(编译方法:
Usage
phantomsocks
-c string
Config (default "default.conf")
-device string
Device
-dns string
DNS
-hosts string
Hosts
-log int
LogLevel
-pac string
PACServer
-sni string
SNIProxy
-socks string
Socks5
Configure
server=IP:Port #Domain in config will use this DNS(DNSoverTCP),if not set it will use the DNS of system
ipv6=true/false #Domain below will enable/disable IPv6
ttl=* #the fake tcp packet will use this TTL
domain=ip,ip,... #this domain will use these IPs
domain #this domain will be resolved by DNS
ip:port #this ip:port will send fake packet when creating connection
method=* #the methods to modify TCP
methods:
ttl #the fake tcp packets will use the TTL you set
w-md5 #the fake tcp packets will have a wrong md5 option
w-csum #the fake tcp packets will have a wrong checksum
w-ack #the fake tcp packets will have a wrong ACK number
tfo #SYN packet will take a part of data when the server supports TCP Fast Open
https #the domain below will be move to https when using http on port 80
Installation
pcap version
go build phantomsocks.go
go build -ldflags '-extldflags "-static"' phantomsocks.go
raw socket version
env GOOS=linux GOARCH=mipsle go build phantomsocks.go
cross & static compile on Ubuntu 18.04
apt-get install git autoconf automake bison build-essential flex gawk gettext gperf libtool pkg-config libpcap-dev
cd ~/Downloads
wget https://downloads.openwrt.org/releases/19.07.2/targets/ramips/mt7621/openwrt-sdk-19.07.2-ramips-mt7621_gcc-7.5.0_musl.Linux-x86_64.tar.xz
tar -xJvf openwrt-sdk-19.07.2-ramips-mt7621_gcc-7.5.0_musl.Linux-x86_64.tar.xz
export PATH=$PATH:~/Downloads/openwrt-sdk-19.07.2-ramips-mt7621_gcc-7.5.0_musl.Linux-x86_64/staging_dir/toolchain-mipsel_24kc_gcc-7.5.0_musl/bin: && export STAGING_DIR=~/Downloads/openwrt-sdk-19.07.2-ramips-mt7621_gcc-7.5.0_musl.Linux-x86_64/staging_dir/toolchain-mipsel_24kc_gcc-7.5.0_musl
wget https://www.tcpdump.org/release/libpcap-1.9.1.tar.gz
tar -xzvf libpcap-1.9.1.tar.gz
cd libpcap-1.9.1
./configure --host=mipsel-openwrt-linux-musl --prefix='~/Downloads/openwrt-sdk-19.07.2-ramips-mt7621_gcc-7.5.0_musl.Linux-x86_64/staging_dir/toolchain-mipsel_24kc_gcc-7.5.0_musl'
make && make install
cd ~/go/src/github.com/Macronut/phantomsocks
env GOOS=linux GOARCH=mipsle CGO_ENABLED=1 CC='~/Downloads/openwrt-sdk-19.07.2-ramips-mt7621_gcc-7.5.0_musl.Linux-x86_64/staging_dir/toolchain-mipsel_24kc_gcc-7.5.0_musl/bin/mipsel-openwrt-linux-gcc' go build -ldflags '-extldflags "-static"' phantomsocks.go原理
技术背景
TLS 握手时会发送 SNI(可以理解为域名),用于帮助单 IP 多站点的服务器实现 HTTPS。但加密型 SNI(如 ESNI 和 ECH)尚未普及,且防火墙会直接对此采取 TCP RST 阻断措施,所以目前 SNI 都是明文形式。
明文 SNI 会暴露你访问的网站域名,因此防火墙采取域名黑名单机制便可以屏蔽对应网站,较少直接屏蔽 IP。
传统的解决方案,便是利用正常的服务器进行中转传输。
新思路实现
PhantomSocks 利用 WinDivert(Windows)、Pcap、RawSocket(Linux) 修改 TCP 帧,伪造部分帧参数。修改后的 TCP 帧不合常理,会使大部分防火墙的审查功能紊乱,无法正常进行 SNI 检测,也就不会发出 RST 阻断连接。
概括来说,可以突破被 DNS 污染的网站。
等等,这不是修改 TCP 帧吗?应该通用性很强吧?实则不然,TCP 阻断只是众多封禁方法的一种,这些情况不适用:
- 其他传输层协议。如 UDP 丢弃,DCCP QoS 等。
- 基于 TCP 的顶层协议审查。如应用层的 HTTP 明文检测,后续传输依然会被 RST 阻断。
- 底层协议封锁。如网络层 IP 黑名单,除非找到可用的 IP。
更多技术细节见论文:https://conferences.sigcomm.org/imc/2017/papers/imc17-final59.pdf
使用说明
1. 下载安装 PhantomSocks
全平台版本
https://github.com/Macronut/phantomsocks
对外提供一个无加密 & 可选认证的代理接口(Socks5、HTTP、SS)供其他软件连接使用,或 Redirect 重定向所有流量。
编译安装:go get github.com/macronut/phantomsocks
默认是 Pcap 模式,RawSocket 和 Windivert 模式的编译及跨平台交叉编译请参见 README,本文不再赘述。
Windows 衍生版(TCPioneer)
https://github.com/Macronut/TCPioneer
直接接管网卡,全局代理。Releases 中有预编译程序。
2. 配置 PhantomSocks
参数讲解
配置文件看起来有点复杂,不过简单总结只要注意几点:
- DNS 解析服务器。用于解析网站 IP。
- 网站的 IP 地址,类似 hosts。对于某些大范围 IP 封锁的网站,需要手动指定可用的 IP 地址,而不能依赖 DNS 服务器返回的结果
- TCP 帧修改及发送策略。不同网站由于采用的服务器技术不同,对各种修改后的 TCP 帧的适应性也不同。需要调整到可迷惑防火墙但目标服务器可正确识别的形式。
【知识点】TCP 协议帧头结构
Source port | 源端口
Destination port | 目标端口
