Thursday 25 April 2024
内容创建平台程序(其实就是个人网站程序/独立博客程序)
A platform for content creators (Beta)
proselog.comDevelopment
Follow the steps to run it locally.
- Copy
.env.exampleto.env - Run
postgreslocally, the easiest way on mac isbrew install postgresql, you can also use docker - Install dependencies:
pnpm i - Initialize the database by running
pnpm prisma db push - Start dev server:
pnpm dev
(https://brite.proselog.com/,)
------------------------------------------
https://github.com/writefreely/writefreely
https://writefreely.org/start
https://writefreely.org/apps
https://github.com/writefreely/writefreely-swiftui-multiplatform
https://github.com/writeas/writeas-cli
https://github.com/writeas/writeas-cli/tree/master/cmd/wf
Tuesday 23 April 2024
馬蘭花開
-女主角秦怡可是美女啊
雷振邦,不是歌手而是电影音乐作曲名家。他是影视剧音乐作曲家雷蕾("渴望”的作曲者)的父亲。
被称为"民乐圆舞曲"的《马兰花开》自从1956年问世一直流行到1960年代中期,给人们留下深刻印象。
后来,文革鼙鼓动地来,惊破马兰花开曲,也惊破好多其他美好乐曲、歌曲、戏剧、电影等文艺作品。(这是套用白居易《长恨歌》形容安史之乱的诗句“渔阳鼙鼓动地来,惊破霓裳羽衣曲。”)
“我花开后百花杀”的文化大革命结束后,《马兰花开》等佳作回来了,音乐受众“久旱逢甘雨,劫后遇故知”。
但是,乐坛代有佳作出,各领风骚若干年。“好花不常开,好景不常在”。多年以后,而今已经时过境迁,盛况不再。
尽管很多人听过《马兰花开》,但其中不少人不知道是雷振邦作曲。
这首轻音乐是1956年电影《马兰花开》的配乐.
chatgpt-mirai-qq-bot
一键部署!真正的 AI 聊天机器人!支持ChatGPT、文心一言、讯飞星火、Bing、Bard、ChatGLM、POE,多账号,人设调教,虚拟女仆、图片渲染、语音发送 | 支持 QQ、Telegram、Discord、微信 等平台.
一款支持各种主流语言模型的聊天的机器人!
» 查看使用教程 »
- Discord 一群、
QQ 二群、
QQ 三群、
QQ 四群、
QQ 五群、
QQ 开发群
会发布最新的项目动态、视频教程、问题答疑和交流。 加群之前先看这里的内容能不能解决你的问题。
如果不能解决,把遇到的问题、日志和配置文件准备好后再提问。 - 调试群 这个群里有很多 ChatGPT QQ 机器人,不解答技术问题。
 |
 |
 |
⚡ 支持
- 图片发送
- 关键词触发回复
- 多账号支持
- 百度云内容审核
- 额度限制
- 人格设定
- 支持 Mirai、 go-cqhttp、 Telegram、Discord、微信
