Friday, 28 February 2025
搭建基于github issue的静态博客程序egi
首先 fork 此项目https://github.com/eyasliu/eyasliu.github.io,我fork 后的项目地址是https://github.com/briteming/egi ,然后访问https://github.com/briteming/egi/settings,勾选issues. 新建一些issues.
编辑config.js文件- https://github.com/briteming/egi/blob/master/config.js,把user和repo的值分别改为你的github用户名和仓库名。
然后访问app.netlify.com ( 需先登录),导入项目https://github.com/briteming/egi.
在来到如下页面https://app.netlify.com/start/repos/briteming%2Fegi时,
在 Site name栏,填写一个你所选择的二级域名,我选择的是egi-brite ,

Base directory栏的值,填 ./ (意思就是项目的根目录)
Build command栏的值,填 npm run build
Publish directory栏的值,填 ./ (因为项目的根目录下有index.html, 所以 Publish directory其实就是项目的根目录)
然后点击页面底部的 deploy按钮。等待部署完成,部署完成后,app.netlify.com网站给我的网址是https://egi-brite.netlify.app
演示网站: https://egi-brite.netlify.app/
项目地址:https://github.com/eyasliu/eyasliu.github.io
https://github.com/briteming/egi
---------------------------------------------
首先 fork 此项目https://github.com/eyasliu/eyasliu.github.io,我fork 后的项目地址是https://github.com/ymbrite/egi
然后访问https://github.com/ymbrite/egi/settings,勾选issues. 新建一些issues.
编辑config.js文件- https://github.com/ymbrite/egi/blob/master/config.js,把user和repo的值分别改为你的github用户名和仓库名。
然后访问vercel.com/new ( 需先登录),导入项目https://github.com/ymbrite/egi.
部署完成后,vercel.com/new网站给我的网址是https://egi-blond.vercel.app/
演示网站:https://egi-blond.vercel.app/
项目地址:https://github.com/eyasliu/eyasliu.github.io
https://github.com/ymbrite/egi
人生的两个机会
美国加州有位刚毕业的大学生,在2003年的冬季大征兵中他依法被征,即将到最艰苦也是最危险的海军陆战队去服役。
这位年轻人自从获悉自己被海军陆战队选中的消息后,便显得忧心忡忡。在加州大学任教的祖父见到孙子一副魂不守舍的模样,便开导他说:“孩子啊,这没什么好担心的。到了海军陆战队,你将会有两个机会,一个是留在内勤部门,一个是分配到外勤部门。如果你分配到了内勤部门,就完全用不着去担惊受怕了。”
年轻人问爷爷:“那要是我被分配到了外勤部门呢?”
爷爷说:“那同样会有两个机会,一个是留在美国本土,另一个是分配到国外的军事基地。如果你被分配在美国本土,那又有什么好担心的。”
年轻人问:“那么,若是被分配到了国外的基地呢?”
爷爷说:“那也还有两个机会,一个是被分配到和平而友善的国家,另一个是被分配到战争地区。如果把你分配到和平友善的国家,那也是件值得庆幸的好事。”
年轻人问:“爷爷,那要是我不幸被分配到战争地区呢?”
爷爷说:“那同样还有两个机会,一个是安全归来,另一个是不幸负伤。如果你能够安全归来,那担心岂不多余。”
年轻人问:“那要是不幸负伤了呢。”
爷爷说:“你同样拥有两个机会,一个是依然能够保全性命,另一个是完全救治无效。如果尚能保全性命,还担心它干什么呢。”
年轻人再问:“那要是完全救治无效怎么办?”
爷爷说:“还是有两个机会,一个是作为敢于冲锋陷阵的国家英雄而死,一个是唯唯诺诺躲在后面却不幸遇难。你当然会选择前者,既然会成为英雄,有什么好担心的。”
是啊,无论人生遇到什么样的际遇,都会有两个机会。一个是好机会,一个是坏机会。好机会中,藏匿着坏机会,而坏机会中,又隐含着好机会。关键是我们以什么样的眼光,什么样的心态,什么样的视角去对待它。
如果用乐观旷达、积极向上的心态去看待,那么坏机会也会成为好机会。如果用消极颓废、悲观沮丧的心态去对待,那么,好机会也会看成是坏机会。人生的际遇中,始终存在着两个机会。对那些乐观旷达、心态积极的人而言,两个都是好机会。对那些悲观沮丧、心态消极的人而言,则两个都是坏机会。
土地换和平 换来了什么?特朗普的乌克兰赌局
—27/02/2025
乌克兰总统则连斯基访美签署协议前夕,我们注意到,
据该文作者Benjiamin Jensen表示,除了头条新闻和心痛之外,
百度与宁德时代战略签约,无人驾驶与数智化是核心领域
—28/02/2025
百度与宁德时代(CATL de Chine)近日在福建正式签署了战略合作协议,
据介绍,在数智化建设方面,百度将从芯片、平台、
Wednesday, 26 February 2025
搭建git服务器
通过ssh链接到服务器,开始操作.
第一步
在服务器上安装 git
$ sudo apt-get install git
第二步
创建 git 用户,用来运行git服务
$ sudo adduser git
第三步
创建证书,免密码登录:
收集所有需要登录的用户的公钥(id_rsa.pub)文件,把所有公钥导入到 /home/git/.ssh/authorized_keys 文件内,一行一个。
如果个人的git中的公钥已经连接了其他服务器如:github,可以参考 一个客户端设置多个github账号
注意:一定要通过下面的命令将该文件其他用户的所有权限移除,否则会出现文章尾部问题
$ chmod 600 authorized_keys
第四步
初始化git仓库
$ git init --bare test.git
git创建一个裸仓库,裸仓库没有工作区,因为服务器上的git仓库纯粹为了共享,所有不能让用户直接登录到服务器上去改工作区,并且服务器的git仓库通常以 .git 结尾。然后,修改owner改为git:
$ sudo chown -R git:git test.git
第五步
禁用shell登录:
处于安全的考虑,第二步创建的git用户不允许登录shell,这可以通过编辑 /etc/passwd 文件完成。
git:x:1003:1003::/home/git:/bin/bash
改为
git:x:1003:1003::/home/git:/usr/bin/git-shell
这样,git用户可以正常通过ssh使用git,但无法登录shell,因为我们为git用户指定的git-shell每次一登录就自动退出。
第六步
克隆远程仓库:
现在,可以通过git clone命令克隆远程仓库了,在各自的电脑上运行:
$ git clone git@server:/home/git/test.git
如果服务器的ssh端口不是默认的22的话,比如说6789,可以这样写:
$ git clone ssh://git@server:6789/home/git/test.git
问题来了
本来根据文档,根据广大猿友的经验,我的搭建之路已经完成了,然后最后一步出现了问题。每次跟服务器进行交互(clone,pull,push),都让我输入git的密码,也就是说,我配置的ssh没有生效。然后就开始到处找原因,重新生成rsa,提升authorized_keys权限,重新创建服务器git账户,重新。。。。。
翻遍了 Stack Overflow 和 segmentfault ,两个小时过去了,问题仍然没有进展,这么简单的东西,问题到底出在哪里。
就在心灰意冷,准备放弃的时候,不知道是哪里来的灵感,准备把 authorized_keys 文件的其他用户的权限删掉,然后就能用了,后就能用了,就能用了,能用了,用了,了~~~~,命令如下,不想多说话,我想静静。
$ chmod 600 authorized_keys马斯克政府效率部三分之一团队成员集体辞职
—26/02/2025
特朗普政府26日首次召开内阁成员会议之际,伊隆-
的确,
泽连斯基称与美国的经济协议已准备就绪 但安全保障尚未决定
—26/02/2025
乌克兰总统泽连斯基(Volodymyr Zelenskyy)周三表示,
泽连斯基在基辅举行的新闻发布会上说,
用SecureCRT来上传和下载文件
用SSH管理linux服务器时经常需要远程与本地之间交互文件.而直接用SecureCRT自带的上传下载功能无疑是最方便的,SecureCRT下的文件传输协议有ASCII、Xmodem、Zmodem。
文件传输协议
文件传输是数据交换的主要形式。在进行文件传输时,为使文件能被正确识别和传送,我们需要在两台计算机之间建立统一的传输协议。这个协议包括了文件的识别、传送的起止时间、错误的判断与纠正等内容。常见的传输协议有以下几种:
- ASCII:这是最快的传输协议,单只能传输文本文件。
- Xmodem:这种古老的传输协议速度较慢,但由于使用了CRC错误侦测方法,传输的准确率可高达99.6%。
- Ymodem:这是Xmodem的改良版,使用了1024位区段传送,速度比Xmodem要快
- Zmodem:Zmodem采用了串流式(streaming)传输方式,传输速度较快,而且还具有自动改变区段大小和断点续传、快速错误侦测等功能。这是目前最流行的文件传输协议。
除以上几种外,还有Imodem、Jmodem、Bimodem、Kermit、Lynx等协议,由于没有多数厂商支持,这里就略去不讲。
SecureCRT可以使用linux下的zmodem协议来快速的传送文件,使用非常方便.具体步骤:
在使用SecureCRT上传下载之前需要给服务器安装lrzsz
- 从下面的地址下载 lrzsz-0.12.20.tar.gz
- 查看里面的INSTALL文档了解安装参数说明和细节
- 解压文件
$ tar zxvf lrzsz-0.12.20.tar.gz
- 进入目录,配置编译
$ cd lrzsz-0.12.20
$ ./configure --prefix=/usr/local/lrzsz
$ make
$ make install
- 建立软链接
$ cd /usr/bin
$ ln -s /usr/local/lrzsz/bin/lrz rz
$ ln -s /usr/local/lrzsz/bin/lsz sz
- 测试
运行 rz 弹出 SecureCrt上传窗口,用SecureCRT来上传和下载文件。
设置SecureCRT上传和下载的默认目录
options->session options ->Terminal->Xmodem/Zmodem
右栏directory设置上传和下载的目录
使用Zmodem从客户端上传文件到linux服务器
用SecureCRT登陆linux终端
选中你要放置上传文件的路径,在目录下然后输入rz命令,SecureCRT会弹出文件选择对话框,在查找范围中找到你要上传的文件,按Add按钮。然后OK就可以把文件上传到linux上了。
或者在Transfer->Zmodem Upoad list弹出文件选择对话框,选好文件后按Add按钮。然后OK窗口自动关闭。然后在linux下选中存放文件的目录,输入rz命令。liunx就把那个文件上传到这个目录下了。
使用Zmodem下载文件到客户端
$ sz filename
zmodem 接收可以自行启动.下载的文件存放在你设定的默认下载目录下
rz,sz是 Linux/Unix 同 Windows 进行 ZModem 文件传输的命令行工具 , windows 端需要支持ZModem的telnet/ssh客户端,SecureCRT 就可以用 SecureCRT 登陆到 Unix/Linux 主机(telnet或ssh均可)O 运行命令rz,即是接收文件,SecureCRT就会弹出文件选择对话框,选好文件之后关闭对话框,文件就会上传到当前目录 O 运行命令sz file1 file2就是发文件到windows上(保存的目录是可以配置) 比ftp命令方便多了,而且服务器不用再开FTP服务了
Git操作之高手过招
在使用git的过程中,总有一天你会遇到下面的问题:)
这些也是在开发过程中很常见的问题,以下也是作者的经验之谈,有不对的地方还请指出。
最后一次commit信息写错了
如果只是提交信息写错了信息,可以通过以下命令单独修改提交信息
$ git commit --amend
注意: 通过这样的过程修改提交信息后,相当于删除原来的提交,重新提交了一次。所有如果你在修改前已经将错误的那次提交push到服务端,那在修改后就需要通过 git pull 来合并代码(类似于两个分支了)。
通过git log --graph --oneline查看就会发现两个分支合并的痕迹
最后一次commit少添加一个文件
$ git add file1
$ git commit --amend
最后一次commit多添加一个文件
$ git rm --cached file1
$ git commit --amend
移除add过的文件
#方法一
$ git rm --cache [文件名]
#方法二
$ git reset head [文件/文件夹]
回退本地commit(还未push)
这种情况发生在你的本地仓库,可能你add,commit以后发现代码有点问题,打算取消提交,用到下面命令
#只会保留源码(工作区),回退commit(本地仓库)与index(暂存区)到某个版本
$ git reset <commit_id> #默认为 --mixed模式
$ git reset --mixed <commit_id>
#保留源码(工作区)和index(暂存区),只回退commit(本地仓库)到某个版本
$ git reset --soft <commit_id>
#源码(工作区)、commit(本地仓库)与index(暂存区)都回退到某个版本
$ git reset --hard <commit_id>
当然有人在push代码以后,也是用reset –hard回退代码到某个版本之前,但是这样会有一个问题,你线上的代码没有变化。
!!!可以通过 git push –force 将本地的回退推送到服务端,但是除非你很清楚在这么做, 不推荐.