Sequence number | 帧序号
Acknowledgment number | 应答号
Data offset | 偏移量
Reserved | 保留备用
Flags x 9 | 9个标志
Window size | 窗口大小
Checksum | 校验和
Urgent pointer | 紧急指针为了能正常传输 TCP 帧,有一些帧参数是不可修改的。PhantomSocks 可伪造的 TCP 帧参数包括:
- SEQ number 帧序号
- ACK number 应答号
- Checksum 校验和
- Urgent pointer 中的 timestamp 时间戳
- Flags 标志中的 SYN 标志(可选,用于 TCP 快速开启,0-RTT)
- Destination port 目标端口(可选,仅用于传输层的 HTTP 80 重定向 HTTPS 443)
- MD5(准确的说属于报文段结构,非帧结构)
同时为了保证网络层能正确转发 IP 数据包,PhantomSocks 还可以同时修改 IP 包:
- TTL 生存时间
- Destination IP 及 Version(可选,仅用于强制 IPv4 或强制 IPv6)
配置实战
大多数网站只需要伪造帧序号便可顺利突破防火墙。具体需要根据目标服务器调试。
这里提供一段我标注了注释的配置文件作为参考,更多参数详见项目 README。
# 日志等级
log=5
# TCP 帧伪造方法。伪造 MD5 校验。
method=w-md5
# 指定 DNS 解析服务器,用于解析未手动提供 IP 的域名
server=tls://1.0.0.1:853
# 重置 TCP 帧伪造方法,本行以后的域名生效。更正为伪造 MD5 校验、伪造帧序号、开启强制 HTTPS
method=w-md5,s-seg,https
# 指定相关域名未封禁的 IP
google.com=172.253.114.90,172.217.203.90,172.253.112.90,142.250.4.90,142.250.9.90,172.253.116.90,142.250.97.90,142.250.30.90,142.250.111.90,172.217.215.90,142.250.11.90,142.251.9.90,108.177.122.90,142.250.96.90,142.250.100.90,142.250.110.90,172.217.214.90,172.217.222.90,142.250.31.90,142.250.126.90,142.250.10.90,172.217.195.90,172.253.115.90,142.251.5.90,142.250.136.90,142.250.12.90,142.250.101.90,172.217.192.90,142.250.0.90,142.250.107.90,172.217.204.90,142.250.28.90,142.250.125.90,172.253.124.90,142.250.8.90,142.250.128.90,142.250.112.90,142.250.27.90,142.250.105.90,172.253.126.90,172.253.123.90,172.253.122.90,172.253.62.90,142.250.98.90
# 下列子域及泛解析皆使用上述未封禁 IP
ajax.googleapis.com=[google.com]
.google.com=[google.com]
.google.com.hk=[google.com]
.googleusercontent.com=[google.com]
.ytimg.com=[google.com]
.ggpht.com=[google.com]
.gstatic.com=[google.com]
.translate.goog=[google.com]
blogspot.com=[google.com]
.blogspot.com=[google.com]
# 某些域难以找到未封禁 IPv4,则可以用 SNI 代理中转(龟速)
sniproxy=78.129.226.64,43.255.113.231,43.255.113.229,178.255.46.176,67.222.65.2,69.162.113.194,204.12.225.226,87.117.205.40,69.162.113.198,69.28.83.244,5.152.185.10,213.183.56.23,69.28.82.253,178.209.51.200,78.129.226.113,31.200.241.28
dns.google=[sniproxy]
.googlevideo.com=[sniproxy]
# 本地有 IPV6 的话亦可以强制走 IPv6。不手动提供 SNI 代理和 IP,将由 DNS 提供 IPv6
# ipv6=true
# .googlevideo.com3. 启动 PhantomSocks
全平台版本
使用命令运行,需要指定对外代理端口,部分设备还需要指定出口网卡。
Linux(pcap&rawsocket):
sudo ./phantomsocks -device eth0 -socks 0.0.0.0:1080
Windows(windivert):
phantomsocks -socks 0.0.0.0:1080
macOS:
./phantomsocks -device en0 -socks 127.0.0.1:1080 -proxy socks://127.0.0.1:1080或者重定向网卡流量,Linux 要先用 iptables 重定向。
Linux(pcap&rawsocket):
iptables -t nat -A OUTPUT -d 6.0.0.0/8 -p tcp -j REDIRECT --to-port 6
./phantomsocks -device eth0 -dns :53 -redir :6
Windows(windivert):
./phantomsocks -redir 0.0.0.0:6 -proxy redirect://0.0.0.0:6Windows 衍生版(TCPioneer)
直接以管理员权限运行可执行文件,或者使用预置 bat 写入系统服务。
其他事项
安全性
防火墙放行后,实际为本机直连目标网站服务器 IP,防火墙日志必定会留下痕迹,所以需要承担风险。
稳定性
直连线路质量决定实际体验。大多数被屏蔽的网站和本地线路的直连效果由多方面因素决定,一般丢包率感人(主要原因是出口汇聚层拥堵,这真不是防火墙的锅,有空再写文详细介绍)
另外,防火墙可能会改进对 TCP 帧的审查方式(这不是什么难事),如果未来防火墙不受 PhantomSocks 的伪造干扰,这种方案自然也就失效了。
-----------------------------
TCPioneer & phantomsocks
原理很接近早年的西厢计划。与上述通过修改SNI信息来解决阻断的方法不同,这是通过魔改TCP包从而使GFW无法正常进行监测的神奇工具。
由于并未对SNI信息进行修改,因此甚至可以直连那些使用了CDN加速的网站,可以说是本文所列出的工具中最强大的一款,使用起来也非常简便。
参考阅读:
Your state is not mine: a closer look at evading stateful internet censorship
----------------------
Your State is Not Mine
你的状态不是我的
A Closer Look at Evading Stateful Internet CensorshipPermission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page.
Copyrights for components of this work owned by others than ACM must be honored.
Abstracting with credit is permitted.
To copy otherwise, or republish, to post on servers or to redistribute
to lists, requires prior specific permission and/or a fee. Request
permissions from permissions@acm.org.