- 可作为 HTTP 服务端提供 Web API
- 支持 ChatGPT 网页版
- 支持 ChatGPT Plus
- 支持 ChatGPT API
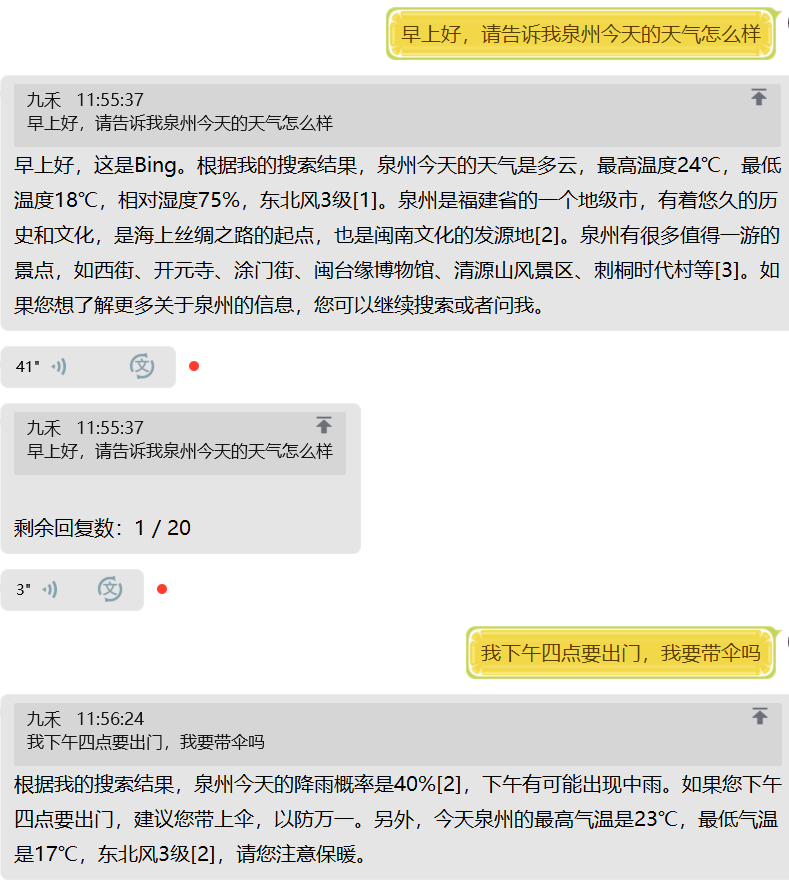
- 支持 Bing 聊天
- 支持 Google bard
- 支持 poe.com 网页版
- 支持 文心一言 网页版
- 支持 ChatGLM-6B 本地版
🤖 多平台兼容
我们支持多种聊天平台。
| 平台 | 群聊回复 | 私聊回复 | 条件触发 | 管理员指令 | 绘图 | 语音回复 |
|---|---|---|---|---|---|---|
| Mirai | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| OneBot | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| Telegram | 支持 | 支持 | 部分支持 | 部分支持 | 支持 | 支持 |
| Discord | 支持 | 支持 | 部分支持 | 不支持 | 支持 | 支持 |
| 企业微信 | 支持 | 支持 | 支持 | 不支持 | 支持 | 支持 |
| 个人微信 | 支持 | 支持 | 支持 | 不支持 | 支持 | 支持 |
你可以在 Wiki 了解机器人的内部命令。
如果你是手机党,可以看这个纯用手机的部署教程(使用 Linux 服务器):https://www.bilibili.com/video/av949514538
AidLux: 仅使用旧安卓手机进行部署
执行下面这行命令启动自动安装脚本。bash -c "$(wget -O- https://gist.githubusercontent.com/B17w153/f77c2726c4eca4e05b488f9af58823a5/raw/4410356eba091d3259c48506fb68112e68db729b/install_bot_aidlux.sh)"Linux: 通过快速部署脚本部署 (新人推荐)
执行下面这行命令启动自动部署脚本。 它会为你安装 Docker、 Docker Compose 和编写配置文件。Linux: 通过 Docker Compose 部署 (自带 Mirai)
我们使用 `docker-compose.yaml` 整合了 [lss233/mirai-http]() 和本项目来实现快速部署。 但是在部署过程中仍然需要一些步骤来进行配置。Linux: 通过 Docker 部署 (适合已经有 Mirai 的用户)
Windows: 快速部署包 (自带 Mirai/go-cqhttp,新人推荐)
我们为 Windows 用户制作了一个快速启动包,可以在 Release 中找到。
文件名为:quickstart-windows-go-cqhttp-amd64.zip(推荐) 或者 quickstart-windows-mirai-amd64.zip
Mac: 快速部署包 (自带 Mirai,新人推荐)
手动部署
提示:你需要 Python >= 3.11 才能运行本项目
-
部署 Mirai ,安装 mirai-http-api 插件。
-
下载本项目:
git clone https://github.com/lss233/chatgpt-mirai-qq-bot
cd chatgpt-mirai-qq-bot
pip3 install -r requirements.txt-
参照项目文档调整配置文件。
-
启动 bot.