所以,这种情况你要使用下面的方式了。
回退本地commit(已经push)
对于已经把代码push到线上仓库,你回退本地代码其实也想同时回退线上代码,回滚到某个指定的版本,线上,线下代码保持一致.你要用到下面的命令
$ git revert <commit_id>
注意:
- git revert 用于反转提交,执行命令时要求工作树必须是干净的。
- git revert 用一个新的提交来消除一个历时提交所做出的修改
回退单个文件的历史版本
#查看历史版本
git log 1.txt
#回退该文件到指定版本
git reset [commit_id] 1.txt
git checkout 1.txt
#提交
git commit -m "回退1.txt的历史版本"
修改提交历史中的author和email
旧的:author:Old-Author email:old@mail.com
新的:author:New-Author email:new@mail.com
1.在git仓库内创建下面的脚本,如change.sh
# !/bin/sh
git filter-branch --env-filter '
an="$GIT_AUTHOR_NAME"
am="$GIT_AUTHOR_EMAIL"
cn="$GIT_COMMITTER_NAME"
cm="$GIT_COMMITTER_EMAIL"
if [ "$GIT_COMMITTER_EMAIL" = "old@mail.com" ]
then
cn="New-Author"
cm="new@mail.com"
fi
if [ "$GIT_AUTHOR_EMAIL" = "old@mail.com" ]
then
an="New-Author"
am="new@mail.com"
fi
export GIT_AUTHOR_NAME="$an"
export GIT_AUTHOR_EMAIL="$am"
export GIT_COMMITTER_NAME="$cn"
export GIT_COMMITTER_EMAIL="$cm"
'
2.运行脚本
$ sh change.sh
忽略已提交的文件(.iml)
- 删除已提交的文件
# 删除项目中所有的.iml后缀的文件
$ find . -name "*.iml" | xargs rm -f
- 添加
.gitignore文件
*.iml
/**/*.iml
统计某段时间内每个人的提交量
# 查询分支: pgsql-master
# 查询日期: 2023-11-30 ~ 2024-11-04
# 排除 Merge 的 commit: --no-merges
# 按 commit 数量进行排序
git log pgsql-master --since="2023-11-30" --until="2024-11-04" --no-merges --pretty="%an" | sort | uniq -c | sort -nrGit之reset揭秘
本文主要讨论 reset 与 checkout。它们能做很多事情,所以我们要真正理解他们到底在底层做了哪些工作,以便能够恰当的运用它们。
三棵树
理解 reset 和 checkout 的最简方法,就是以 Git 的思维框架(将其作为内容管理器)来管理三棵不同的树。 “树” 在我们这里的实际意思是 “文件的集合”,而不是指特定的数据结构。 (在某些情况下索引看起来并不像一棵树,不过我们现在的目的是用简单的方式思考它。)
| 树 | 描述 |
|---|---|
| HEAD | 上一次提交的快照,下一次提交的父结点 |
| Index | 预期的下一次提交的快照 |
| Working Directory | 沙盒 |
HEAD
HEAD 是当前分支引用的指针,它总是指向该分支上的最后一次提交。 这表示 HEAD 将是下一次提交的父结点。 通常,理解 HEAD 的最简方式,就是将它看做 你的上一次提交 的快照。
其实,查看快照的样子很容易。 下例就显示了 HEAD 快照实际的目录列表,以及其中每个文件的 SHA-1 校验和:
$ git cat-file -p HEAD
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
author Scott Chacon 1301511835 -0700
committer Scott Chacon 1301511835 -0700
initial commit
$ git ls-tree -r HEAD
100644 blob a906cb2a4a904a152... README
100644 blob 8f94139338f9404f2... Rakefile
040000 tree 99f1a6d12cb4b6f19... lib
cat-file 与 ls-tree 是底层命令,它们一般用于底层工作,在日常工作中并不使用。不过它们能帮助我们了解到底发生了什么。
索引(Index)
索引是你的 预期的下一次提交。 我们也会将这个概念引用为 Git 的 “暂存区域”,这就是当你运行 git commit 时 Git 看起来的样子。
Git 将上一次检出到工作目录中的所有文件填充到索引区,它们看起来就像最初被检出时的样子。 之后你会将其中一些文件替换为新版本,接着通过 git commit 将它们转换为树来用作新的提交。
$ git ls-files -s
100644 a906cb2a4a904a152e80877d4088654daad0c859 0 README
100644 8f94139338f9404f26296befa88755fc2598c289 0 Rakefile
100644 47c6340d6459e05787f644c2447d2595f5d3a54b 0 lib/simplegit.rb
再说一次,我们在这里又用到了 ls-files 这个幕后的命令,它会显示出索引当前的样子。
确切来说,索引并非技术上的树结构,它其实是以扁平的清单实现的。不过对我们而言,把它当做树就够了。
工作目录(Working Directory)