IMC ’17, November 1–3, 2017, London, UK
© 2017 Association for Computing Machinery.
ACM ISBN 978-1-4503-5118-8/17/11. . . $15.00
https://doi.org/10.1145/3131365.3131374
1 INTRODUCTION如今,互联网审查和监控十分普遍。国家级的审查系统,如 NSA 的 PRISM 和中国的防火长城(GFW),具有实时分析全国 TB 级流量的能力。
带有明文的协议(如HTTP、DNS、IMAP),可以直接受到审查者的监控和操纵1、2、5、14、20、29,而带有加密的协议(如SSH、TLS/SSL、PPTP/MPPE)和Tor,可以通过流量指纹识别,从而在IP层面进行封堵13、31。
这些审查系统背后的关键技术是深度包检测(DPI)27,它也驱动着网络入侵检测系统(NIDS)。如前所述,大多数审查 NIDS 都部署在骨干网和边界路由器的 「旁路」 27,29,34。
为了检查应用级的载荷,DPI 技术必须正确实现 TCP 等底层协议,TCP 是当今互联网的基石。
Ptacek等人23已经证明,任何 NIDS 本质上都无法始终以与其端点相同的方式重建TCP流。
其根本原因是TCP(可能还有其他)协议在终端主机和 NIDS 的实现之间存在差异。即使NIDS完美地镜像了某一特定TCP实现的实现,它在处理由另一TCP实现产生的数据包流时仍可能出现问题。
由于数据包处理中的这种模糊性,发送方有可能发送精心制作的数据包,使NIDS维护的TCP控制块(TCB)与接收方的TCB脱同步。在某些情况下,NIDS甚至可以被欺骗来完全停用TCB(例如,在收到一个虚假的RST数据包后),有效地允许对手 "操纵" NIDS上的TCB。审查监控器也存在同样的基本缺陷--如果审查监控器上的TCB可以成功地与服务器上的TCB解除同步,那么客户端就可以逃避审查。与VPN、Tor和Telex32等其他依赖额外网络基础设施(如代理节点)27的审查规避技术不同,基于TCB操纵的规避技术只需要在客户端制作/操纵数据包,并有可能帮助所有基于TCP的应用层协议 "不被发现"。基于这一思想,Khattak等人17通过研究GFW在TCP层和HTTP层的行为,探讨了几种针对GFW的实用规避技术。西厢计划25提供了一个实用的工具,实现了一些规避策略,但从2011年开始就停止了开发,遗憾的是在我们的测量研究中没有发现这些的任何一种策略是有效的。除了我们这些尝试之外,没有新的报告,显示这些规避技术仍然工作。
在这项工作中,我们广泛评估了针对GFW的TCP层审查规避技术。通过在中国9个城市(和3个ISP)的11个观测点进行测试,我们能够覆盖各种网络路径,这些路径可能包括不同类型的GFW设备和中间盒(详见§3.3)。我们测量了 TCB 操纵如何帮助 HTTP、DNS 和 Tor 躲避 GFW。
首先,我们衡量了现有的审查规避策略在实践中的工作情况。有趣的是,我们发现,由于意外的网络条件、网络中间盒的干扰,或者更重要的是,GFW的新更新(与之前考虑的模型不同),它们中的大多数不再能很好地工作。这些初步的测量结果促使我们构建探测测试来推断
"新 "更新的GFW模型。最后,基于新的GFW模型和在部署 TCP 层审查回避的其他实际挑战方面的经验教训,我们开发了一套新的回避策略。
我们的测量结果表明,新策略的规避成功率在90%以上。我们还评估了这些新策略如何帮助 HTTP、DNS、Tor 和 VPN 规避 GFW。
此外,在我们的测量研究过程中,我们设计并实现了一个反审查工具 INTANG,整合了本文所考虑的所有审查规避策略。INTANG 很容易扩展,以纳入额外的策略。它不需要任何配置,并在后台运行,以帮助正常流量逃避审查。我们计划将该工具开源,以支持未来这一方向的研究。
我们将我们的贡献总结如下。
- 我们对GFW的行为进行了迄今为止最大规模的测量研究 用TCP层审查规避技术。
- 我们证明了现有的策略要么无效,要么在实践中受到限制。
- 我们在测量结果的基础上开发了一个更新的、更全面的 GFW 模型。
- 我们提出了新的、由测量驱动的策略,可以绕过新模型。
- 我们测量了我们改进的策略在 HTTP、DNS、VPN 和 Tor 的审查规避方面的成功率。结果显示出非常高的成功率(> 90 %)。
- 我们开发了一个开源工具来自动测量 GFW 的响应能力,并用于规避审查。该工具可作为一个框架进行扩展,以整合未来研究中可能出现的其他规避策略。
2 背景
在本节中,我们将提供 GFW 采用的基于 DPI 的审查技术的背景,并讨论之前提出的规避策略。
2.1 旁路审查系统
旁路(on-path)检查器监听路由器,实时复制数据包并执行分析。网关(in-path)检查器将设备置于路由的一部分在将流量传到下一跳之前分析流量。旁路检查器只能读取和注入数据包。网关检查器除此之外还可以丢弃和修改数据包。对于旁路系统,没有处理时间的限制,因此可以进行更复杂的分析。对于网关系统,需要避免导致数据包延迟的繁重分析。大型审查系统,比如 GFW,多部署「旁路」设计,以确保极高的吞吐量。
为了用 DPI 检查应用层的内容,像 GFW 这样的审查系统首先需要从数据包中重新组合 TCP 流。据报道 17,GFW有一个简化的 TCP 实现,用于重构 TCP 数据流,并将其传递给上层做进一步分析。GFW能够分析多种应用协议(如 HTTP、DNS、IMAP),并能应用其基于规则的检测引擎来检测敏感的应用内容。
TCP连接重置 是一种通用的审查技术。
由于GFW的「旁路」性质,它不能丢弃一对终端主机之间的「非法」的数据包。相反,它可以注入数据包来强制关闭连接,或破坏连接的建立。一旦检测到任何敏感内容,GFW就会向相应的客户端和服务器注入RST(type-1)和
RST/ACK(type-2)数据包,以中断正在进行的连接,并将中断维持一定的时间(根据我们的测量,为90秒)。在此期间,两端主机之间的任何SYN数据包都会触发GFW发出的序列号错误的伪造SYN/ACK数据包,阻碍合法的握手;其他数据包都会触发伪造的RST和RST/ACK数据包,撕毁连接。
根据以前的工作 3,25 和我们的测量结果,RST(type-1) 和 RST/ACK (type-2) 很可能来自于两种类型的GFW实例,它们通常同时部署。
我们遇到了一些type-1或type-2重置单独发生的情况;因此,我们能够分别测量它们的特征。
type-1重置包只有 RST flag 设置,以及随机的 TTL 值和 window size,而type-2重置包则有 RST/ACK flag 设置,以及周期性增加的 TTL 值和 window size 。
一旦检测到敏感关键字,GFW 会发送一个type-1 RST和三个type-2 RST/ACK,sequence 分别为 X、X+1460 和 X+4380(X为当前服务器端 sequence)。
一个完整的 TCP 数据包的常见大小是 1460 字节。有时,注入的数据包可能会落后于服务器的响应,从而变得过时而被丢弃。 GFW 发送带有增加 sequence 的数据包可以在很大程度上抵消这种影响。
请注意,在随后 90 秒的阻塞期间,只有 type-2 重置伪造了 SYN/ACK 数据包;此外,当我们将一个HTTP请求分成两个TCP数据包时,只有 type-2 重置出现。从以上所有情况来看,我们推测 type-2 重置是来自更新的GFW实例或设备。
众多的研究都集中在 GFW 的 TCP连接重置 上。Xu 等人 34 进行测量以确定注入 RST 数据包的审查设备的位置。Crandall 等人 11 采用潜在语义分析来自动生成最新的审查关键词列表。Park 等人 20 测量了 RST 数据包注入对HTTP Request 和 Response 的关键词过滤的有效性,并深入了解了为什么对 HTTP Response 的过滤已经停止。执行TCP连接重置确实存在不足之处。例如,要跟踪每一个连接的 TCP 状态,并针对大量的 TCP 数据包匹配关键字,成本很高。此外,它也不能完全抵御规避方案。
DNS 污染 是 GFW 使用的另一种常用技术 4 ,5 ,19。GFW 会对 UDP 和 TCP 的 DNS 请求进行审查。
对于带有黑名单域名的 UDP DNS 请求,它只需注入一个假的 DNS Response;对于 TCP DNS 请求,它转向连接重置机制。我们的测量也涵盖了 DNS over TCP。
2.2 规避NIDS和审查系统
Ptacek等23系统地研究了NIDS在构建和维护TCP状态的方式上存在的漏洞。特别是,NIDS 为每个实时连接维护一个TCP控制块(TCB),以跟踪其状态信息(如 TCP状态、序列号、确认号等)。其目标是复制存在于两个端点的相同的完全连接信息。然而,在实践中,由于以下因素,这是非常具有挑战性的。