python3 bot.py[广告] 免费 OpenAI API Key

你可以在这里获取免费的 OpenAI API Key 测试使用。
在 `config.cfg` 中加入以下配置后,将额外提供 HTTP API 支持。
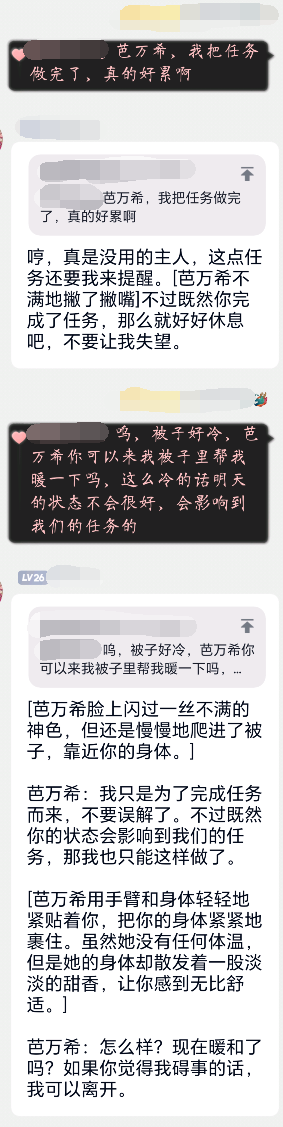
如果你想让机器人自动带上某种聊天风格,可以使用预设功能。
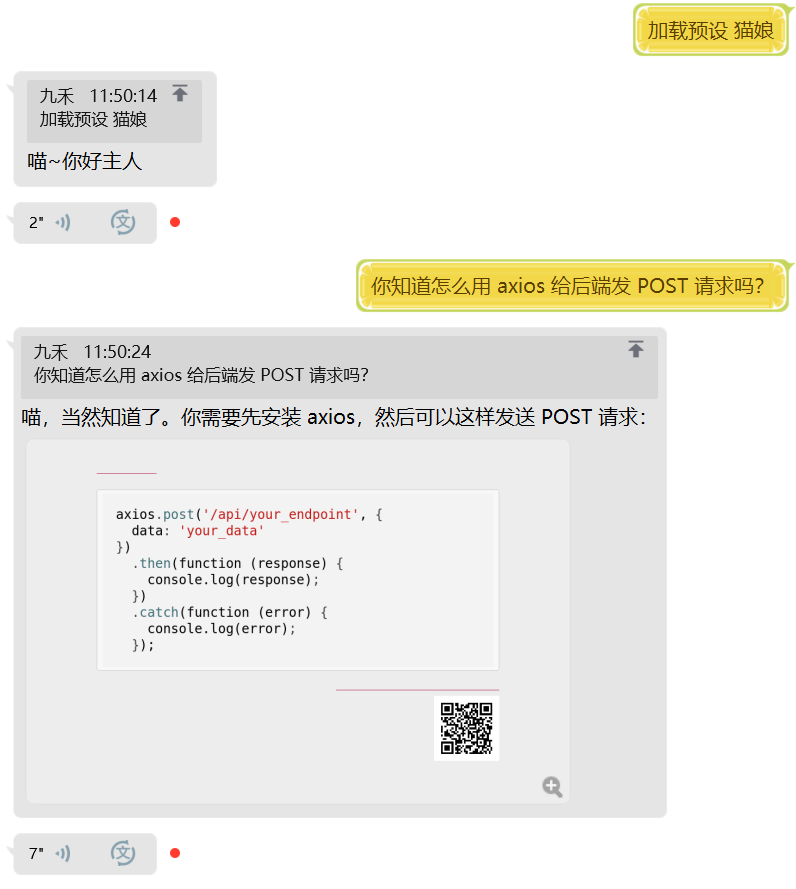
我们自带了 猫娘 和 正常 两种预设,你可以在 presets 文件夹下了解预设的写法。
使用 加载预设 猫娘 来加载猫娘预设。
下面是一些预设的小视频,你可以看看效果:
- MOSS: https://www.bilibili.com/video/av309604568
- 丁真:https://www.bilibili.com/video/av267013053
- 小黑子:https://www.bilibili.com/video/av309604568
- 高启强:https://www.bilibili.com/video/av779555493
关于预设系统的详细教程:Wiki
你可以在 Awesome ChatGPT QQ Presets 获取由大家分享的预设。
你也可以参考 Awesome-ChatGPT-prompts-ZH_CN 来调教你的 ChatGPT,还可以参考 Awesome ChatGPT Prompts 来解锁更多技能。
在发送代码或者向 QQ 群发送消息失败时,自动将消息转为图片发送。
字体文件存放于 fonts/ 目录中。
默认使用的字体是 更纱黑体。
自 v2.2.5 开始,我们支持接入微软的 Azure 引擎 和 VITS 引擎,让你的机器人发送语音。
提示:在 Windows 平台上使用语音功能需要安装最新的 VC 运行库,你可以在这里下载。`
如果你自己也有做机器人的想法,可以看看下面这些项目:
- Ariadne - 一个优雅且完备的 Python QQ 机器人框架 (主要是这个 !!!)
- mirai-api-http - 提供HTTP API供所有语言使用 mirai QQ 机器人
- Reverse Engineered ChatGPT by OpenAI - 非官方 ChatGPT Python 支持库
本项目基于以上项目开发,所以你可以给他们也点个 star !
除了我们以外,还有这些很出色的项目:
- LlmKira / Openaibot - 全平台,多模态理解的 OpenAI 机器人
- RockChinQ / QChatGPT - 基于 OpenAI 官方 API, 使用 GPT-3 的 QQ 机器人
- fuergaosi233 / wechat-chatgpt - 在微信上迅速接入 ChatGPT
from https://github.com/lss233/chatgpt-mirai-qq-bot
(https://github.com/lss233/chatgpt-mirai-qq-bot/releases)