最后,你就有了自己的工作目录。 另外两棵树以一种高效但并不直观的方式,将它们的内容存储在 .git 文件夹中。 工作目录会将它们解包为实际的文件以便编辑。 你可以把工作目录当做 沙盒。在你将修改提交到暂存区并记录到历史之前,可以随意更改。
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 files
工作流程
Git 主要的目的是通过操纵这三棵树来以更加连续的状态记录项目的快照。

工作流程
让我们来可视化这个过程:假设我们进入到一个新目录,其中有一个文件。 我们称其为该文件的 v1 版本,将它标记为蓝色。 现在运行
git init,这会创建一个 Git 仓库,其中的 HEAD 引用指向未创建的分支(master 还不存在)。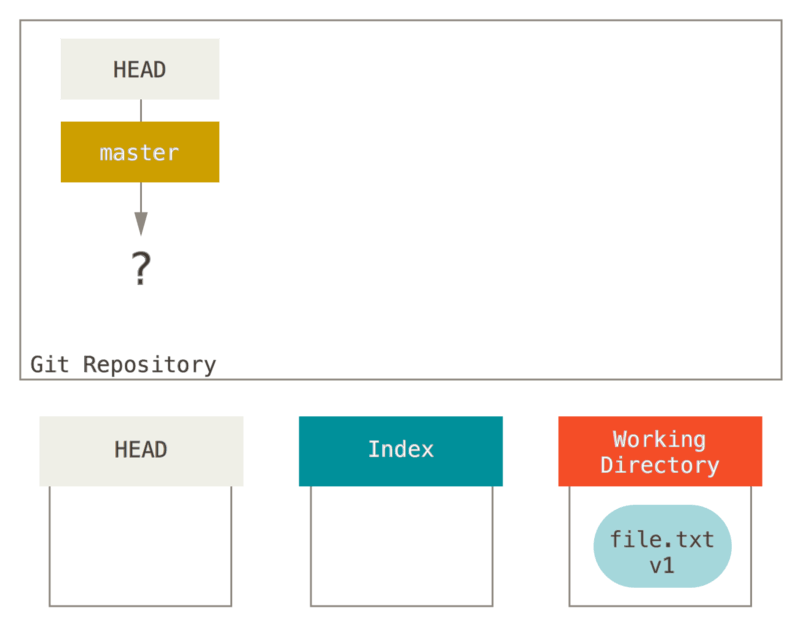
git初始化情况
此时,只有工作目录有内容。
现在我们想要提交这个文件,所以用 git add 来获取工作目录中的内容,并将其复制到索引中。
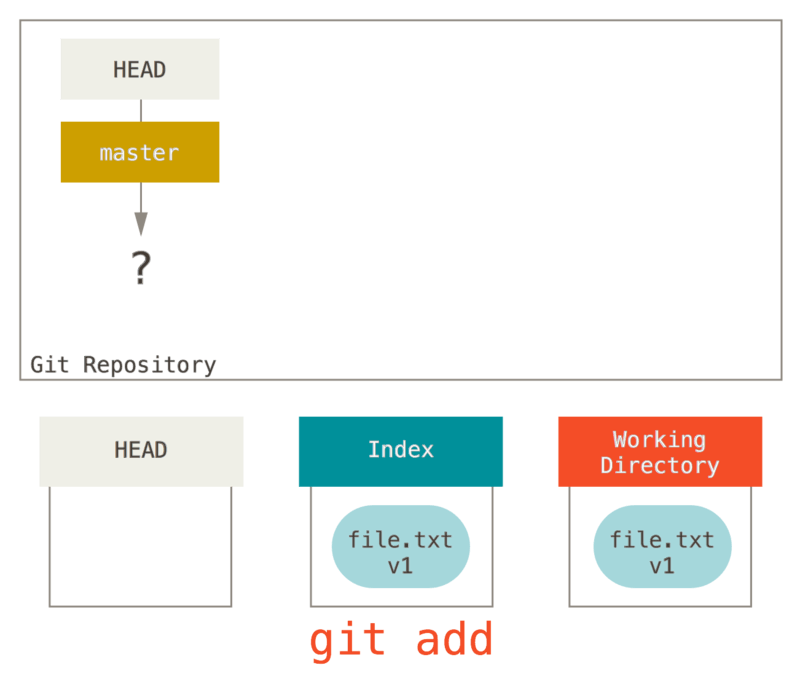
git add之后情况
接着运行
git commit,它首先会移除索引中的内容并将它保存为一个永久的快照,然后创建一个指向该快照的提交对象,最后更新 master 来指向本次提交。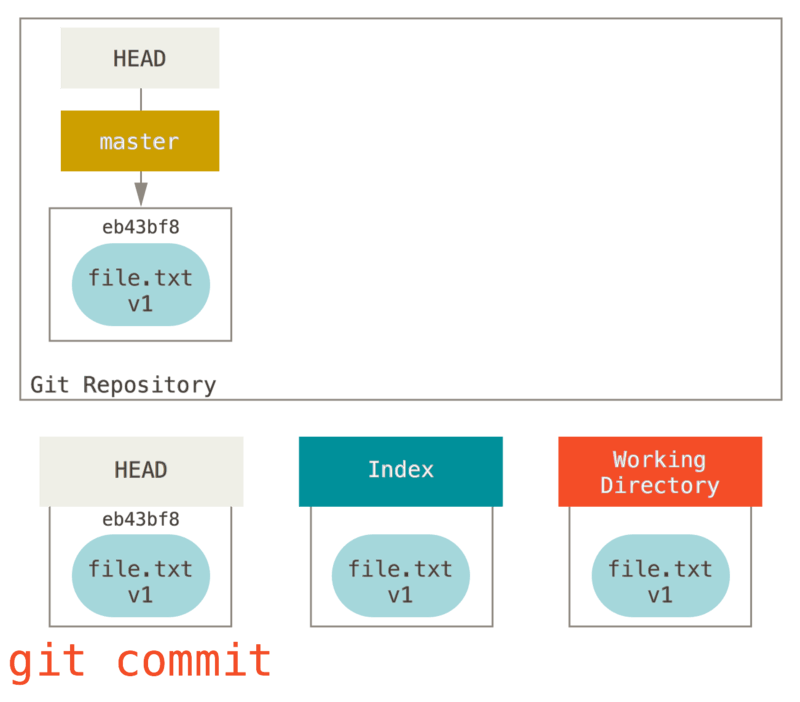
git commit之后情况
此时如果我们运行
git status,会发现没有任何改动,因为现在三棵树完全相同。
现在我们想要对文件进行修改然后提交它。 我们将会经历同样的过程;首先在工作目录中修改文件。 我们称其为该文件的 v2 版本,并将它标记为红色。
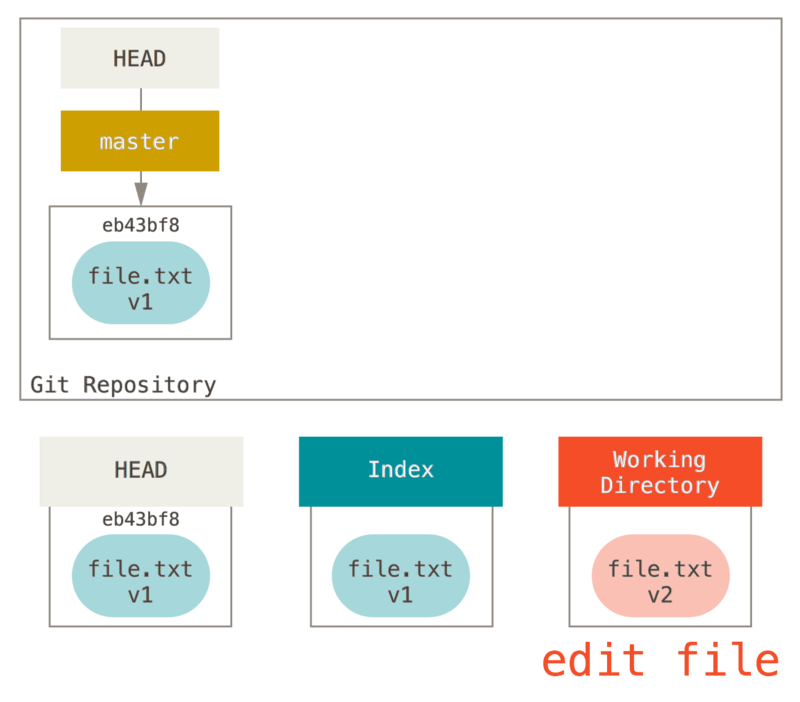
编辑文件
如果现在运行
git status,我们会看到文件显示在 “Changes not staged for commit,” 下面并被标记为红色,因为该条目在索引与工作目录之间存在不同。 接着我们运行 git add 来将它暂存到索引中。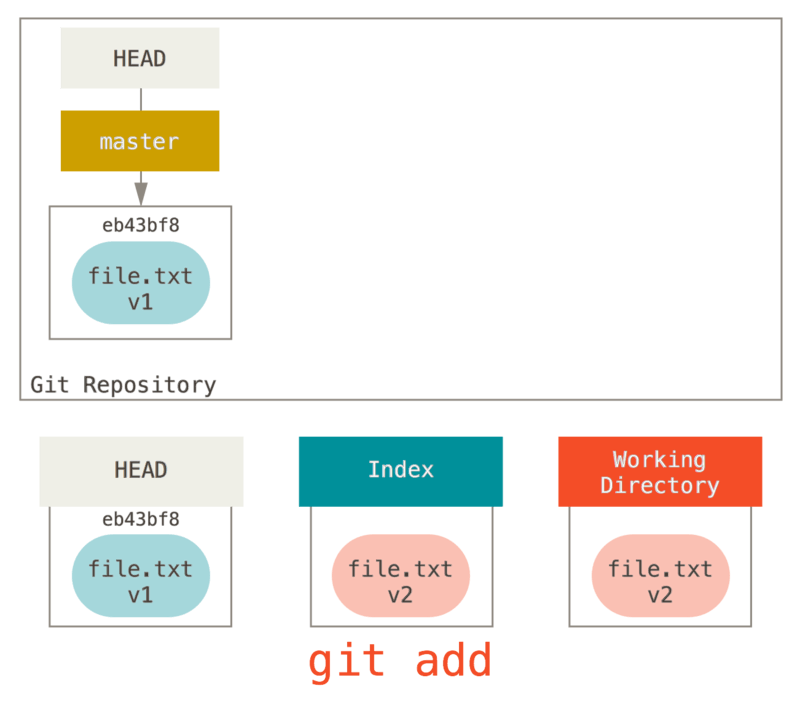
git add之后情况
此时,由于索引和 HEAD 不同,若运行
git status 的话就会看到 “Changes to be committed” 下的该文件变为绿色 ——也就是说,现在预期的下一次提交与上一次提交不同。 最后,我们运行 git commit 来完成提交。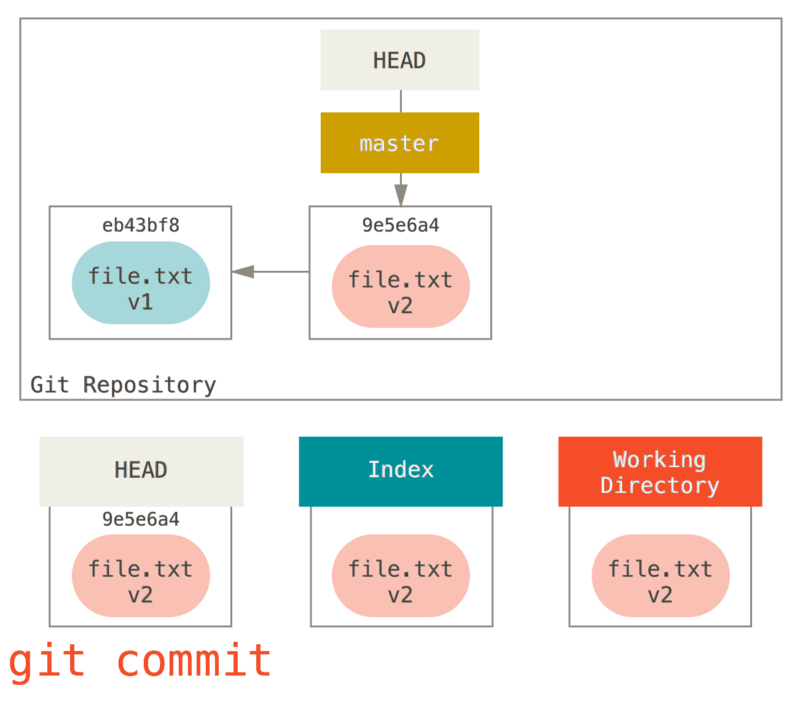
git add之后情况
现在运行
git status 会没有输出,因为三棵树又变得相同了。
切换分支或克隆的过程也类似。 当检出一个分支时,它会修改 HEAD 指向新的分支引用,将 索引 填充为该次提交的快照,然后将 索引 的内容复制到 工作目录 中。
重置的作用
在以下情景中观察 reset 命令会更有意义。
为了演示这些例子,假设我们再次修改了 file.txt 文件并第三次提交它。 现在的历史看起来是这样的:
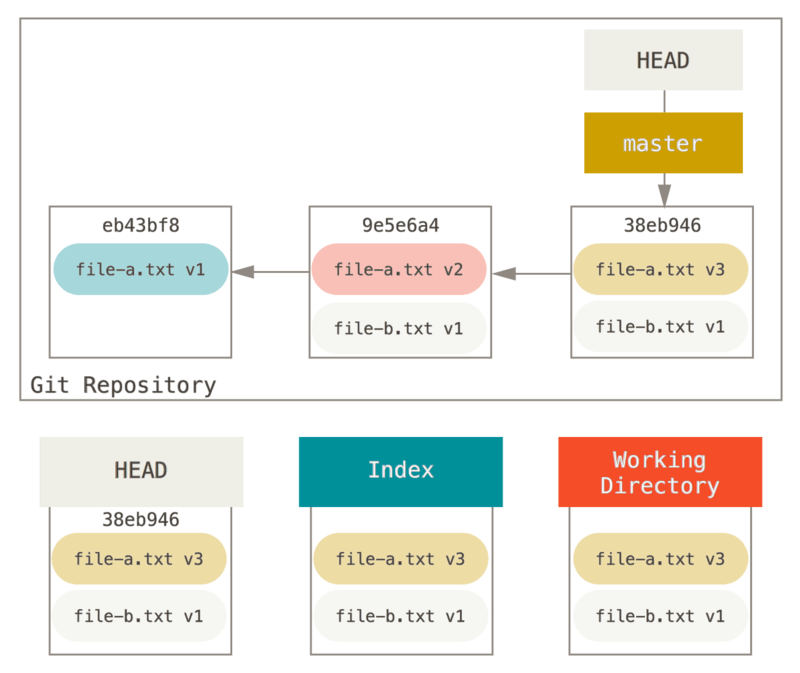
让我们跟着
reset 看看它都做了什么。 它以一种简单可预见的方式直接操纵这三棵树。 它做了三个基本操作。
1.移动 HEAD
reset 做的第一件事是移动 HEAD 的指向。 这与改变 HEAD 自身不同(checkout 所做的);reset 移动 HEAD 指向的分支。 这意味着如果 HEAD 设置为 master 分支(例如,你正在 master 分支上),运行 git reset 9e5e64a 将会使 master 指向 9e5e64a。
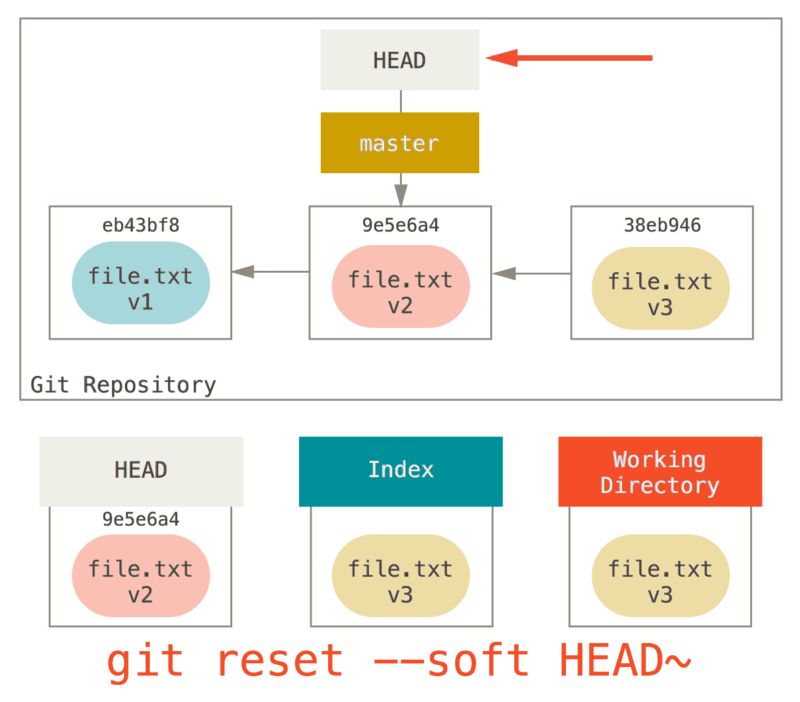
git reset --soft
无论你调用了何种形式的带有一个提交的
reset,它首先都会尝试这样做。 使用 reset --soft,它将仅仅停在那儿。
现在看一眼上图,理解一下发生的事情:它本质上是撤销了上一次 git commit 命令。 当你在运行 git commit 时,Git 会创建一个新的提交,并移动 HEAD 所指向的分支来使其指向该提交。 当你将它 reset 回 HEAD~(HEAD 的父结点)时,其实就是把该分支移动回原来的位置,而不会改变索引和工作目录。 现在你可以更新索引并再次运行 git commit 来完成 git commit --amend 所要做的事情了。
2.更新索引(–mixed)
注意,如果你现在运行 git status 的话,就会看到新的 HEAD 和以绿色标出的它和索引之间的区别。
接下来,reset 会用 HEAD 指向的当前快照的内容来更新索引。
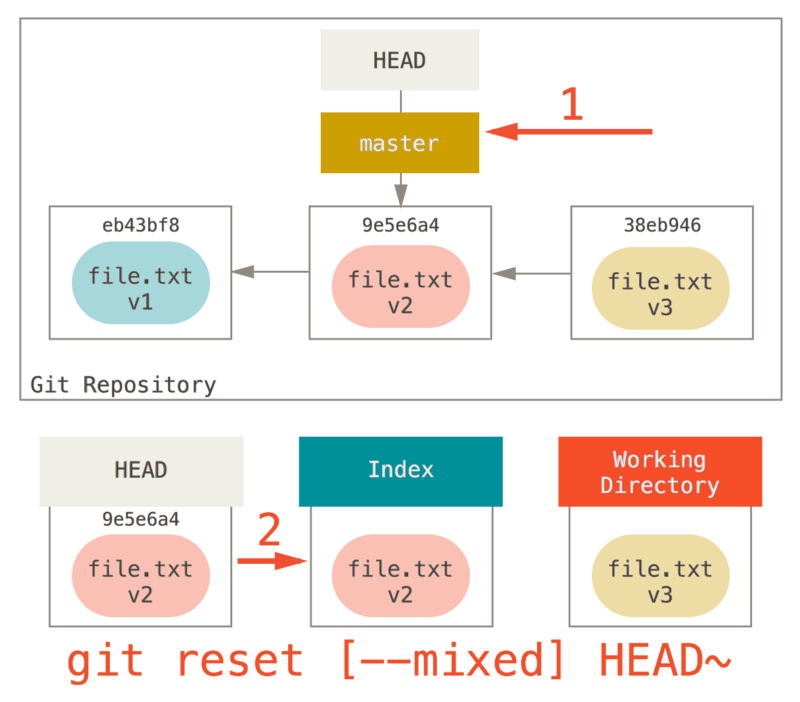
git reset --mixed
如果指定
--mixed 选项,reset 将会在这时停止。 这也是默认行为,所以如果没有指定任何选项(在本例中只是 git reset HEAD~),这就是命令将会停止的地方。
现在再看一眼上图,理解一下发生的事情:它依然会撤销一上次 提交,但还会 取消暂存 所有的东西。 于是,我们回滚到了所有 git add 和 git commit 的命令执行之前。
3.更新工作目录
reset 要做的的第三件事情就是让工作目录看起来像索引。 如果使用 –hard 选项,它将会继续这一步。
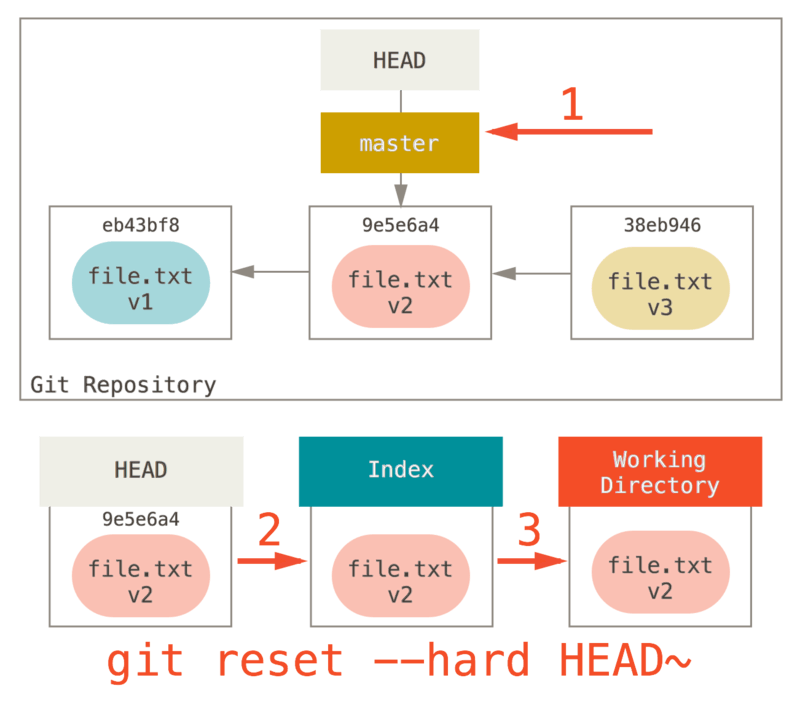
git reset --hard
现在让我们回想一下刚才发生的事情。 你撤销了最后的提交、
git add 和 git commit 命令以及工作目录中的所有工作。
必须注意,--hard 标记是 reset 命令唯一的危险用法,它也是 Git 会真正地销毁数据的仅有的几个操作之一。 其他任何形式的 reset 调用都可以轻松撤消,但是 --hard 选项不能,因为它强制覆盖了工作目录中的文件。 在这种特殊情况下,我们的 Git 数据库中的一个提交内还留有该文件的 v3 版本,我们可以通过 reflog 来找回它。但是若该文件还未提交,Git 仍会覆盖它从而导致无法恢复。