- 主机信息的多样性。由于 TCP 标准的模糊性和不断更新,不同的操作系统实现在处理 TCP
数据包时可能有非常不同的行为。例如,当遇到意外的 TCP flag 组合时,不同的操作系统可能会有不同的行为(因为标准中仍然没有规定如何处理这些
flag)。另一个例子是,RST 数据包的处理在不同的 TCP 标准中发生了巨大的变化。
(RFC 793 至 RFC 5961)。 - 网络信息的多样性。一个 NIDS 通常无法学习 网络拓扑结构与其保护的端点有关。因为拓扑结构本身可能会随着时间而改变。对于一个局域网来说,一个 NIDS 可以探究和维护拓扑结构。然而,对于监控整个互联网的审查系统,不说不可能,至少是很困难的。此外,这样一个系统将不知道网络故障或数据包丢失。因此,它无法准确判断数据包是否已经到达其目的地。
- 中间盒的存在。NIDS 通常不知道任何一对通信端点之间可能遇到的其他中间盒。这些中间盒可能会在NIDS处理数据包后丢弃甚至改变数据包,这使得预判接收者的行为更加困难。
这一观察促使人们对TCP重置攻击规避进行了研究。例如,Khattak等人17手动制作了一套相当全面的针对 GFW 的 TCP 层和HTTP层的规避策略,并在固定客户端和服务器的有限环境下成功验证了这些策略。遗憾的是,有大量的因素没有考虑到(例如,在不同的网络路径上可能会遇到不同类型的 GFW 设备,各种中间盒可能会会丢弃制作好的数据包)。
3 测量现有的规避策略
基于 Ptacek 等人23概述的 NIDS 的基本局限性、Khattak 等人17对 GFW 的建模以及西厢计划25的实施,我们将基于TCB操纵的审查规避策略分为三个高级类别,即
- TCB Creation
- Data Reassembly
- TCB Teardown
在本节中,我们基于目前已知的 GFW 模型,在这些类别中进行了深入的测量,以评估现有的逃避策略的有效性。
3.1 威胁模型
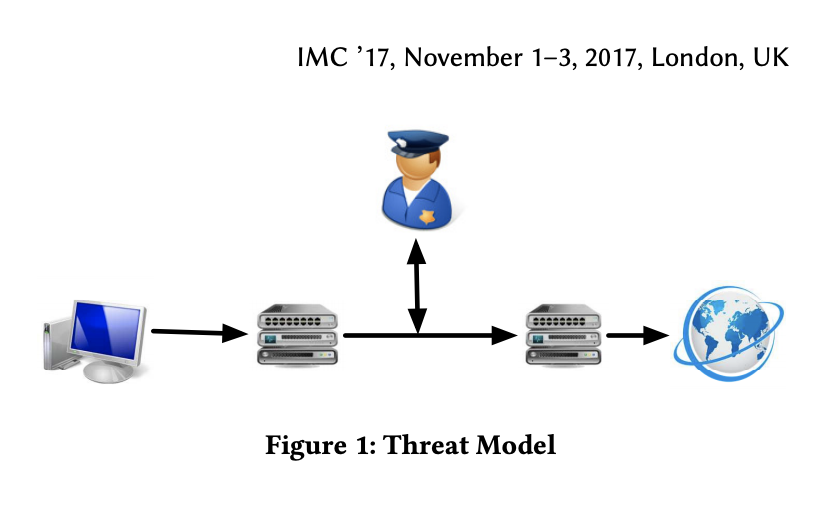
图1描述了威胁模型。客户端发起与服务器的TCP连接。GFW 通过创建 TCB 建立镜像连接,并可以从原连接中读取和注入数据包。
同时,路径上可能存在网络中间盒。我们将客户端与 GFW 之间的中间盒称为客户端中间盒,将 GFW 与服务器之间的中间盒称为服务器端中间盒。
3.2 现有的规避策略
目前逃避策略(如下文所列)的目标是通过发送特制的数据包,特别是 "插入" 数据包,使 GFW 和服务器进入不同的状态(即 desync)。
这些插入数据包的制作方式是,目的服务器忽略这些数据包(或从未到达服务器),但GFW接受并处理这些数据包。
TCB Creation
按照之前的工作17,GFW在看到 SYN packet 后会创建一个 TCB。因此客户端可以先发送一个带有假/错 sequence 的 SYN 插入包,在GFW上创建一个假的 TCB ,然后建立真正的连接。
GFW 会因为其 "意外" 的 sequence 而忽略真正的连接。
控制插入数据包中的 TTL 或 checksum,以防止服务器接受第一个注入的 SYN。
TTL 值较低的 packet 将永远不会到达目标服务器(但是可以到达 GFW),而 checksum 错误的packet 将被服务器丢弃。
Data Reassembly
数据重组策略有两种情况。
- 失序的数据重叠。
不同的 TCP 实现对重叠的失序数据片段有不同的处理方式。
以往的工作17表明,如果GFW遇到两个 offset 和 length 都相同的失序 IP fragment,它会优先选择(记录)前者,而丢弃后者。然而,对于具有相同 sequence 和 length 的失序 TCP fragemnt,它更倾向于后者(详见17)。
这种关于 IP fragment 的特性可以被利用,具体如下。首先,在有效载荷中故意留下一个空隙,然后发送一个 sequence 为X,length 为Y,包含随机垃圾数据的片段。随后,发送 offset 为 X、长度为 Y、包含敏感关键字的真实数据来躲避 GFW(因为预计 GFW 会选择前一个数据包)。最后通过发送 offset 为0、length 为 X 的真实数据来填补空缺。要利用 GFW 对 TCP fragment 的特性,我们只需调换垃圾数据和真实数据的顺序。 - 顺序内数据重叠。
当两个携带IP或TCP碎片的内序数据包到达时,GFW和服务器都会接受第一个携带特定碎片(由偏移量/序列号指定)的顺序数据包。然后,我们可以制作包含垃圾数据的插入包,以填充GFW的接收缓冲区,同时使它们被服务器忽略。例如,可以制作一个TTL较小或校验和错误的插入数据包;这样的数据包要么从未到达服务器,要么被服务器丢弃,但被GFW接受和处理。
TCB Teardown
按照已知的模型,当 GFW 看到 RST、RST/ACK 或 FIN 数据包时,它将撕毁它所维护的TCB。
人们可以制作这样的数据包来引起 TCB 撕毁,同时操纵 TTL 或 checksum 等字段来确保服务器上的连接不受影响。
3.3 实验设置
我们在中国采用了11个观测点,分布在9个不同的城市(北京、上海、广州、深圳、杭州、天津、青岛、张家口、石家庄),横跨3个ISP。
其中9家使用云服务提供商(阿里云 和 Qcloud),另外两家使用家庭网络(中国联通)。服务器选自 Alexa 全球顶级网站。我们首先过滤掉受 IP 屏蔽、DNS 中毒影响或位于中国境内的网站。我们排除了默认使用 HTTPS 的网站,原因有二。
第一,HTTPS 流量目前没有被GFW审查,因此,我们已经可以自由访问这些网站,不需要使用任何反审查技术。(译者: 目前 GFW 会检查 TLS 扩展 SNI 的,它们是 plaintext )
第二,如果我们使用 HTTP 访问这些 HTTPS 网站,它们会发送 HTTP 301 响应,将我们重定向到 HTTPS,敏感关键词会被复制到响应的 Header 的 Location 部分。
我们发现,一些路径上的 GFW 设备其实会检测到 Response 数据包中的敏感词。
这与20中测得的 HTML Response 审查类似。
此外,假设部署在特定自治系统(AS)中的 GFW 设备通常是相同的类型和版本,并且配置了相同的策略,我们只从每个AS中选择一个IP,以便通过跨越大量的AS集来实现实验的多样化。
通过应用基于上述规则的过滤器,并删除一些速度慢或反应迟钝的网站,我们最终获得了一个由77个网站组成的数据集(来自考虑的 77 个 AS ),Alexa 排名在 41 到 2091 之间。
我们手动验证这些网站是可以访问的(在中国以外),并且在 HTTP 请求中包含敏感关键词(即 ultrasurf)时受到 GFW 的 TCP 连接重置的影响。对于每个策略和网站,我们重复测试50次,并找出平均值。由于 GFW 会在检测到任何敏感关键字后将一对主机列入黑名单90秒,所以我们在必要时增加测试之间的间隔时间。
3.4 结果
我们在2017年4月和5月期间衡量了现有战略在躲避GFW方面的有效性。结果汇总于
表1.
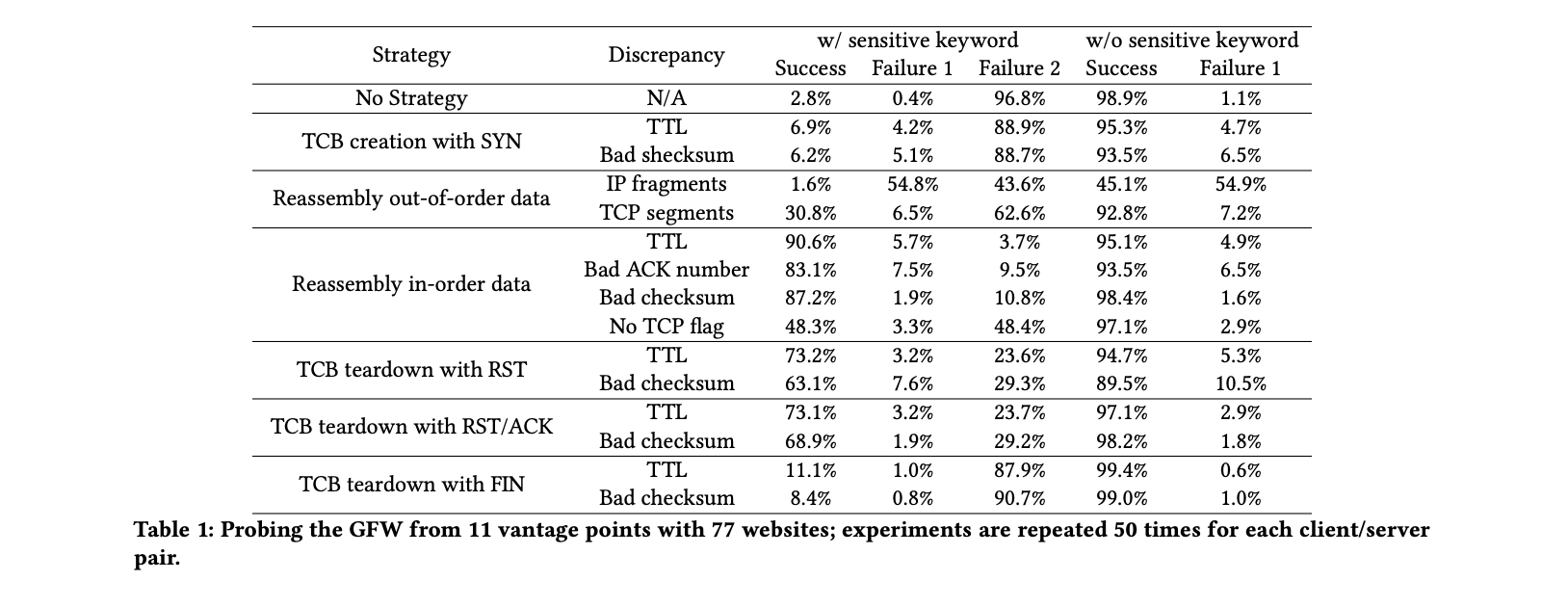
注意:我们在表1中使用了以下符号:Success 意味着我们收到了来自服务器的HTTP响应,并且没有收到来自 GFW 的重置包。失败1表示我们没有收到来自服务器的 HTTP 响应,也没有收到来自 GFW 的任何重置数据包。失败2表示我们收到 GFW 的重置包,即RST(类型1)或RST/ACK(类型2)。
我们的发现总结如下:
- 可能是由于GFW的过载,即使我们不使用任何回避策略,检索敏感内容的成功率仍然有2.8%。有趣的是,这种行为在2007年11首次被记录下来,并且一直持续到现在。
- 用 SYN 创建 TCB 一般是行不通的,而且有很高的 "失败2 "率(约89%)。
- 关于数据重构,我们发现(a)无序数据重构策略的 "失败1 "和 "失败2 "率都很高,但(b)发送无序数据来预填GFW的缓冲区,成功率要高得多(一般>80%)。
- 用 FIN 撕毁 TCB 遇到了高的 "失败2 "率,而用 RST 或者 RST/ACK 撕毁 TCB 遇到了约70%的成功率,但有 25% 的机会触发 GFW 的重置数据包。
GFW的进化
我们认为,许多现有策略的高失败率的主要原因是因为之前工作17中假设的GFW模型不再有效。
我们推迟详细讨论该模型是如何演变的到下一节,同时在这里指出:"checksum" 字段仍未被 GFW 验证,即一个有错误 checksum 的数据包,仍然是一个很好的插入数据包(GFW 认为它是有效的并更新它的 TCB,但服务器会丢弃它),如果不考虑中间盒。关于这些策略失败的其他原因,我们将结果摊开,分析如下:
