS_PORT"
TUN2SOCKS_PID="$!"
}
stop_fwd() {
ip route del 128.0.0.0/1 via "$TUN_NETWORK_PREFIX.1"
ip route del 0.0.0.0/1 via "$TUN_NETWORK_PREFIX.1"
for i in $(cat /home/yang/bin/路由表/cn_rules.conf)
do
ip route del "$i" via "$GATEWAY_IP"
done
ip route del "172.16.39.0/24" via "$GATEWAY_IP"
ip route del "$SOCKS_SERVER" via "$GATEWAY_IP"
ip route add default via "$GATEWAY_IP"
ip link set "$TUN_NETWORK_DEV" down
ip addr del "$TUN_NETWORK_PREFIX.1/24" dev "$TUN_NETWORK_DEV"
ip tuntap del dev "$TUN_NETWORK_DEV" mode tun
}
start_fwd
trap stop_fwd INT TERM
wait "$TUN2SOCKS_PID"<br > 将socksfwd.service复制到/usr/lib/systemd/system/目录下,然后启动服务
$ systemctl start socksfwd开机自启
$ systemctl enable socksfwd打开流量转发
将30-ipforward.conf复制到/etc/sysctl.d/目录下,然后执行以下命令使变动立即生效
$ sysctl -pfrom https://github.com/houzhenggang/turn-socks-to-vpn---https://guide.v2fly.org/app/transparent_proxy.htmlhttps://guide.v2fly.org/app/tproxy.html-------Introduction
This is a docker image for bypass transparent proxy of v2ray, using techniques in this article: https://guide.v2fly.org/app/tproxy.html
The image uses network namespace to isolate ip route and iptables settings and accelerate deployment.
It should be deployed on a device other than router, like Raspberry Pi or NAS, using Docker network that is attched (bridged) to host physical network, there are several choices:
- macvlan: easy to deploy, but due to the limitation of macvlan, the host itself cannot connect to the container, so it can't use the transparent proxy
- bridge to host: unfortunately, docker has a very poor support for bridging to host network, it's feasible, but very tricky
- host: Docker host network just doesn't create network namespace and the script in the image will pollute host network namespace without cleaning it up, so host network is not recommended
Deployment
Suppose the device IP address is 192.168.1.250, and the gateway is 192.168.1.254, the container's address will be 192.168.1.251.
First, create a macvlan:
docker network create -d macvlan \
--subnet=192.168.1.0/24 \
--ip-range=192.168.1.251/32 \
--gateway=192.168.1.254 \
-o parent=ens3 v2ray
Then start the container:
docker run -d \
--name=v2ray \
--privileged=true \
--network v2ray \
--env VMESS_SERVER=<VMESS_SERVER> \
--env VMESS_PORT=<VMESS_PORT> \
--env VMESS_ID=<VMESS_ID> \
--env NETWORK=192.168.1.0/24 \
--env ADDRESS=192.168.1.251/24 \
--env GATEWAY=192.168.1.254 \
core2duo/v2ray-bypass:200202
Testing
After the container is running, change the default route and DNS namespace to the container address in client:
ip route change default via 192.168.1.251
echo "nameserver 192.168.1.251" > /etc/resolve.conf
The client should work then.
Work with router
Use the container as a default route is not a good idea, as all the traffic will go through v2ray and bring extra performance pressure on it. The better way is to collaborate with the router, redirect the traffic to the proxy only when it's necessary.
The solution is to use dnsmasq and ipset.
You will need a dnsmasq configuration that indicates which domain will
use v2ray DNS and will be added into ipset, something like this:
server=/.google.com/192.168.1.251#53
ipset=/.google.com/gfwlist
See gfwlist2dnsmasq for a tool that can automatically generate the configuration.
Then on router, create the ipset if it doesn't exist.
ipset create gfwlist hash:ip
Use iptables to mark traffics to ip that is in the ipset and route them to the proxy:
ip rule add pref 10 fwmark 0xAA lookup 10
ip route add default via 192.168.1.251 table 10
iptables -t mangle -A PREROUTING -m set --match-set gfwlist dst -j MARK --set-mark 0xAA
Done, all devices connected to the router should be able to use the transparent proxy now.
from https://github.com/core2duoe6420/v2ray-tproxy
--------
Linux Transparent Proxy library for Golang.
Golang TProxy 


Golang TProxy provides an easy to use wrapper for the Linux Transparent Proxy functionality.
Transparent Proxy (TProxy for short) provides the ability to transparently proxy traffic through a userland program without the need for conntrack overhead caused by using NAT to force the traffic into the proxy.
Another feature of TProxy is the ability to connect to remote hosts using the same client information as
the original client making the connection. For example, if the connection 10.0.0.1:50073 -> 8.8.8.8:80 was
intercepted, the service could make a connection to 8.8.8.8:80 pretending to come from 10.0.0.1:50073.
The linux kernel and IPTables handle diverting the packets back into the proxy for those remote connections by matching incoming packets to any locally bound sockets with the same details.
This is done in three steps. (Please note, this is from my understanding of how it works, which may be wrong in some places, so please correct me if I have described something wrong)
Step 1 - Binding a listener socket with the IP_TRANSPARENT socket option
Preparing a socket to receive connections with TProxy is really no different than what is normally done when
setting up a socket to listen for connections. The only difference in the process is before the socket is bound,
the IP_TRANSPARENT socket option.
syscall.SetsockoptInt(fileDescriptor, syscall.SOL_IP, syscall.IP_TRANSPARENT, 1)Step 2 - Setting the IP_TRANSPARENT socket option on outbound connections
Same goes for making connections to a remote host pretending to be the client, the IP_TRANSPARENT socket
option is set and the Linux kernel will allow the bind so along as a connection was intercepted with those details
being used for the bind
Step 3 - Adding IPTables and routing rules to redirect traffic in both directions
Finally IPTables and routing rules need to be setup to tell Linux to redirect the desired traffic to the proxy application.
First make a new chain in the mangle table called DIVERT and add a rule to direct any TCP traffic with a matching
local socket to the DIVERT chain
iptables -t mangle -N DIVERT
iptables -t mangle -A PREROUTING -p tcp -m socket -j DIVERTThen in the DIVERT chain add rules to add routing mark of 1 to packets in the DIVERT chain and accept the packets
iptables -t mangle -A DIVERT -j MARK --set-mark 1
iptables -t mangle -A DIVERT -j ACCEPTAnd add routing rules to direct traffic with mark 1 to the local loopback device so the Linux kernal can pipe the
traffic into the existing socket.
ip rule add fwmark 1 lookup 100
ip route add local 0.0.0.0/0 dev lo table 100Finally add a IPTables rule to catch new traffic on any desired port and send it to the TProxy server
iptables -t mangle -A PREROUTING -p tcp --dport 80 -j TPROXY --tproxy-mark 0x1/0x1 --on-port 8080To test this out and see it work, try running the example in example/tproxy_example.go on a virtual machine and route
some traffic through it.
from https://github.com/LiamHaworth/go-tproxy