回顾
reset 命令会以特定的顺序重写这三棵树,在你指定以下选项时停止:
- 移动 HEAD 分支的指向 (若指定了
--soft,则到此停止) - 使索引看起来像 HEAD (不带参数或
--mixed,则到此停止) - 使工作目录看起来像索引 (指定了
--hard)
通过路径来重置
前面讲述了 reset 基本形式的行为,不过你还可以给它提供一个作用路径。 若指定了一个路径,reset 将会跳过第 1 步,并且将它的作用范围限定为指定的文件或文件集合。 这样做自然有它的道理,因为 HEAD 只是一个指针,你无法让它同时指向两个提交中各自的一部分。 不过索引和工作目录 可以部分更新,所以重置会继续进行第 2、3 步。
现在,假如我们运行 git reset file.txt (这其实是 git reset --mixed HEAD file.txt 的简写形式,因为你既没有指定一个提交的 SHA-1 或分支,也没有指定 --soft 或 --hard),它会:
- 移动 HEAD 分支的指向 (已跳过)
- 让索引看起来像 HEAD (到此处停止)
所以它本质上只是将 file.txt 从 HEAD 复制到索引中。
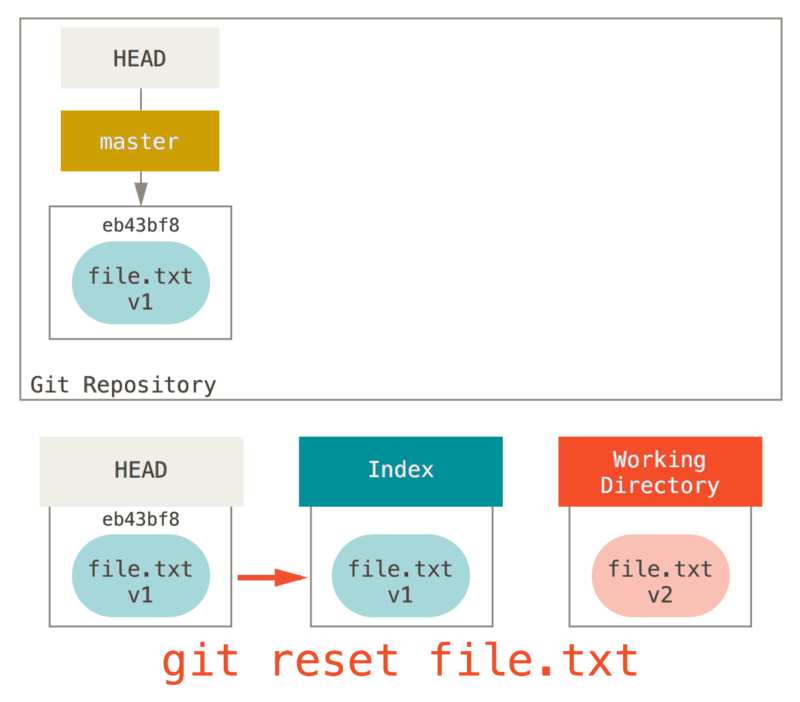
git reset
它还有 取消暂存文件 的实际效果。 如果我们查看该命令的示意图,然后再想想
git add 所做的事,就会发现它们正好相反。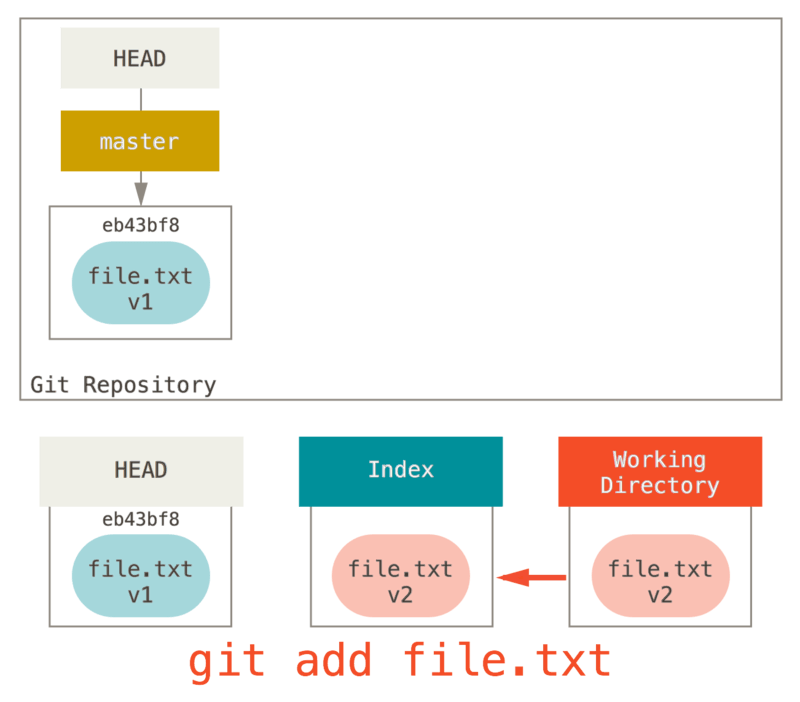
git add
这就是为什么 git status 命令的输出会建议运行此命令来取消暂存一个文件。 (查看 取消暂存的文件 来了解更多。)
我们可以不让 Git 从 HEAD 拉取数据,而是通过具体指定一个提交来拉取该文件的对应版本。 我们只需运行类似于 git reset eb43bf file.txt 的命令即可。
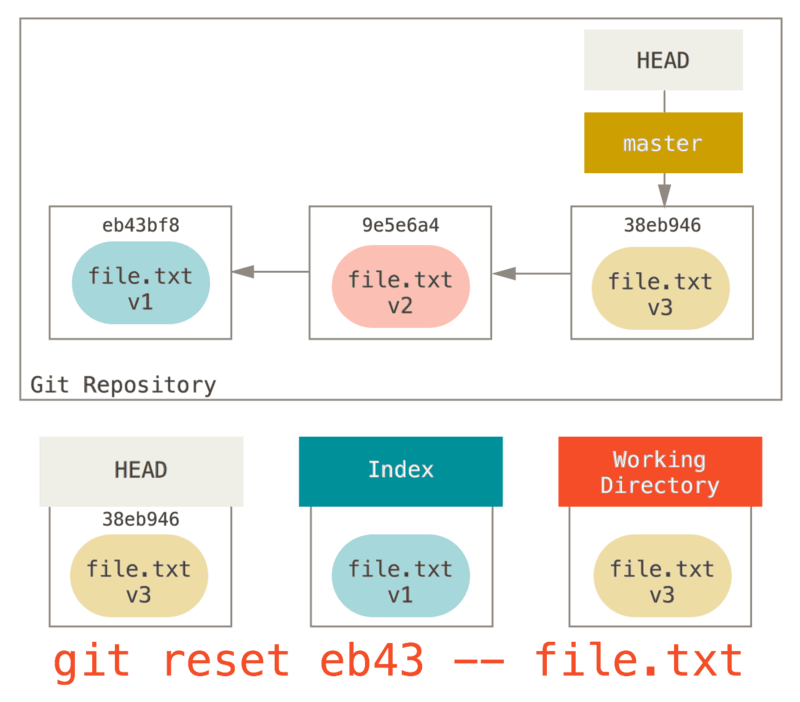
git reset eb43 -- file.txt
它其实做了同样的事情,也就是把工作目录中的文件恢复到 v1 版本,运行
git add 添加它,然后再将它恢复到 v3 版本(只是不用真的过一遍这些步骤)。 如果我们现在运行 git commit,它就会记录一条“将该文件恢复到 v1 版本”的更改,尽管我们并未在工作目录中真正地再次拥有它。
还有一点同 git add 一样,就是 reset 命令也可以接受一个 --patch 选项来一块一块地取消暂存的内容。 这样你就可以根据选择来取消暂存或恢复内容了。
压缩
我们来看看如何利用这种新的功能来做一些有趣的事情 - 压缩提交。
假设你的一系列提交信息中有 “oops.”、“WIP” 和 “forgot this file”, 聪明的你就能使用 reset 来轻松快速地将它们压缩成单个提交,也显出你的聪明。 (压缩提交 展示了另一种方式,不过在本例中用 reset 更简单。)
假设你有一个项目,第一次提交中有一个文件,第二次提交增加了一个新的文件并修改了第一个文件,第三次提交再次修改了第一个文件。 由于第二次提交是一个未完成的工作,因此你想要压缩它。
git reset --hard
那么可以运行
git reset --soft HEAD~2 来将 HEAD 分支移动到一个旧一点的提交上(即你想要保留的第一个提交):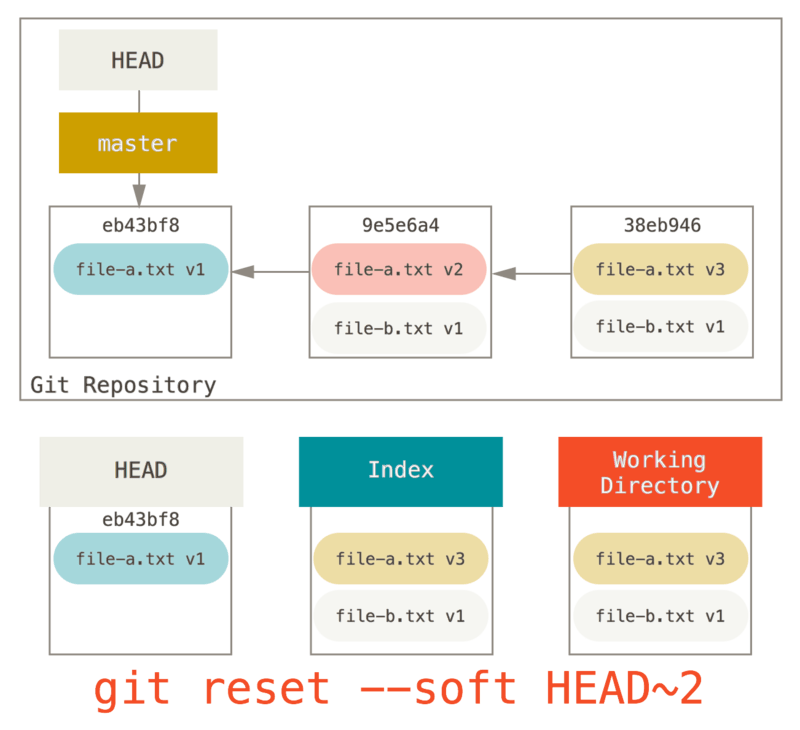
git reset --soft HEAD~2
然后只需再次运行
git commit: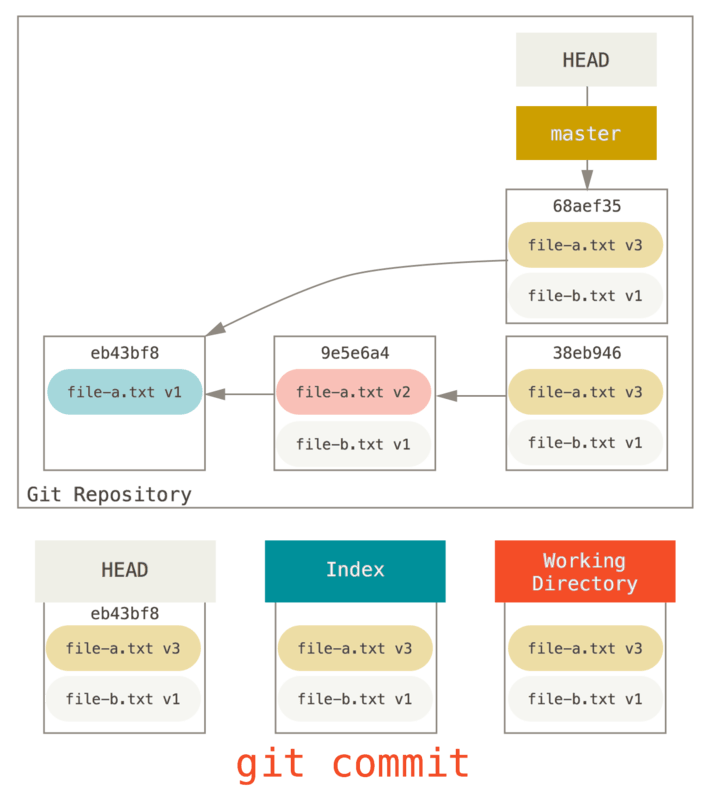
git commit
现在你可以查看可到达的历史,即将会推送的历史,现在看起来有个 v1 版
file-a.txt 的提交,接着第二个提交将 file-a.txt 修改成了 v3 版并增加了 file-b.txt。 包含 v2 版本的文件已经不在历史中了。
checkout
最后,你大概还想知道 checkout 和 reset 之间的区别。 和 reset 一样,checkout 也操纵三棵树,不过它有一点不同,这取决于你是否传给该命令一个文件路径。
不带路径
运行 git checkout [branch] 与运行 git reset --hard [branch] 非常相似,它会更新所有三棵树使其看起来像 [branch],不过有两点重要的区别。
首先不同于 reset --hard,checkout 对工作目录是安全的,它会通过检查来确保不会将已更改的文件吹走。 其实它还更聪明一些。它会在工作目录中先试着简单合并一下,这样所有_还未修改过的_文件都会被更新。 而 reset --hard 则会不做检查就全面地替换所有东西。
第二个重要的区别是如何更新 HEAD。 reset 会移动 HEAD 分支的指向,而 checkout 只会移动 HEAD 自身来指向另一个分支。
例如,假设我们有 master 和 develop 分支,它们分别指向不同的提交;我们现在在 develop 上(所以 HEAD 指向它)。 如果我们运行 git reset master,那么 develop 自身现在会和 master 指向同一个提交。 而如果我们运行 git checkout master 的话,develop 不会移动,HEAD 自身会移动。 现在 HEAD 将会指向 master。
所以,虽然在这两种情况下我们都移动 HEAD 使其指向了提交 A,但_做法_是非常不同的。 reset 会移动 HEAD 分支的指向,而 checkout 则移动 HEAD 自身。
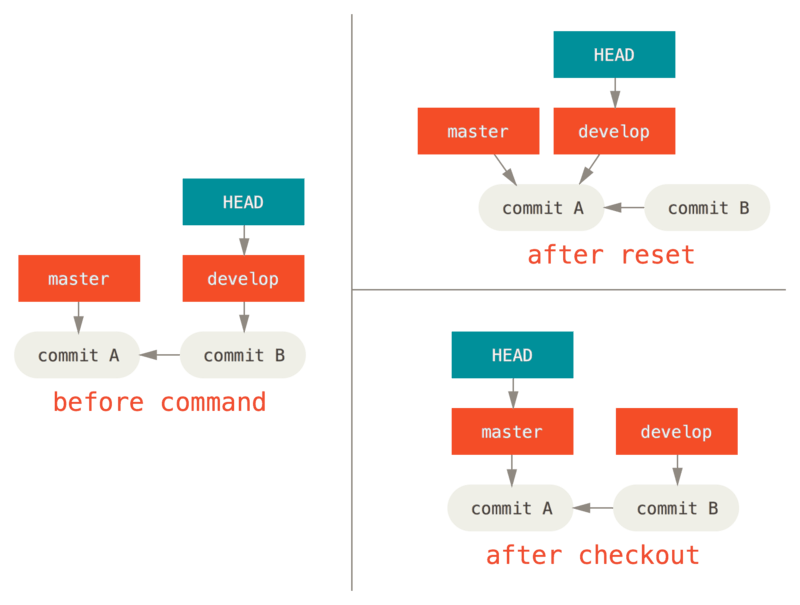
带路径