客户端中间盒对实验的干扰
客户端侧的中间盒可能会丢弃我们的注入包。我们修改了一些字段(比如校验值,TCP flag)来使服务端丢弃它们,同样可能影响到客户端中间盒。因此策略失效,导致“失败2”。
另一方面,部署在网络客户端的一些 NAT 或状态/sequence 检查防火墙可能会拦截并接收插入的数据包,并改变其维护的连接状态。在这种情况下,以后的数据包将无法通过这些中间盒,导致 "失败1"。例如,如果一个RST数据包在它穿越的客户端中间盒上撕毁了连接,中间盒就会阻塞该连接上以后的数据包。
一些客户端中间盒可能会丢弃IP碎片(wrt数据重组策略),并导致 "失败1"。另一些则会将其缓冲并重新组合成一个完整的IP数据包,这可能会导致 "失败2",这取决于中间盒的实现。
我们从所有11个有利位置探查了客户端的中间盒,试图与自己的服务器连接。如表2所示,
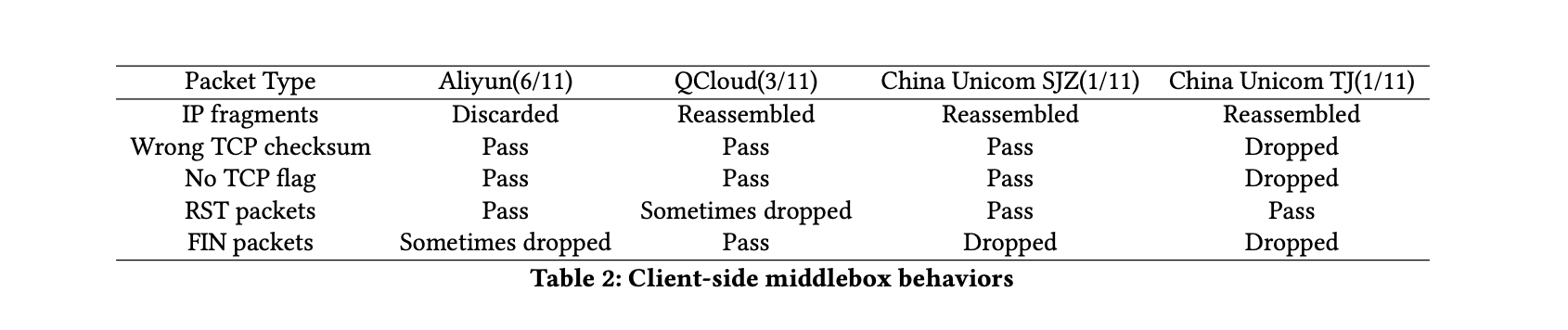
我们发现使用阿里云的6个客户端都无法发送 IP fragment。我们可以在合理的范围内得出结论,阿里云已经将自己的中间盒配置为丢弃某类 IP fragment。我们发现,其他5个节点的连接遇到客户端中间盒,中间盒会将 IP fragment 重新组合成一个完整的 IP 包,其中包含原始的HTTP请求;因此这些数据包被GFW确定性地捕获。由于我们发现大部分的路由器和/或中间盒都会干扰IP层的操纵,因此我们认为这并不像 TCP 层修改那样普遍适用于逃避。
天津中国联通的观测点有客户端的中间盒,会丢弃错误的 TCP checksum 或包含不含 TCP flag 的数据包;因此这两个策略在这一点上不起作用。最后,我们发现阿里云有时会丢弃FIN插入包,QCloud有时会丢弃 RST 插入包。石家庄和天津(中国联通)的客户端都有客户端中间盒,会丢弃FIN插入包。
服务端中间盒对实验的干扰
服务器端中间盒只影响服务器而不影响GFW。
我们的插入数据包可能会终止连接或改变服务器端中间盒的连接状态,导致后面的数据包被中间盒阻断。这将导致
"失败1"。为了验证服务器端中间盒的干扰,我们需要控制服务器或者在这些中间盒后面的同一路径上设置自己的服务器,这对于我们所有的目标,即Alexa的顶级网站来说,实际上是不可行的。
其他的失败原因
观察到这两种类型的故障可能还有一些其他原因。网络或服务器故障虽然罕见,但也可能发生。我们对故障案例进行了微观研究,并将我们观察到的案例列举如下。
- 服务器实现的差异。
我们发现,在一些服务器实现下(例如,3.8之前的Linux版本),在 "无序数据重叠策略 "下,携带无TCP标志的数据包有时可以被服务器接受,从而导致 "故障1"。
在 "无序数据重叠策略 "下,服务器可能会接受垃圾数据(就像GFW一样)并丢弃正确的数据包。 - 网络变化。
由于路由是动态的,可能会发生意想不到的变化,插入数据包中用于防止它们到达服务器的TTL值可能不正确。因此,它们可能仍会到达服务器并中断连接(失败1)。在其他情况下,插入数据包可能无法到达 GFW 并导致 "失败2"。我们还发现,网络上的数据包丢失可能会影响插入数据包,导致 "失败2"。我们通过以20ms的间隔重复发送三次插入包来应对这种动态。
总结
我们的测量使用真实的网络服务器,而不是由我们控制的服务器,以模拟日常网页浏览的情况。
结果证明了许多因素(如中间盒干扰、服务器多样性、网络多样性等)引起的复杂性。我们展示了现有规避策略的总体成功率,并列举了失败案例的可能原因。要完全解开导致失败的因素,并量化每个因素的影响,需要更深入的分析和受控体验(例如,使用重放服务器,如18),这一点我们留待以后的工作。
4 进化后的GFW行为
先前假设 1
- GFW只有在看到SYN数据包时才会创建一个TCB
为了测试这个假设,我们使用了我们控制下的一对客户机和服务器,并执行了「不完整」的 TCP 3路握手(例如,故意省略 SYN、SYN/ACK和/或 ACK),然后是一个带有敏感关键字的 HTTP 请求。如果在GFW上创建了一个正确的TCB,HTTP 请求就会触发它的 TCP 重置 packet。首先,我们的结果证实了GFW在看到 SYN packet 时会创建一个TCB,就像17中描述的那样。其次,更有趣的是,我们发现 GFW 在看到一个没有 SYN packet 的 SYN/ACK packet 时仍然会创建一个TCB。我们推测,GFW 已经更新到加入这个功能来对抗第一次 SYN packet 的丢失。鉴于这些,我们推测 GFW 表现出以下新的行为。
新行为假设 1
GFW 不仅在收到SYN数据包时创建一个 TCB,而且在收到 SYN/ACK 数据包时也创建一个 TCB
先前假设 2
- GFW 使用第一个 SYN 报文中的序列号来创建 TCB,并在 TCB 的生命周期内忽略以后的 SYN 报文。
这个假设是基于理论上,GFW 是模仿普通 TCP 实现的。我们仔细观察后发现,它并不是这样。
从 §3 的结果中,我们看到,在大多数情况下,用 "假" SYN 插入 packet 的方法失败了。
这使我们重新审视这种情况。我们发送多个 SYN 包,其中只有一个包有 "真 "序列号,然后发送一个敏感的 HTTP 请求。然而,无论我们把 "真" SYN 包放在哪里,GFW总是能检测到后面的敏感关键字。我们推测,这可能是由于以下三种可能的原因造成的
原因:
- GFW 对每个 SYN packet 都维持一个 TCB;
- GFW 更新为「stateless」模式了, 在模拟数据流之前检查每一个 packet
- GFW 用之后的 HTTP request 来重新同步 TCB
为了检查 (1) ,我们将HTTP请求中的 sequence 设置为 和之前的 SYN packet 完全不同的值;
但是,我们发现GFW仍然可以检测到该关键字。
为了研究(2),我们将敏感关键字分成两个 packet ,每一半本身都不是敏感关键字;
但是,我们发现GFW仍然可以检测到它。
对于(3),在发送 HTTP 请求之前,我们随机发送一些 sequence 为 "假" 的数据,然后再发送 sequence为 "真" 的 HTTP 请求;在这种情况下,GFW 无法检测到它。
这说明,GFW 用随机数据中的 sequence 重新同步了它的 TCB,因此,忽略了后面的 HTTP 请求,因为它的序列号在窗口外。这就验证了假设(3),即GFW在看到多个SYN数据包时进入 "重新同步状态"。我们在 §7 中进一步广泛地验证了这一点。除了多个 SYN 包外,我们发现多个SYN/ACK包或 ACK 号不正确的 SYN/ACK 包也会导致 GFW 进入重新同步状态。
接下来,我们尝试找出 "GFW在重新同步状态下,使用哪个数据包来重新同步其TCB"。从前面的经验中,我们了解到GFW重新同步是使用从客户端到服务器的数据包。因此,我们改为尝试使用从服务器到客户端的数据包;另外,我们还尝试了双向无数据的纯ACK包。我们发现这些数据包都不会影响GFW。但是,我们发现从服务器到客户端的SYN/ACK数据包会导致重新同步。我们承认,我们发现的情况可能并不完整,但很难列举出一套详尽的情况。然而,我们的测量结果使我们对 GFW 的行为有了比现在更好的理解,并使我们提出了以下新的假设。
新行为假设 2
GFW进入我们所说的 "重新同步状态",当遇到以下三种情况中的任何一种时,它就会利用下一个从服务器到客户端的 SYN/ACK 包或从客户端到服务器的数据包中的信息重新同步其 TCB。
- 它看到来自客户端的多个SYN包,
- 它看到来自服务器端的多个SYN/ACK包
- 它看到一个 SYN/ACK 包的 ACK 号与 SYN 包中的 sequence 不同。
先前假设 3
- 当 GFW 看到一个RST、RST/ACK或FIN数据包时,就会拆除一个TCB。
§3中的结果表明,进化后的 GFW 一般不会仅仅在看到 FIN
包时就拆掉一个TCB。同时,我们还观察到我们的RST和RST/ACK插入包的失败率很高,超过20%。仔细观察表明,这可能和新行为 2
有关。更具体地说,我们发现,当GFW处于新发现的 "重新同步状态
"时,其TCB有时无法用RST或RST/ACK数据包拆除。为了验证这一点,我们使用上述技术之一强制 GFW
进入重新同步状态,然后立即发送RST包和带有敏感关键字的HTTP请求。但是,GFW「有时」还是能检测到。我们在不同时间用多对客户端和服务器重复体验,发现不同时间不同对的测量结果不一致。