运行 checkout 的另一种方式就是指定一个文件路径,这会像 reset 一样不会移动 HEAD。 它就像 git reset [branch] file 那样用该次提交中的那个文件来更新索引,但是它也会覆盖工作目录中对应的文件。 它就像是 git reset --hard [branch] file(如果 reset 允许你这样运行的话)- 这样对工作目录并不安全,它也不会移动 HEAD。
此外,同 git reset 和 git add 一样,checkout 也接受一个 –patch 选项,允许你根据选择一块一块地恢复文件内容。
总结
希望你现在熟悉并理解了 reset 命令,不过关于它和 checkout 之间的区别,你可能还是会有点困惑,毕竟不太可能记住不同调用的所有规则。
下面的速查表列出了命令对树的影响。 “HEAD” 一列中的 “REF” 表示该命令移动了 HEAD 指向的分支引用,而‘HEAD’ 则表示只移动了 HEAD 自身。 特别注意 WD Safe? 一列 - 如果它标记为 NO,那么运行该命令之前请考虑一下。
| **head** | **index** | **workdir** | **wd safe** | |
| **commit level** | ||||
| `reset --soft [commit]` | ref | no | no | yes |
| `reset [commit]` | ref | yes | no | yes |
| `reset --hard [commit]` | ref | yes | yes | no |
| `checkout [commit]` | head | yes | yes | yes |
| **file level** | ||||
| `reset (commit) [file]` | no | yes | no | yes |
| `checkout (commit) [file]` | no | yes | yes | no |
linux命令: gzip
减少文件大小有两个明显的好处,一是可以减少存储空间,二是通过网络传输文件时,可以减少传输的时间。gzip是在Linux系统中经常使用的一个对文件进行压缩和解压缩的命令,既方便又好用。gzip不仅可以用来压缩大的、较少使用的文件以节省磁盘空间,还可以和tar命令一起构成Linux操作系统中比较流行的压缩文件格式。据统计,gzip命令对文本文件有60%~70%的压缩率。
命令格式
$ gzip [参数] [文件或者目录]
命令功能
gzip是个使用广泛的压缩程序,文件经它压缩过后,其名称后面会多出”.gz”的扩展名。
命令参数
| 参数 | 描述 |
|---|---|
| -a或–ascii | 使用ASCII文字模式。 |
| -c或–stdout或–to-stdout | 把压缩后的文件输出到标准输出设备,不去更动原始文件。 |
| -d或–decompress或—-uncompress | 解开压缩文件。 |
| -f或–force | 强行压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接。 |
| -h或–help | 在线帮助。 |
| -l或–list | 列出压缩文件的相关信息。 |
| -L或–license | 显示版本与版权信息。 |
| -n或–no-name | 压缩文件时,不保存原来的文件名称及时间戳记。 |
| -N或–name | 压缩文件时,保存原来的文件名称及时间戳记。 |
| -q或–quiet | 不显示警告信息 |
| -r或–recursive | 递归处理,将指定目录下的所有文件及子目录一并处理。 |
| -S<压缩字尾字符串>或—-suffix<压缩字尾字符串> | 更改压缩字尾字符串。 |
| -t或–test | 测试压缩文件是否正确无误。 |
| -v或–verbose | 显示指令执行过程。 |
| -V或–version | 显示版本信息。 |
| -num | 用指定的数字num调整压缩的速度,-1或–fast表示最快压缩方法(低压缩比),-9或–best表示最慢压缩方法(高压缩比)。系统缺省值为6。 |
命令实例
例一:把test目录下的每个文件压缩成.gz文件
# 忽略目录,只打包其中文件
$ gzip *
例二:把例1中每个压缩的文件解压,并列出详细的信息
$ gzip -dv *
例三:详细显示例1中每个压缩的文件的信息,并不解压
$ gzip -l *
例四:压缩一个tar备份文件,此时压缩文件的扩展名为.tar.gz
$ gzip -r log.tar
例五:递归的压缩目录
$ gzip -rv test6
例六:递归地解压目录
$ gzip -dr test6linux命令: /etc/group文件详解
/etc/group文件与/etc/passwd和/etc/shadow文件都是关于系统管理员对用户和用户组管理时相关的文件。linux /etc/group文件是有关于系统管理员对用户和用户组管理的文件,linux用户组的所有信息都存放在/etc/group文件中。具有某种共同特征的用户集合起来就是用户组(Group)。用户组(Group)配置文件主要有 /etc/group和/etc/gshadow,其中/etc/gshadow是/etc/group的加密信息文件。
将用户分组是Linux系统中对用户进行管理及控制访问权限的一种手段。每个用户都属于某个用户组;一个组中可以有多个用户,一个用户也可以属于不 同的组。当一个用户同时是多个组中的成员时,在/etc/passwd文件中记录的是用户所属的主组,也就是登录时所属的默认组,而其他组称为附加组。
用户组的所有信息都存放在/etc/group文件中。此文件的格式是由冒号(:)隔开若干个字段,这些字段具体如下:
组名:口令:组标识号:组内用户列表
解释
组名: 组名是用户组的名称,由字母或数字构成。与/etc/passwd中的登录名一样,组名不应重复。
口令: 口令字段存放的是用户组加密后的口令字。一般Linux系统的用户组都没有口令,即这个字段一般为空,或者是*。
组标识号: 组标识号与用户标识号类似,也是一个整数,被系统内部用来标识组。别称GID.