总的成功率大概是80%,对于特定的客户机和服务器对,GFW的行为通常在某一时期是一致的(虽然不一定是跨时期)。我们目前还无法挖掘出背后的明确原因,我们猜测这是由于所遇到的GFW类型的异质性以及不同GFW实例和中间盒之间交互的复杂性所导致的动态。我们将在第8节进一步讨论这个问题。此外,我们进行了广泛的测量,在3路握手的SYN/ACK和ACK包之间,以及3路握手之后,我们发送了一个RST包。我们发现,在这两种情况下,TCB有时并没有被拆除,因为RST包导致GFW进入重新同步状态。此外,前一种情况发生的频率更高(差异的确切原因仍然未知)。这些观察结果导致了以下新的假设。
新行为假设 3
- 看到 RST 或 RST/ACK packet 后,GFW 可能会不拆除 TCB,而是进入重新同步状态。
5 规避GFW的新方法
在本节中,我们将从两个方面讨论新的逃避机会。首先,基于 GFW 的新假设行为,我们提出了新的规避策略。第二,我们试图系统地发现其他可用的的 "假" 插入包(除了之前的 错误 checksum 或 小TTL)。
5.1 脱同步 GFW
首先,我们描述了一个构件来对抗 GFW 中的重同步状态。它对支持我们新的规避策略很有帮助,接下来将讨论这些策略。具体来说,当我们预期GFW处于重新同步状态时(这可以强制),我们发送一个插入数据包,其序列号超出窗口。
一旦GFW与这个插入数据包中的序列号重同步,随后连接的合法数据包就会被认为序列号在窗口外,从而被 GFW 忽略。现在 GFW 与连接的异步化了。请注意,插入数据包被服务器忽略了,因为它包含了一个窗口外的序列号。
解除GFW的异步化极大地帮助改善了 "TCB Teardown" 和 "In-order Data Overlapping" 策略,这些策略仍然比较好用,但偶尔会遇到不希望看到的高 "失败1 "和 "失败2 "率。
5.2 新的规避策略
Resync + Desync
为了强制 GFW 进入重新同步状态,客户端在3路握手后发送一个SYN插入包。随后,客户端发送一个包含窗外序列号的1字节数据包,使重新同步状态下的 GFW 解同步。然后再发出真正的请求。需要注意的是,在收到回复的 SYN/ACK 数据包之前不能发送SYN插入数据包,因为 GFW 最终会根据 回复的 SYN/ACK 的 ACK号 重新同步预期的客户端序列号。此外,SYN 插入包应该采取服务器预期接收窗口之外的 sequence(因为在旧版Linux中,这会导致连接重置)。新版本的Linux将永远不会接受这样的SYN数据包,不管它的序列号是多少,而只会以一个挑战ACK来回应7。此外,我们还可以用小的 TTL 制作插入SYN包,以防服务器或中间盒的干扰。
TCB Reversal
如上所述,GFW 目前只对从客户端到服务器的流量进行审查(如HTTP/DNS请求),除了极少数情况外,对 HTTP Response 的审查已经停止20。当GFW第一次看到一个 SYN/ACK 时,它假设源是服务器,目的是客户端。它创建一个TCB来监视这个连接。为了利用这一特性,客户端将首先发送一个 SYN/ACK 插入包。现在,它将只监视从服务器到客户端的数据包(误以为它正在监视从客户端到服务器的数据包)。之后,客户端以正常方式执行TCP三方握手。GFW将忽略这些握手包,因为这个连接已经存在一个TCB。需要注意的是,SYN/ACK 插入包的制作要小心。在正常情况下,收到包的服务器会用RST响应,这将导致GFW的原始TCB被拆除。为了解决这个问题,需要在插入包中使用其中一个差异(例如,较低的TTL)。另外,我们指出,这里客户端的 SYN/ACK 和后续的 SYN 包不会触发GFW进入重新同步状态。
5.3 新的注入包
所有的 GFW 规避策略都需要注入额外的数据包或修改现有的数据包来破坏在 GFW 上维护的 TCP 状态17,23。注入数据包特别方便,也和 GFW 的注入行为相对应。
正如在§3中所提到的,插入数据包的制作可能很棘手。它们可能会因为许多原因而失败,例如网络动态、路由不对称、晦涩的网络中间盒和服务器 TCP 栈的变化。我们的观察是,没有一个插入包是普遍适用的。这促使我们去发现更多的插入包,这些插入包可能是可行的,并对现有插入包进行补充。
发现插入数据包的理想解决方案是获得GFW、服务器和网络中间盒的精确TCP模型,并将其输入到自动推理引擎中(查看什么样的数据包可以作为插入数据包)。然而,由于GFW是一个黑盒,只有一个可观察的反馈属性(会注入 RST 包),所以要准确、完整地推断其内部状态相当困难。我们在 §4 中推断的进化 GFW 模型也不可能是完整的。因此,即使抛开网络中间盒,解决这个问题也很难。
我们的解决方案如下:我们不试图准确地对GFW进行建模,而是首先使用 "忽略 "路径分析对服务器(例如,流行的Linux和FreeBSD TCP堆栈)进行建模。我们的意思是,我们要识别和推理服务器的TCP实现中导致其忽略接收数据包的点。具体来说,对于一个传入的数据包,我们分析所有可能的程序路径,这些路径导致数据包要么被完全丢弃,要么被 "忽略",并可能发送 ACK 作为响应。第一种情况的例子是具有错误校验和的数据包;第二种情况可能是具有窗口外序列号的数据包,这将触发重复的ACK21。在这两种情况下,主机(服务器)的TCP状态(如下一个预期序列号)保持不变。在我们推导出这个服务器模型后,我们用它来开发针对GFW的探测测试。
对于Linux等开源操作系统,可以通过类似于PacketGuardian8中的静态分析功能来实现。
所面临的挑战是手动识别所有发生 "忽略
"事件的程序点。一旦识别出忽略路径,就需要计算出导致每条路径的约束条件,并用于引导测试数据包与GFW对接。一旦我们识别出数据包被GFW "接受
"的情况,即 GFW 根据数据包中的信息更新了它的TCB,我们就可以得出:
「这样的数据包是有效的插入数据包」
(注意,我们还没有考虑到来自网络中间盒的干扰)。
在分析过程中,我们只需要考虑仍有可能接收数据的TCP状态,即TCP_LISTEN、TCP_SYN_RECV、TCP_ESTABLISHED。例如,我们省略了TIME_WAIT状态,因为服务器在这个状态下已经不能再接收数据,了解其忽略路径是没有结果的。当我们为每个TCP状态生成服务器的忽略路径后,我们首先生成一个通向特定TCP状态的数据包序列;然后针对每个忽略路径生成的约束集,我们生成一个或多个测试数据包(作为候选插入数据包)。
需要注意的是,每个忽略路径都会导致数据包被服务器忽略的唯一原因(例如,要么是错误的校验和,要么是无效的ACK,但绝不是两者都有)。Ptacek等人23使用了类似的方法来研究FreeBSD的TCP协议栈,可惜该协议栈太老了,不适用。相比之下,我们研究的是最新的Linux TCP协议栈,它有很多新的行为。此外,我们还改进了方法论,修剪了一些不相关的TCP状态下的 "忽略 "路径,比如TIME_WAIT,以及将 "忽略 "情况与中间件行为关联起来。
作为示范,我们对Linux内核4.4版本进行这样的分析。在表3中,我们列出了Linux忽略数据包而GFW没有忽略的确认情况。我们还尝试将服务器状态与GFW状态进行比较,以使差异更加清晰。

请注意,这是比之前报道的17,23更完整的列表,显示了我们系统分析的优势。例如,发现包括两个新的插入包:
- 在TCP_RECV状态下,ACK 号不正确的 RST/ACK 数据包会被服务器忽略,但 GFW 会接受这样的数据包,并将其状态改为 TCP_LISTEN(前一个状态终止)或TCP_RESYNC,取决于 GFW 的新旧模型。
- 不请自来的带有 MD5 头的数据包会被服务器忽略(因为事先没有对可选的MD5认证进行协商),而GFW会按照正常的方式处理该数据包。
MD5头15的差异可以在带有任何 TCP flag 的插入数据包中被利用。例如,这可以在 RST packet 中用来拆除 GFW 上的 TCB ,或者在 data packet 中用来欺骗 GFW 改变其维护的 TCB 中客户端 sequence 号。
请注意,我们有意省略了对数据重叠(用于处理失序和重叠的数据包)差异的分析,因为据了解,不同的操作系统可能会采用不同的策略23,因此它可能不会成为可靠的插入数据包。
与网络中间盒的交叉验证
即使根据我们的实验,分析生成的插入数据包效果很好,但在中间盒上可能玩得并不好。IP 层的修改,如错误的IP校验和、IP可选头、IP头长度,具有这种数据包往往会被路由器或中间盒丢弃。我们认为唯一有用的特性是 "IP总长度 "大于 "实际数据包长度 "的特性(列于表3);但是,具有这种特性的数据包仍然可能被一些中间盒检查和丢弃。利用 TCP 层修改的插入数据包(如与不正确的TCP头长度或错误的TCP checksum 和有关的数据包),也可能被中间盒丢弃,特别是在某些环境,任何 TCP 状态和 flag 的包存在扰动。唯一的例外是利用未经请求的 MD5 头的插入数据包;在我们的实验中,我们遇到的中间盒从未丢弃过这些数据包(可能是因为它需要一个有状态的防火墙中间盒来了解何时应该丢弃这些数据包)。