组内用户列表: 是属于这个组的所有用户的列表,不同用户之间用逗号(,)分隔。这个用户组可能是用户的主组,也可能是附加组。
使用实例
$ cat /etc/group
说明: 我们以root:x:0:root,linuxsir 为例: 用户组root,x是密码段,表示没有设置密码,GID是0,root用户组下包括root、linuxsir以及GID为0的其它用户。
linux命令: top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。下面详细介绍它的使用方法。top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定。
命令格式
$ top [参数]
命令功能
显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等
命令参数
| 参数 | 描述 |
|---|---|
| -b | 批处理 |
| -c | 显示完整的治命令 |
| -I | 忽略失效过程 |
| -s | 保密模式 |
| -S | 累积模式 |
| -i<时间> | 设置间隔时间 |
| -u<用户名> | 指定用户名 |
| -p<进程号> | 指定进程 |
| -n<次数> | 循环显示的次数 |
top交互命令
在top 命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了s 选项, 其中一些命令可能会被屏蔽。
| 参数 | 描述 |
|---|---|
| h | 显示帮助画面,给出一些简短的命令总结说明 |
| k | 终止一个进程。 |
| i | 忽略闲置和僵死进程。这是一个开关式命令 |
| q | 退出程序 |
| r | 重新安排一个进程的优先级别 |
| S | 切换到累计模式 |
| s | 改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s |
| f或者F | 从当前显示中添加或者删除项目 |
| o或者O | 改变显示项目的顺序 |
| l | 切换显示平均负载和启动时间信息 |
| m | 切换显示内存信息 |
| t | 切换显示进程和CPU状态信息 |
| c | 切换显示命令名称和完整命令行 |
| M | 根据驻留内存大小进行排序 |
| P | 根据CPU使用百分比大小进行排序 |
| T | 根据时间/累计时间进行排序 |
| W | 将当前设置写入~/.toprc文件中 |
使用实例
例一:显示进程信息
$ top
top讲解

top命令
其他技巧
- 数字
1,可监控每个逻辑CPU的状况 - 键盘
b(打开/关闭加亮效果),运行状态的进程 - 键盘
x打开/关闭排序列的加亮效果 shift + >或shift + <改变排序列
例二:显示 完整命令
$ top -c
例三:以批处理模式显示程序信息
$ top -b
例四:以累积模式显示程序信息
$ top -S
例五:设置信息更新次数
# 表示更新两次后终止更新显示
$ top -n 2
例六:设置信息更新时间
# 表示更新周期为3秒
$ top -d 3
例七:显示指定的进程信息
$ top -p 574linux命令: vmstat
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。他是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。vmstat 工具提供了一种低开销的系统性能观察方式。因为 vmstat 本身就是低开销工具,在非常高负荷的服务器上,你需要查看并监控系统的健康情况,在控制窗口还是能够使用vmstat 输出结果。在学习vmstat命令前,我们先了解一下Linux系统中关于物理内存和虚拟内存相关信息。
物理内存和虚拟内存区别
我们知道,直接从物理内存读写数据要比从硬盘读写数据要快的多,因此,我们希望所有数据的读取和写入都在内存完成,而内存是有限的,这样就引出了物理内存与虚拟内存的概念。
物理内存就是系统硬件提供的内存大小,是真正的内存,相对于物理内存,在linux下还有一个虚拟内存的概念,虚拟内存就是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。
作为物理内存的扩展,linux会在物理内存不足时,使用交换分区的虚拟内存,更详细的说,就是内核会将暂时不用的内存块信息写到交换空间,这样以来,物理内存得到了释放,这块内存就可以用于其它目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
linux的内存管理采取的是分页存取机制,为了保证物理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。
要深入了解linux内存运行机制,需要知道下面提到的几个方面:
首先,Linux系统会不时的进行页面交换操作,以保持尽可能多的空闲物理内存,即使并没有什么事情需要内存,Linux也会交换出暂时不用的内存页面。这可以避免等待交换所需的时间。
其次,linux进行页面交换是有条件的,不是所有页面在不用时都交换到虚拟内存,linux内核根据”最近最经常使用“算法,仅仅将一些不经常使用的页面文件交换到虚拟内存,有时我们会看到这么一个现象:linux物理内存还有很多,但是交换空间也使用了很多。其实,这并不奇怪,例如,一个占用很大内存的进程运行时,需要耗费很多内存资源,此时就会有一些不常用页面文件被交换到虚拟内存中,但后来这个占用很多内存资源的进程结束并释放了很多内存时,刚才被交换出去的页面文件并不会自动的交换进物理内存,除非有这个必要,那么此刻系统物理内存就会空闲很多,同时交换空间也在被使用,就出现了刚才所说的现象了。关于这点,不用担心什么,只要知道是怎么一回事就可以了。
最后,交换空间的页面在使用时会首先被交换到物理内存,如果此时没有足够的物理内存来容纳这些页面,它们又会被马上交换出去,如此以来,虚拟内存中可能没有足够空间来存储这些交换页面,最终会导致linux出现假死机、服务异常等问题,linux虽然可以在一段时间内自行恢复,但是恢复后的系统已经基本不可用了。
因此,合理规划和设计linux内存的使用,是非常重要的。
虚拟内存原理:
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
命令格式
$ vmstat [-a] [-n] [-S unit] [delay [ count]]
$ vmstat [-s] [-n] [-S unit]
$ vmstat [-m] [-n] [delay [ count]]
$ vmstat [-d] [-n] [delay [ count]]
$ vmstat [-p disk partition] [-n] [delay [ count]]
$ vmstat [-f]
$ vmstat [-V]
命令功能
用来显示虚拟内存的信息
命令参数
| 命令 | 描述 |
|---|---|
| -a | 显示活跃和非活跃内存 |
| -f | 显示从系统启动至今的fork数量 |
| -m | 显示slabinfo |
| -n | 只在开始时显示一次各字段名称 |
| -s | 显示内存相关统计信息及多种系统活动数量 |
| delay | 刷新时间间隔。如果不指定,只显示一条结果 |
| count | 刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷 |
| -d | 显示磁盘相关统计信息 |
| -p | 显示指定磁盘分区统计信息 |
| -S | 使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes) |
| -V | 显示vmstat版本信息 |
使用实例
例一:显示虚拟内存使用情况
$ vmstat
procs -----------memory---------- ---swap-- -----io--- --system--- -----cpu---
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7108340 129544 3155916 0 0 184 53 203 995 4 1 95 0 0
说明:
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数系统:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间
备注: 如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。如果pi,po 长期不等于0,表示内存不足。如果disk 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。Linux在具有高稳定性、可靠性的同时,具有很好的可伸缩性和扩展性,能够针对不同的应用和硬件环境调整,优化出满足当前应用需要的最佳性能。因此企业在维护Linux系统、进行系统调优时,了解系统性能分析工具是至关重要的。
命令:vmstat 5 5
表示在5秒时间内进行5次采样。将得到一个数据汇总他能够反映真正的系统情况。
例二:显示活跃和非活跃内存
$ vmstat -a 2 5
说明:
使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同。
Memory(内存):
inact: 非活跃内存大小(当使用-a选项时显示)
active: 活跃的内存大小(当使用-a选项时显示)
例三:查看系统已经fork了多少次
$ vmstat -f
说明:
这个数据是从/proc/stat中的processes字段里取得的
例四:查看内存使用的详细信息
$ vmstat -s
说明:
这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat。
例五:查看磁盘的读/写
$ vmstat -d
说明:
这些信息主要来自于/proc/diskstats.
merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作.
例六:查看/dev/sda1磁盘的读/写
$ vmstat -p /dev/sda1
说明:
这些信息主要来自于/proc/diskstats。
reads:来自于这个分区的读的次数。
read sectors:来自于这个分区的读扇区的次数。
writes:来自于这个分区的写的次数。
requested writes:来自于这个分区的写请求次数。
例七:查看系统的slab信息
$ vmstat -m
说明:
这组信息来自于/proc/slabinfo。
slab:由于内核会有许多小对象,这些对象构造销毁十分频繁,比如i-node,dentry,这些对象如果每次构建的时候就向内存要一个页(4kb),而其实只有几个字节,这样就会非常浪费,为了解决这个问题,就引入了一种新的机制来处理在同一个页框中如何分配小存储区,而slab可以对小对象进行分配,这样就不用为每一个对象分配页框,从而节省了空间,内核对一些小对象创建析构很频繁,slab对这些小对象进行缓冲,可以重复利用,减少内存分配次数。
linux命令: iostat
Linux系统中的 iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。iostat属于sysstat软件包。可以用yum install sysstat 直接安装。
命令格式
$ iostat [参数][时间][次数]
命令功能
通过iostat方便查看CPU、网卡、tty设备、磁盘、CD-ROM 等等设备的活动情况, 负载信息。
命令参数
| 命令 | 描述 |
|---|---|
| -C | 显示CPU使用情况 |
| -d | 显示磁盘使用情况 |
| -k | 以 KB 为单位显示 |
| -m | 以 M 为单位显示 |
| -N | 显示磁盘阵列(LVM) 信息 |
| -n | 显示 NFS 使用情况 |
| -p[磁盘] | 显示磁盘和分区的情况 |
| -t | 显示终端和CPU的信息 |
| -x | 显示详细信息 |
| -V | 显示版本信息 |
使用实例
例一:显示所有设备负载情况
$ iostat
Linux 3.10.0-327.el7.x86_64 (s88) 2017年01月22日 _x86_64_ (24 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.62 0.00 0.20 1.46 0.00 97.72
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 64.59 1726.21 255.56 3159941 467823
dm-0 3.55 141.11 4.46 258319 8162
dm-1 0.10 0.83 0.00 1520 0
dm-2 0.10 2.78 1.14 5080 2082
dm-3 60.44 1565.98 248.84 2866640 455511
dm-4 27.54 463.29 105.38 848088 192897
dm-5 1.25 25.57 17.57 46804 32170
dm-6 0.64 12.86 2.07 23535 3786
dm-7 4.14 80.43 36.60 147240 67004
dm-8 1.13 20.52 2.42 37566 4428
dm-9 1.13 21.18 2.40 38766 4396
dm-10 1.15 21.35 2.41 39082 4412
dm-11 0.70 14.40 2.21 26355 4043
dm-12 1.42 22.42 6.85 41035 12541
dm-13 0.46 12.17 1.25 22275 2289
dm-14 1.15 20.47 2.42 37470 4432
dm-15 8.28 101.07 16.51 185018 30220
dm-16 1.10 20.02 2.45 36646 4488
dm-17 1.81 29.08 4.15 53232 7591
dm-18 0.68 18.40 1.43 33689 2611
dm-19 2.33 43.89 4.63 80340 8483
说明:
cpu属性值说明:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。备注:如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。disk属性值说明:
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度。
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比备注:如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
例二:定时显示所有信息
# 每隔 2秒刷新显示,且显示3次
$ iostat 2 3
例三:显示指定磁盘信息
$ iostat -d sda1
例四:显示tty和Cpu信息
$ iostat -t
例五:以M为单位显示所有信息
$ iostat -m
例六:查看TPS和吞吐量信息
$ iostat -d -k 1 1
说明:
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;
这些单位都为Kilobytes。
上面的例子中,我们可以看到磁盘sda以及它的各个分区的统计数据,当时统计的磁盘总TPS是22.73,下面是各个分区的TPS。(因为是瞬间值,所以总TPS并不严格等于各个分区TPS的总和)
例七:查看设备使用率(%util)、响应时间(await)
$ iostat -d -x -k 1 1
说明:
rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数.即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数.即 delta(wio)/s
rsec/s: 每秒读扇区数.即 delta(rsect)/s
wsec/s: 每秒写扇区数.即 delta(wsect)/s
rkB/s: 每秒读K字节数.是 rsect/s 的一半,因为每扇区大小为512字节.(需要计算)
wkB/s: 每秒写K字节数.是 wsect/s 的一半.(需要计算)
avgrq-sz:平均每次设备I/O操作的数据大小 (扇区).delta(rsect+wsect)/delta(rio+wio)
avgqu-sz:平均I/O队列长度.即 delta(aveq)/s/1000 (因为aveq的单位为毫秒).