其余的插入包只能对数据包有用。不能用这些来制作有效的控制包;例如,当服务器处于 ESTABLISHED 状态时,即使 RST/ACK 有错误的 ACK 号或旧的时间戳,它仍然能够成功地重置连接。根据我们的实验,中间盒不会丢弃带有意外的 MD5、旧的 timestamp 或不正确的 ACK 号的数据包。
与其他 TCP 栈的交叉验证
要详尽地测试所有部署的TCP栈的忽略路径不说不可能,至少是很困难的。我们将 Linux 内核 4.4 和其他几个流行的 Linux 版本,包括 4.0、3.14、2.6.34 和2.4.37 的忽略路径进行交叉验证,此对结果进行了总结。
- 在Linux 3.14中,当连接处于 ESTABLISHED 状态时,带有SYN标志的传入数据包将被忽略,而新的GFW模型将接受它。
- 在Linux 2.6.34和2.4.37中,当连接处于ESTABLISHED状态时,一个没有设置ACK标志的传入数据包将不会被忽略。相反,一个没有ACK标志的数据包将被接受。这表明,这样的插入数据包将无法适用于旧的 Linux 版本。
- 在Linux 2.4.37中,一个带有非请求MD5头的插入数据包将不会被忽略。这是由于旧版Linux没有实现 RFC 2385 15 中提出的功能。经过仔细检查,服务器上的MD5选项检查可以通过内核编译选项关闭,因此事实上相应的插入数据包可能并不总是有效。
这表明大多数插入包都适用于广泛的Linux操作系统,但也有一些小的例外(如果遇到的Linux版本太旧)。由于Linux在服务器市场上占主导地位26,我们设想建立在这些插入数据包之上的规避策略将很好地发挥作用。事实上,正如我们在§7中所展示的那样,如果我们要正确地利用这些插入数据包,我们的GFW规避成功率是非常高的。为了发现更多的差异并进行自动的 "忽略路径 "分析,我们计划在未来使用选择性符号执行(例如S2E9)。对其他 Linux 版本和操作系统,包括像 Windows Server 这样的闭源操作系统的 TCP 栈进行更严格的分析,是我们未来的一项工作。
6 INTANG
略
7 EVALUATION
略
8 讨论
GFW Countermeasures
我们的工作是以 GFW 最新发展为基础的。当然,GFW 可能会进行更多的改进来击败我们的规避策略,我们承认这是一场军备竞赛。例如,我们证明 GFW 在接受 RST 数据包方面比普通服务器更「包容」,那么审查员就有可能对 RST 数据包进行额外的检查(例如,校验和和MD5选项字段)作为防御。但这可能会对GFW开启新的规避攻击(例如,当服务器不检查MD5选项字段时)(译者: TCB 无法关闭了)。人们还可以利用GFW对网络拓扑结构的不可知性。例如,我们可以设定准确的 TTL 值来(使 packet)到达 GFW ,而不至于到达服务器(虽然要同时达到精度和效率也是一个挑战)。
GFW可以做的另一个潜在的改进是,只有在看到服务器的ACK包确认了相应的 sequence 之后,才相信客户端发送的数据包。然而,这将使GFW的设计和实现大大复杂化。
总之,我们认为这是一场军备竞赛。随着 GFW 的发展,规避策略也会发生变化。我们认为,推出新的 GFW 的成本相当高,而且这种演变将在几个月(如果不是几年)的时间范围内发生,这就为制定规避策略留下了足够的时间(特别是在利用INTANG等工具时)。例如,一旦 GFW 发生演变,就会产生新的 GFW 模型,并进行 "忽略路径 "分析,从而产生新的规避策略。
Complexity and (sometimes) inconsistency of the GFW
自2015年以来,我们在长期研究GFW的过程中观察到,第一类和第二类重置有时会单独出现。
例如,在某些日子里,从北京CERNET的观测点,我们只能观察到类型1的重置,而在其他日子里,两种类型都能看到。我们的观察表明,两种类型的 GFW
设备通常是一起部署的,有时会有一个设备宕机。此外,我们还发现,当两种类型一起工作时,有一些相当复杂的影响。在2016年5月的一次测量中,我们发现在我们使用新的策略规避2型设备后,1型
GFW
设备也会像2型设备一样,有一个后续的90秒的阻断期(它通常不会)。而当我们不使用任何策略时,只能观察到type-2复位(即type-1设备没有执行90秒的阻断期)。看起来,type-2复位抑制了type-1复位。这种罕见的行为在其他测量中没有观察到。此外,在2016年5月和2017年5月,我们观察到RST数据包有时无法撕毁
GFW 上的 TCB ,如果调整受控客户端和服务端的组合。
这种不一致的行为可能是由于不同版本的GFW之间的负载均衡,或者是几个GFW设备一起部署造成的一些复杂的影响。然而,我们没有办法获得基本真相。我们承认我们的测量结果在很大程度上受到了限制,除了GFW设备本身的黑盒性质外,还受到不同版本GFW设备(甚至是中间盒)之间的干扰以及它们的部署方式的影响。我们有兴趣在未来的工作中进一步探索这种复杂性和不一致性。
Combination of Strategies
GFW是异质的,有不同的共存版本。因此,正如我们在本文中所做的那样,有必要将针对GFW不同版本的有效战略结合起来。只要策略之间不冲突就没有问题。但是,当采用多种策略时,"失败1 "率很可能会增加。这是因为插入数据包的增加,增加了中间盒干扰或对服务器产生副作用的可能性。
Ethical Considerations
我们所有的实验都是经过精心设计的,不会对正常的网络运行造成干扰。所有的连接都是由我们租用或直接控制的机器建立的。额外的插入数据包只是普通的TCP数据包(有时有错误的字段值),可能只是被服务器丢弃。我们将每个网站的流量控制在较低的水平,以避免任何意外的拒绝服务攻击。
请注意,INTANG 并不保证其所有策略的不可观察性。用户可以自行决定是否在审查员的管辖范围内使用 INTANG 。然而,在中国,由于重审查制度16下,"翻墙 "和访问 Google、Facebook 等网站成为一种普遍需求。审查者通常会惩罚那些为大众提供审查规避服务的人(如代理/VPN提供商),而不是惩罚服务的用户。
像 INTANG 这样只在客户端使用的工具,将更难被审查员追踪和挫败。
9 相关研究
我们已经在整篇论文中提到了各种相关的努力(尤其是在第2节)。这些工作都集中在评估审查技术或由VPN等附加设施辅助的反审查技术上。
Clayton等人,建议忽略 GFW 发送的 RST 数据包10。这需要服务器端同时忽略,因此是不切实际的(所有服务器都需要安装一个补丁才能做到这一点)。它并不能阻止审查员监控用户流量。因此,我们在工作中没有考虑这个方法。如前所述,Ptacek等人23,深入了解当前 NIDS 的局限性,这在很大程度上影响了后来(包括我们)在TCP重置攻击规避方面的努力。西厢计划25是一个实现了Ptacek等人理论的审查-规避工具。但是,它只是利用两种制作好的数据包从两个方向撕毁 GFW 上的 TCB ,现在已经失效了。
Khattak等人的研究17是与我们最相关的工作。
他们的策略以及其中的问题已经在第3节中讨论过。此外,我们的测量利用了多个观测点,而不是像17那样利用一个观测点。我们的测量研究导致发现GFW的部署和特征与该工作中提出的不同。Li 等人18对已知的TCP/IP插入数据包进行了测试,以对抗三个国家的审查防火墙和 DPI盒子,并评估其有效性。相比之下,我们的工作重点是了解和发现最大和最复杂的审查系统的最新发展(新状态机),这使我们能够设计新的规避策略。
10 结论
在本文中,我们进行了,可以说是对中国GFW上有状态的(TCP级)互联网审查规避行为最深入的测量研究。我们的工作分为多个阶段。
首先,我们对之前的方法进行了广泛的测量,发现它们不再有效。我们将其原因归结为两个主要原因。(a)GFW已经进化成了新的行为;(b)在客户端和服务器之间的路径上存在着中间箱,这些中间箱会干扰规避策略。
其次,基于所获得的知识,我们对新的GFW行为进行了假设,并设计了今天可能规避GFW的新策略。我们还建立了一个新颖的、测量驱动的工具 INTANG,它可以为给定的客户服务器对收敛正确的规避策略。在最后阶段,我们对我们的新策略和 INTANG 进行了广泛的测量,并证明它们在组合时提供了近乎完美的规避率,从而验证了我们对当今 GFW 有状态审查模型的新理解。
ACKNOWLEDGMENTS
This work was supported by Army Research Office under Grant No.