await: 平均每次设备I/O操作的等待时间 (毫秒).即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒).即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的,即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait。
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)。
另外 await 的参数也要多和 svctm 来参考。差的过高就一定有 IO 的问题。
avgqu-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小。如果数据拿的大,才IO 的数据会高。也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s。也就是讲,读定速度是这个来决定的。
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。形象的比喻:
r/s+w/s 类似于交款人的总数
平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
平均服务时间(svctm)类似于收银员的收款速度
平均等待时间(await)类似于平均每人的等待时间
平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
I/O 操作率 (%util)类似于收款台前有人排队的时间比例
设备IO操作:总IO(io)/s = r/s(读) +w/s(写) =1.46 + 25.28=26.74
平均每次设备I/O操作只需要0.36毫秒完成,现在却需要10.57毫秒完成,因为发出的 请求太多(每秒26.74个),假如请求时同时发出的,可以这样计算平均等待时间:
平均等待时间=单个I/O服务器时间*(1+2+…+请求总数-1)/请求总数
每秒发出的I/0请求很多,但是平均队列就4,表示这些请求比较均匀,大部分处理还是比较及时。
例八:查看cpu状态
$ iostat -c 1 3linux命令: ifconfig
非常熟悉windows的ipconfig命令,它被用来获取网络接口配置信息并对此进行修改。Linux系统拥有一个类似的工具,也就是ifconfig(interfaces config)。通常需要以root身份登录或使用sudo以便在Linux机器上使用ifconfig工具。依赖于ifconfig命令中使用一些选项属性,ifconfig工具不仅可以被用来简单地获取网络接口配置信息,还可以修改这些配置。
命令格式
$ ifconfig [网络设备] [参数]
命令功能
ifconfig 命令用来查看和配置网络设备。当网络环境发生改变时可通过此命令对网络进行相应的配置。
注意: 用ifconfig命令配置的网卡信息,在网卡重启后机器重启后,配置就不存在。要想将上述的配置信息永远的存的电脑里,那就要修改网卡的配置文件了。
命令参数
| 命令 | 描述 |
|---|---|
| up | 启动指定网络设备/网卡 |
| down | 关闭指定网络设备/网卡。该参数可以有效地阻止通过指定接口的IP信息流,如果想永久地关闭一个接口,我们还需要从核心路由表中将该接口的路由信息全部删除 |
| arp | 设置指定网卡是否支持ARP协议 |
| -promisc | 设置是否支持网卡的promiscuous模式,如果选择此参数,网卡将接收网络中发给它所有的数据包 |
| -allmulti | 设置是否支持多播模式,如果选择此参数,网卡将接收网络中所有的多播数据包 |
| -a | 显示全部接口信息 |
| -s | 显示摘要信息(类似于 netstat -i) |
| add | 给指定网卡配置IPv6地址 |
| del | 删除指定网卡的IPv6地址 |
| <硬件地址> | 配置网卡最大的传输单元 |
| mtu<字节数> | 设置网卡的最大传输单元 (bytes) |
| netmask<子网掩码> | 设置网卡的子网掩码。掩码可以是有前缀0x的32位十六进制数,也可以是用点分开的4个十进制数。如果不打算将网络分成子网,可以不管这一选项;如果要使用子网,那么请记住,网络中每一个系统必须有相同子网掩码 |
| tunel | 建立隧道 |
| dstaddr | 设定一个远端地址,建立点对点通信 |
| -broadcast<地址> | 为指定网卡设置广播协议 |
| -pointtopoint<地址> | 为网卡设置点对点通讯协议 |
| multicast | 为网卡设置组播标志 |
| address | 为网卡设置IPv4地址 |
| txqueuelen<长度> | 为网卡设置传输列队的长度 |
使用实例
例一:显示网络设备信息(激活状态的)
$ ifconfig
说明:
eth0 表示第一块网卡, 其中 HWaddr 表示网卡的物理地址,可以看到目前这个网卡的物理地址(MAC地址)是 00:50:56:BF:26:20
inet addr 用来表示网卡的IP地址,此网卡的 IP地址是 192.168.120.204,广播地址, Bcast:192.168.120.255,掩码地址Mask:255.255.255.0
lo 是表示主机的回坏地址,这个一般是用来测试一个网络程序,但又不想让局域网或外网的用户能够查看,只能在此台主机上运行和查看所用的网络接口。比如把 HTTPD服务器的指定到回坏地址,在浏览器输入 127.0.0.1 就能看到你所架WEB网站了。但只是您能看得到,局域网的其它主机或用户无从知道。
第一行:连接类型:Ethernet(以太网)HWaddr(硬件mac地址)
第二行:网卡的IP地址、子网、掩码
第三行:UP(代表网卡开启状态)RUNNING(代表网卡的网线被接上)MULTICAST(支持组播)MTU:1500(最大传输单元):1500字节
第四、五行:接收、发送数据包情况统计
第七行:接收、发送数据字节数统计信息。
例二:启动关闭指定网卡
# 启动eth0网卡
$ ifconfig eth0 up
# 关闭eth0网卡
$ ifconfig eth0 down
注意: ssh登陆linux服务器操作要小心,关闭了就不能开启了,除非你有多网卡。
例三:为网卡配置和删除IPv6地址
# 配置IPv6的地址
$ ifconfig eth0 add 33ffe:3240:800:1005::2/64
# 删除IPv6的地址
$ ifconfig eth0 del 33ffe:3240:800:1005::2/64
例四:用ifconfig修改MAC地址
$ ifconfig eth0 hw ether 00:AA:BB:CC:DD:EE
例五:配置IP地址
# 配置ip
$ ifconfig eth0 192.168.120.56
# 配置ip和掩码地址
$ ifconfig eth0 192.168.120.56 netmask 255.255.255.0
# 配置ip、掩码地址和广播地址
$ ifconfig eth0 192.168.120.56 netmask 255.255.255.0 broadcast 192.168.120.255
例六:启用和关闭ARP协议
# 启用eth0的ARP协议
$ ifconfig eth0 arp
# 关闭eth0的ARP协议
$ ifconfig eth0 -arp
例七:设置最大传输单元
# 设置能通过的最大数据包大小为 1500 bytes
$ ifconfig eth0 mtu 1500linux命令: route
Linux系统的route命令用于显示和操作IP路由表(show / manipulate the IP routing table)。要实现两个不同的子网之间的通信,需要一台连接两个网络的路由器,或者同时位于两个网络的网关来实现。在Linux系统中,设置路由通常是为了解决以下问题:该Linux系统在一个局域网中,局域网中有一个网关,能够让机器访问Internet,那么就需要将这台机器的IP地址设置为Linux机器的默认路由。要注意的是,直接在命令行下执行route命令来添加路由,不会永久保存,当网卡重启或者机器重启之后,该路由就失效了;可以在/etc/rc.local中添加route命令来保证该路由设置永久有效。
命令格式
route [-f] [-p] [Command [Destination] [mask Netmask] [Gateway] [metric Metric]] [if Interface]]
命令功能
Route命令是用于操作基于内核ip路由表,它的主要作用是创建一个静态路由让指定一个主机或者一个网络通过一个网络接口,如eth0。当使用”add”或者”del”参数时,路由表被修改,如果没有参数,则显示路由表当前的内容。
命令参数
| 命令 | 描述 |
|---|---|
| -c | 显示更多信息 |
| -n | 不解析名字 |
| -v | 显示详细的处理信息 |
| -F | 显示发送信息 |
| -C | 显示路由缓存 |
| -f | 清除所有网关入口的路由表 |
| -p 与 add 命令 | -p 与 add 命令一起使用时使路由具有永久性。 |
| add | 添加一条新路由 |
| del | 删除一条路由 |
| -net | 目标地址是一个网络 |
| -host | 目标地址是一个主机 |
| netmask | 当添加一个网络路由时,需要使用网络掩码 |
| gw | 路由数据包通过网关。注意,你指定的网关必须能够达到 |
| metric | 设置路由跳数 |
| Command | 指定您想运行的命令 (Add/Change/Delete/Print) |
| Destination | 指定该路由的网络目标 |
| mask Netmask | 指定与网络目标相关的网络掩码(也被称作子网掩码) |
| Gateway | 指定网络目标定义的地址集和子网掩码可以到达的前进或下一跃点 IP 地址 |
| metric Metric | 为路由指定一个整数成本值标(从 1 至 9999),当在路由表(与转发的数据包目标地址最匹配)的多个路由中进行选择时可以使用 |
| if Interface | 为可以访问目标的接口指定接口索引。若要获得一个接口列表和它们相应的接口索引,使用 route print 命令的显示功能。可以使用十进制或十六进制值进行接口索引 |
使用实例
例一:显示当前路由
$ route
$ route -n
[root@localhost ~]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.120.0 * 255.255.255.0 U 0 0 0 eth0
e192.168.0.0 192.168.120.1 255.255.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.120.1 255.0.0.0 UG 0 0 0 eth0
default 192.168.120.240 0.0.0.0 UG 0 0 0 eth0
[root@localhost ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.120.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
192.168.0.0 192.168.120.1 255.255.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.120.1 255.0.0.0 UG 0 0 0 eth0
0.0.0.0 192.168.120.240 0.0.0.0 UG 0 0 0 eth0
说明:
第一行表示主机所在网络的地址为192.168.120.0,若数据传送目标是在本局域网内通信,则可直接通过eth0转发数据包;
第四行表示数据传送目的是访问Internet,则由接口eth0,将数据包发送到网关192.168.120.240
其中Flags为路由标志,标记当前网络节点的状态。
Flags标志说明:
U Up表示此路由当前为启动状态
H Host,表示此网关为一主机
G Gateway,表示此网关为一路由器
R Reinstate Route,使用动态路由重新初始化的路由
D Dynamically,此路由是动态性地写入
M Modified,此路由是由路由守护程序或导向器动态修改
! 表示此路由当前为关闭状态
备注:
route -n (-n 表示不解析名字,列出速度会比route 快)
例二:添加网关/设置网关
# 增加一条 到达244.0.0.0的路由
$ route add -net 224.0.0.0 netmask 240.0.0.0 dev eth0
例三:屏蔽一条路由
# 增加一条屏蔽的路由,目的地址为 224.x.x.x 将被拒绝
$ route add -net 224.0.0.0 netmask 240.0.0.0 reject
例四:删除路由记录
$ route del -net 224.0.0.0 netmask 240.0.0.0
$ route del -net 224.0.0.0 netmask 240.0.0.0 reject
例五:删除和添加设置默认网关
$ route del default gw 192.168.120.240
$ route add default gw 192.168.120.240linux命令: ss
ss是Socket Statistics的缩写。顾名思义,ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容。但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。
当服务器的socket连接数量变得非常大时,无论是使用netstat命令还是直接cat /proc/net/tcp,执行速度都会很慢。可能你不会有切身的感受,但请相信我,当服务器维持的连接达到上万个的时候,使用netstat等于浪费 生命,而用ss才是节省时间。
天下武功唯快不破。ss快的秘诀在于,它利用到了TCP协议栈中tcp_diag。tcp_diag是一个用于分析统计的模块,可以获得Linux 内核中第一手的信息,这就确保了ss的快捷高效。当然,如果你的系统中没有tcp_diag,ss也可以正常运行,只是效率会变得稍慢。(但仍然比 netstat要快。)
命令格式
$ ss [参数]
$ ss[参数] [过滤]
命令功能
ss(Socket Statistics的缩写)命令可以用来获取 socket统计信息,此命令输出的结果类似于 netstat输出的内容,但它能显示更多更详细的 TCP连接状态的信息,且比 netstat 更快速高效。它使用了 TCP协议栈中 tcp_diag(是一个用于分析统计的模块),能直接从获得第一手内核信息,这就使得 ss命令快捷高效。在没有 tcp_diag,ss也可以正常运行。
命令参数
| 命令 | 描述 |
|---|---|
| -h, –help | 帮助信息 |
| -V, –version | 程序版本信息 |
| -n, –numeric | 不解析服务名称 |
| -r, –resolve | 解析主机名 |
| -a, –all | 显示所有套接字(sockets) |
| -l, –listening | 显示监听状态的套接字(sockets) |
| -o, –options | 显示计时器信息 |
| -e, –extended | 显示详细的套接字(sockets)信息 |
| -m, –memory | 显示套接字(socket)的内存使用情况 |
| -p, –processes | 显示使用套接字(socket)的进程 |
| -i, –info | 显示 TCP内部信息 |
| -s, –summary | 显示套接字(socket)使用概况 |
| -4, –ipv4 | 仅显示IPv4的套接字(sockets) |
| -6, –ipv6 | 仅显示IPv6的套接字(sockets) |
| -0, –packet | 显示 PACKET 套接字(socket) |
| -t, –tcp | 仅显示 TCP套接字(sockets) |
| -u, –udp | 仅显示 UCP套接字(sockets) |
| -d, –dccp | 仅显示 DCCP套接字(sockets) |
| -w, –raw | 仅显示 RAW套接字(sockets) |
| -x, –unix | 仅显示 Unix套接字(sockets) |
| -f, –family=FAMILY | 显示 FAMILY类型的套接字(sockets),FAMILY可选,支持 unix, inet, inet6, link, netlink |
| -A, –query=QUERY, –socket=QUERY QUERY := {all |
inet |
| -D, –diag=FILE | 将原始TCP套接字(sockets)信息转储到文件 |
| -F, –filter=FILE | 从文件中都去过滤器信息 |
| FILTER := [ state TCP-STATE ] [ EXPRESSION ] |
使用实例
例一:显示TCP连接
$ ss -t -a
例二:显示 Sockets 摘要
$ ss -s
Total: 1385 (kernel 0)
TCP: 199 (estab 64, closed 76, orphaned 0, synrecv 0, timewait 1/0), ports 0
Transport Total IP IPv6
* 0 - -
RAW 2 1 1
UDP 29 21 8
TCP 123 47 76
INET 154 69 85
FRAG 0 0 0
说明:
列出当前的established, closed, orphaned and waiting TCP sockets
例三:列出所有打开的网络连接端口
$ ss -l
例四:查看进程使用的socket
$ ss -pl
例五:找出打开套接字/端口应用程序
$ ss -lp | grep 3306
例六:显示所有UDP Sockets
$ ss -u -a
例七:显示所有状态为established的SMTP连接
$ ss -o state established '( dport = :smtp or sport = :smtp )'
例八:显示所有状态为Established的HTTP连接
$ ss -o state established '( dport = :http or sport = :http )'
例九:列举出处于 FIN-WAIT-1状态的源端口为 80或者 443,目标网络为 193.233.7/24所有 tcp套接字
命令
$ ss -o state fin-wait-1 '( sport = :http or sport = :https )' dst 193.233.7/24
例十:用TCP 状态过滤Sockets
$ ss -4 state FILTER-NAME-HERE
$ ss -6 state FILTER-NAME-HERE
说明:
FILTER-NAME-HERE 可以代表以下任何一个:
established
syn-sent
syn-recv
fin-wait-1
fin-wait-2
time-wait
closed
close-wait
last-ack
listen
closing
all : 所有以上状态
connected : 除了listen and closed的所有状态
synchronized :所有已连接的状态除了syn-sent
bucket : 显示状态为maintained as minisockets,如:time-wait和syn-recv.
big : 和bucket相反.
例十一:匹配远程地址和端口号
$ ss dst ADDRESS_PATTERN
$ ss dst 192.168.1.5
$ ss dst 192.168.119.113:http
$ ss dst 192.168.119.113:smtp
$ ss dst 192.168.119.113:443
例十二:匹配本地地址和端口号
$ ss src ADDRESS_PATTERN
$ ss src 192.168.119.103
$ ss src 192.168.119.103:http
$ ss src 192.168.119.103:80
$ ss src 192.168.119.103:smtp
$ ss src 192.168.119.103:25
例十三:将本地或者远程端口和一个数比较
$ ss dport OP PORT
$ ss sport OP PORT
说明:
ss dport OP PORT 远程端口和一个数比较;ss sport OP PORT 本地端口和一个数比较。
OP 可以代表以下任意一个:
<= or le : 小于或等于端口号
>= or ge : 大于或等于端口号
== or eq : 等于端口号
!= or ne : 不等于端口号
< or gt : 小于端口号
> or lt : 大于端口号
例十四:ss 和 netstat 效率对比
$ time netstat -at
$ time ss
说明:
用time 命令分别获取通过netstat和ss命令获取程序和概要占用资源所使用的时间。在服务器连接数比较多的时候,netstat的效率完全没法和ss比。
linux命令: telnet
telnet命令通常用来远程登录。telnet程序是基于TELNET协议的远程登录客户端程序。Telnet协议是TCP/IP协议族中的一员,是Internet远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的 能力。在终端使用者的电脑上使用telnet程序,用它连接到服务器。终端使用者可以在telnet程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet会话,必须输入用户名和密码来登录服务器。Telnet是常用的远程控制Web服务器的方法。
但是,telnet因为采用明文传送报文,安全性不好,很多Linux服务器都不开放telnet服务,而改用更安全的ssh方式了。但仍然有很多别的系统可能采用了telnet方式来提供远程登录,因此弄清楚telnet客户端的使用方式仍是很有必要的。
telnet命令还可做别的用途,比如确定远程服务的状态,比如确定远程服务器的某个端口是否能访问。
命令格式
$ telnet [参数][主机]
命令功能
执行telnet指令开启终端机阶段作业,并登入远端主机。
命令参数
| 命令 | 描述 |
|---|---|
| -8 | 允许使用8位字符资料,包括输入与输出 |
| -a | 尝试自动登入远端系统 |
| -b<主机别名> | 使用别名指定远端主机名称 |
| -c | 不读取用户专属目录里的.telnetrc文件 |
| -d | 启动排错模式 |
| -e<脱离字符> | 设置脱离字符 |
| -E | 滤除脱离字符 |
| -f | 此参数的效果和指定”-F”参数相同 |
| -F | 使用Kerberos V5认证时,加上此参数可把本地主机的认证数据上传到远端主机 |
| -k<域名> | 使用Kerberos认证时,加上此参数让远端主机采用指定的领域名,而非该主机的域名 |
| -K | 不自动登入远端主机 |
| -l<用户名称> | 指定要登入远端主机的用户名称 |
| -L | 允许输出8位字符资料 |
| -n<记录文件> | 指定文件记录相关信息 |
| -r | 使用类似rlogin指令的用户界面 |
| -S<服务类型> | 设置telnet连线所需的IP TOS信息 |
| -x | 假设主机有支持数据加密的功能,就使用它 |
| -X<认证形态> | 关闭指定的认证形态 |
使用实例
例一:远程服务器无法访问
$ telnet 192.168.120.206
Trying 192.168.120.209...
telnet: connect to address 192.168.120.209: No route to host
telnet: Unable to connect to remote host: No route to host
说明:
处理这种情况方法:
(1)确认ip地址是否正确?
(2)确认ip地址对应的主机是否已经开机?
(3)如果主机已经启动,确认路由设置是否设置正确?(使用route命令查看)
(4)如果主机已经启动,确认主机上是否开启了telnet服务?(使用netstat命令查看,TCP的23端口是否有LISTEN状态的行)
(5)如果主机已经启动telnet服务,确认防火墙是否放开了23端口的访问?(使用iptables-save查看)
例二:域名无法解析
$ telnet www.baidu.com
www.baidu.com/telnet: Temporary failure in name resolution
说明:
处理这种情况方法:
(1)确认域名是否正确
(2)确认本机的域名解析有关的设置是否正确(/etc/resolv.conf中nameserver的设置是否正确,如果没有,可以使用nameserver 8.8.8.8)
(3)确认防火墙是否放开了UDP53端口的访问(DNS使用UDP协议,端口53,使用iptables-save查看)
例三:连接被拒绝
$ telnet 192.168.120.206
Trying 192.168.120.206...
telnet: connect to address 192.168.120.206: Connection refused
telnet: Unable to connect to remote host: Connection refused
说明:
处理这种情况:
(1)确认ip地址或者主机名是否正确?
(2)确认端口是否正确,是否默认的23端口
例四:正常telnet
$ telnet 192.168.120.204
Trying 192.168.120.204...
Connected to 192.168.120.204 (192.168.120.204).
Escape character is '^]'.
localhost (Linux release 2.6.18-274.18.1.el5 #1 SMP Thu Feb 9 12:45:44 EST 2012) (1)
login: root
Password:
Login incorrect
说明:
一般情况下不允许root从远程登录,可以先用普通账号登录,然后再用su -切到root用户。
例五:测试服务器8888端口是否可用
$ telnet 192.168.0.88 8888linux命令: rcp
rcp代表“remote copy”(远程文件拷贝)。该命令用于在计算机之间拷贝文件。rcp命令有两种格式。第一种格式用于文件到文件的拷贝;第二种格式用于把文件或目录拷贝到另一个目录中。
命令格式
$ rcp [参数] [源文件] [目标文件]
命令功能
rcp命令用在远端复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。
命令参数
| 命令 | 描述 |
|---|---|
| -r | 递归地把源目录中的所有内容拷贝到目的目录中。要使用这个选项,目的必须是一个目录 |
| -p | 试图保留源文件的修改时间和模式,忽略umask |
| -k | 请求rcp获得在指定区域内的远程主机的Kerberos 许可,而不是获得由krb_relmofhost⑶确定的远程主机区域内的远程主机的Kerberos许可。 |
| -x | 为传送的所有数据打开DES加密。这会影响响应时间和CPU利用率,但是可以提高安全性。如果在文件名中指定的路径不是完整的路径名,那么这个路径被解释为相对远程机上同名用户的主目录。如果没有给出远程用户名,就使用当前用户名。如果远程机上的路径包含特殊shell字符,需要用反斜线(\)、双引号(”)或单引号(’)括起来,使所有的shell元字符都能被远程地解释。需要说明的是,rcp不提示输入口令,它通过rsh命令来执行拷贝。 |
| directory | 每个文件或目录参数既可以是远程文件名也可以是本地文件名。远程文件名具有如下形式:rname@rhost:path,其中rname是远程用户名,rhost是远程计算机名,path是这个文件的路径。 |
使用实例
使用rcp,需要具备的条件
如果系统中有 /etc/hosts 文件,系统管理员应确保该文件包含要与之进行通信的远程主机的项。
/etc/hosts 文件中有一行文字,其中包含每个远程系统的以下信息:
internet_address official_name alias
例如:
9.186.10.*** webserver1.com.58.webserver
.rhosts 文件
.rhosts 文件位于远程系统的主目录下,其中包含本地系统的名称和本地登录名。
例如,远程系统的 .rhosts 文件中的项可能是:
webserver1 root
其中,webserver1 是本地系统的名称,root 是本地登录名。这样,webserver1 上的 root 即可在包含.rhosts 文件的远程系统中来回复制文件。
配置过程:
只对root用户生效
在双方root用户根目录下建立.rhosts文件,并将双方的hostname加进去.在此之前应在双方的 /etc/hosts文件中加入对方的IP和hostname
把rsh服务启动起来,redhat默认是不启动的。
方法:用执行ntsysv命令,在rsh选项前用空格键选中,确定退出。然后执行:
service xinetd restart即可。
3.到/etc/pam.d/目录下,把rsh文件中的auth required /lib/security/pam_securetty.so
一行用“#”注释掉即可。(只有注释掉这一行,才能用root用户登录)
例一:将本地img文件夹内的所有内容 复制到服务器相应的img目录下
# -r 递归子目录
$ rcp -r img/* webserver1:/var/project/img/
例二:将服务器的img文件夹内的所有内容 复制到本地目录下
# -r 递归子目录
$ rcp -r webserver1:/var/project/img/* img/
例三:将目录复制到远程系统:要将本地目录及其文件和子目录复制到远程系统
# 将本地的img目录复制到服务器的project目录下
$ rcp -r img/ webserver1:/var/project/linux命令: diff
diff 命令是 linux上非常重要的工具,用于比较文件的内容,特别是比较两个版本不同的文件以找到改动的地方。diff在命令行中打印每一个行的改动。最新版本的diff还支持二进制文件。diff程序的输出被称为补丁 (patch),因为Linux系统中还有一个patch程序,可以根据diff的输出将a.c的文件内容更新为b.c。diff是svn、cvs、git等版本控制工具不可或缺的一部分。
命令格式
$ diff [参数] [文件1或目录1] [文件2或目录2]
命令功能
diff命令能比较单个文件或者目录内容。如果指定比较的是文件,则只有当输入为文本文件时才有效。以逐行的方式,比较文本文件的异同处。如果指定比较的是目录的的时候,diff 命令会比较两个目录下名字相同的文本文件。列出不同的二进制文件、公共子目录和只在一个目录出现的文件。
命令参数
| 参数 | 描述 |
|---|---|
| - | 指定要显示多少行的文本。此参数必须与-c或-u参数一并使用 |
| -a或–text | diff预设只会逐行比较文本文件 |
| -b或–ignore-space-change | 不检查空格字符的不同 |
| -B或–ignore-blank-lines | 不检查空白行 |
| -c | 显示全部内文,并标出不同之处 |
| -C或–context | 与执行”-c”指令相同 |
| -d或–minimal | 使用不同的演算法,以较小的单位来做比较 |
| -D或ifdef | 此参数的输出格式可用于前置处理器巨集 |
| -e或–ed | 此参数的输出格式可用于ed的script文件 |
| -f或-forward-ed | 输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处 |
| -H或–speed-large-files | 比较大文件时,可加快速度 |
| -l或–ignore-matching-lines | 若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异 |
| -i或–ignore-case | 不检查大小写的不同 |
| -l或–paginate | 将结果交由pr程序来分页 |
| -n或–rcs | 将比较结果以RCS的格式来显示 |
| -N或–new-file | 在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录:文件A若使用-N参数,则diff会将文件A与一个空白的文件比较 |
| -p | 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称 |
| -P或–unidirectional-new-file | 与-N类似,但只有当第二个目录包含了一个第一个目录所没有的文件时,才会将这个文件与空白的文件做比较 |
| -q或–brief | 仅显示有无差异,不显示详细的信息 |
| -r或–recursive | 比较子目录中的文件 |
| -s或–report-identical-files | 若没有发现任何差异,仍然显示信息 |
| -S或–starting-file | 在比较目录时,从指定的文件开始比较 |
| -t或–expand-tabs | 在输出时,将tab字符展开 |
| -T或–initial-tab | 在每行前面加上tab字符以便对齐 |
| -u,-U或–unified= | 以合并的方式来显示文件内容的不同 |
| -v或–version | 显示版本信息 |
| -w或–ignore-all-space | 忽略全部的空格字符 |
| -W或–width | 在使用-y参数时,指定栏宽 |
| -x或–exclude | 不比较选项中所指定的文件或目录 |
| -X或–exclude-from | 您可以将文件或目录类型存成文本文件,然后在=中指定此文本文件 |
| -y或–side-by-side | 以并列的方式显示文件的异同之处 |
| –left-column | 在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容 |
| –suppress-common-lines | 在使用-y参数时,仅显示不同之处 |
| –help | 显示帮助 |
使用实例
例一:比较两个文件
```bash
$ diff 1.txt 2.txt
1c1
< ii
iii
>**说明:**
上面的“1c1”表示第一个文件和第二个文件的第1行内容有所不同;
diff 的normal 显示格式有三种提示:
a - add
c - change
d - delete
**`例二`:并排格式输出**
```bash
$ diff 1.txt 2.txt -y -W 50
ii | iii
iii iii
iiii iiii
iiiii iiiii
说明:
“|”表示前后2个文件内容有不同
“<”表示后面文件比前面文件少了1行内容
“>”表示后面文件比前面文件多了1行内容
例三:上下文输出格式
$ diff 1.txt 2.txt -c
*** 1.txt 2017-01-28 14:24:13.744538252 +0800
--- 2.txt 2017-01-28 14:24:59.096124066 +0800
***************
*** 1,4 ****
! ii
iii
iiii
iiiii
--- 1,4 ----
! iii
iii
iiii
iiiii
说明:
这种方式在开头两行作了比较文件的说明,这里有三中特殊字符:
“+” 比较的文件的后者比前着多一行
“-” 比较的文件的后者比前着少一行
“!” 比较的文件两者有差别的行
例四:统一格式输出
$ diff 1.txt 2.txt -u
--- 1.txt 2017-01-28 14:24:13.744538252 +0800
+++ 2.txt 2017-01-28 14:24:59.096124066 +0800
@@ -1,4 +1,4 @@
-ii
+iii
iii
iiii
iiiii
例五:比较文件夹不同
$ diff test3 test6
例六:比较两个文件不同,并生产补丁
$ diff -ruN 1.txt 2.txt >patch.log
例七:打补丁
$ 1.txt patch
Subscribe to:
Comments (Atom)