62954CSREP and the National Science Foundation under Grant No. 1464410,
1652954, and 1652954.
We thank our shepherd Prof. Alan Mislove and the anonymous reviewers for
their constructive comments towards improving the paper.
(完)
原本 PDF 在 conferences.sigcomm.orgAlter 翻译: Your State is Not Mine 浅析 INTANG 工作原理 by ZRStea Nov 27, 2017
参见phantomsocks 和 TCPioneer 是文中提到的 desync 方法的另一个实现,可以规避 (同样使用 TCP 重置攻击的)检测SNI的HTTPS过滤。
from https://rentry.co/Your_State_is_Not_Mine_zh_CN
------
Your State is Not Mine, 浅析 INTANG的 工作原理
近来一篇名为 Your State is Not Mine: A Closer Look at Evading Stateful Internet Censorship 的论文在中文互联网上炒的沸沸扬扬,作者为加州大学的三名学生。文章号称详细分析了墙的状态机,实现了成功率高达98%的穿墙策略,并将其实现在 Github 上进行了开源。
因为某些机会,正好有时间让我大致读了读这篇论文,文章水平与工作的完成度很高,其中有很多思路是极具启发性的,现分享心得于此:
墙的工作原理
对于明文协议,墙想要实现关键词审查,必须对于所有的TCP流量进行重建并在应用层进行审查。对于主干网来说,这个开销是巨大的。为了不影响到正常的网络通信,墙是一套旁路系统,不能对流量进行直接干涉。当其检测到敏感词的时候,对于已存在的TCP连接,会向连接双方发送RST阻断连接,并持续监测接下来的握手请求90s,一旦发现SYN,则会回应RST/ACK阻断握手。
想要实现正确的高层协议重建,墙必须对TCP连接的状态进行跟踪记录,这也是为什么我们说墙是基于状态的。根据观察,墙会建立一个TCB(TCP Control Block),对每个TCP连接的状态进行追踪。根据推测,TCB中最起码应该记录了源、目标IP、端口、Sequence Number、当前状态、窗口等信息。
知道了这些,就可以针对TCB做一些事情了。
曾经存在的策略:
TCB Creation:
建立真实连接之前首先发送一个带有错误SEQ的SYN,让墙创建一个错误的TCB,之后进行正常握手,墙会因为TCB中SEQ的错误无法继续追踪。
DATA Reassembly:
1.将带IP报分片,对于带有相同SEQ和Lenth的数据包,墙会捕获第一个忽略第二个。故可以先发送构造的带有垃圾数据的分片,填充墙的接收缓存,再发送带有真实数据的分片,最后发送分片的第一部分完成数据发送。
2.对于不分片的数据同理,对于同一个TCP包(具有相同五元组的)先后发送填充了垃圾数据虚假包与真实数据,绕过审查。
TCB Teardown:
墙在观察到RST、RST/ACK或FIN包的时候,会终止TCB块。曾经著名的西厢计划就是使用的此策略。
注入包的构造方法
以上构造用于引发TCB异常的Insert Packet,需要特别处理防止对服务端行为造成影响,一般的思路为使用比测量值更低的TTL、错误的checksum使得Packet只经过墙而不到达服务端,或者让服务端检查出错误从而丢弃。
论文中发现了一种新的构造方法,即在事先未声明的情况下使用MD5 header,相应的包会被服务端所忽略但会被墙所接受。
新的策略
墙的进化
论文中对既有策略进行了测试,发现TCP Creation与TCP Teardown策略基本失效,这是墙的不断迭代升级所导致的,另外还观察到在不同的路由上墙的表现有所不同,应为墙的不同实现或是不同版本同时在路由中存在。
经过观察和实验验证,对于进化后的墙的行为,得出了以下三个结论:
1.墙不仅在收到客户端发起的SYN时,在收到服务端的SYN/ACK,也会创建相应的TCB。
2.墙在观察到:
(1)客户端发出多个SYN
(2)服务端返回多个SYN/ACK
(3)SYN/ACK的确认号与之前的SYN包不匹配
任意一种情况,会进入”re-synchronization state”,利用下一个收到的从服务端到客户端的SYN/ACK包或是从客户端到服务端的数据包重新同步TCB。
3.当收到RST、RST/ACK或FIN包的时候,TCB不会马上被销毁,而是进入re-synchronization state。若有后续的数据传输发生,则会重新同步。
对应策略
由以上墙的新版本行为,可以构建出以下的新策略来:
1.Resync + Desync:
Resync:三次握手完成后发送一个SYN包,使墙进入re-synchronization state;
Desync:紧接着发送1字节超出当前窗口的数据包,诱使TCB重新同步到错误的SEQ上去。
2.TCB Reversal:
TCP三次握手之前首先发送一个SYN/ACK包让墙建立反向的TCB,把客户端当作服务端,因为墙几乎不审查HTTP response,所以同样可以实现绕开审查的效果。
INTANG
工具架构

联合策略
因为墙的新老行为即设备在网络中均有部署,为了提高成功率,INTANG工具使用了联合策略来进行穿墙工作,工作流程如图:

同时论文中还测试了不同构造包的可用性
总结
尽管目前主流的穿墙方法是将无状态加密流量通过境外的服务器进行转发,典型的工具有 Shadowsocks、V2ray 等,这一思路因为部署简单,灵活去中心而在近年的翻墙实践中占据主流,相关产业链也应运而生。
但随着审查力度的提升,可用IP的有限,这种猫捉耗子的游戏是不可持续的。今后的研究方向应该向提高审查成本,寻找墙本身的协议栈缺陷上来,这篇文章给予了我们很好的启示。
以下是论文中关于这场军备竞赛的论述,值得一读:
Our work is based on the latest developments of the GFW. It is certainly possible that GFW may undergo additional improvements to defeat our evasion strategies, and we acknowledge that it is an arms race. For instance, we demonstrate that GFW is more liberal in accepting RST packets than normal servers. It is possible that the censor may perform additional checks on the RST packets (e.g., checksum and MD5 option fields) as a defense. But that may open up a new evasion attack on the GFW (e.g., when the server does not check MD5 option fields). One can also leverage GFW’s agnostic nature to network topology. For example, we can measure the exact TTL value to bypass the GFW while not to reach the server (although it is also a challenge to achieve accuracy and efficiency simultaneously).
Another potential improvement the GFW can make is to trust the data packet sent by the client only after seeing the server’s ACK packet acknowledging the appropriate sequence number. However, this will greatly complicates the GFW’s design and implementation.
In summary, we believe this is an arms race. As GFW evolves, so can the evasion strategies. We believe that the cost of rolling out new GFW models is quite high and such evolution will happen at the timescale of months (if not years), which leaves enough time for evasion strategy development (especially when tools like INTANG are leveraged). For instance, as soon as the GFW evolves, a new GFW model will be derived and subjected to the “ignore path” analysis, which can lead to the generation of new evasion strategies.
需要注意的是,INTANG所用策略是无法处理已经上黑名单的IP的,因为黑名单封锁发生在IP层,对于一切黑名单上IP的入站均会被丢弃。所以仅凭INTANG无法访问大部分互联网主流服务,如Facebook、Google等。而DNS over TCP、Tor等目前在INTANG上工作的很好。
另外一些思考:因为目前INTANG仅处理HTTP与DNS等流量,如果将INTANG用到所有的跨境TCP连接上来,对于目前的某些转发协议,如ss、vmess、websocket over SSL等,是否有着规避审查,更加低调的效果呢?(因为对于加密流量的审查,第一步也需要重建数据流,而论文中所述策略则直接绕开了这一步。除非是可能的大规模机器学习方法上线,且仅从IP或TCP层进行流量特征的抽取、学习,但是这个成本是非常巨大的。)故在可见的未来如果目前的审查目的不被放弃的话,墙的升级策略应该仍会以修修补补为主,这就存在着潜在的机会。
from https://web.archive.org/web/20190403214946/https://zrstea.com/263/
No comments:
Post a Comment