可以用下方 ai 语音自动生成想要说的话,发送链接或直接网页 /app 引用都可。
https://fanyi.sogou.com/reventondc/synthesis?text=你的文字内容&speed=1&lang=zh-CHShttps://tts.baidu.com/text2audio?tex=你的文字内容&cuid=baike&lan=ZH&ctp=1&pdt=301&vol=9
https://tts.youdao.com/fanyivoice?word=你的文字内容&le=cn&keyfrom=speaker-target ---------出门听听是同花顺旗下的文字转语音app,可以将 txt、doc 文档通过 AI 生成语音.
可以将文字生成的语音,通过链接分享他人。
可直接在各大市场搜索:出门听听或通过下方链接下载。
安卓
https://haosu.lanzoup.com/itWMHwfsmsf
iOS
https://apps.apple.com/cn/app/id1581354113
------------------------------------------------------------
https://www.zaixianai.cn/voiceCompose
https://www.zaixianai.cn/detail/60
https://www.zaixianai.cn/detail/62
https://www.zaixianai.cn/detail/63
https://www.zaixianai.cn/detail/66
----------------------------------
AI|6 个以假乱真的自动配音工具
微软官方的文字转语音工具
其实很多大聪明都是用微软的文字转语音工具做的。打开网址,输入文字,调整旁边的四个参数,然后你会发现,几个老朋友都在这儿。“你好,我们又见面了”
除此之外,还有很多 AI 配音工具,我常用的几个剪辑软件剪映和必剪也有类似功能。随便打开一个,在文本朗读里可以看见按类别分好的声库,它们活跃在影视解说、生活吐槽、悬疑故事以及你正在看的这个视频里。
那它们是营销号的专属吗?并不能这么区分。
但反过来想,营销号喜欢用的工具,大概率都是容易上手的好工具。像这个 app,你可以直接打上文字再添加配音,比人念旁白的速度快,也不用担心普通话是否标准,接着调节音量和变速效果,一段有旁白的视频就制作完成了。用它把生活中的随手一拍串起来,形成自己的日常记录,感觉还不错。
可惜这类配音我们平时听得太多,那来点不那么常见,但也好用的配音网站试试。
Ondoku
一个操作界面自带各国语言的国外网站,在这里切换,不必再拿翻译器翻译一遍网页文字。输入文字,选择语言,里面有中文、英文等五十多种语言可选,其中还包括我国台湾方言和香港方言。
然后选择声库,调整语速语调,步骤跟微软的配音工具一样,但你还能上传含有文字的图片,实际做起来更方便点。
如果你的视频只需要直白清晰的讲解,解释几句工具的使用方法,用它绰绰有余,就是听起来似乎太僵硬了,没什么情感,可能别人一看就以为是个营销号,火速退出视频。这时你可以选择支持 SSML,也就是语音合成标记语言的工具,比如 FREETTS。
FREETTS
你要是受够了众多网站需要登录才能使用的毛病,那 FREETTS 绝对算是善良友好。无需注册,全程免费商用,输入文字后,查看下方的语音合成标记语言,把特殊字符拎出来添加标识,这里加上逐字拼写,中间暂停,后面加点强调,使整句话变得抑扬顿挫起来,效果比单纯的配音合成好多了。
当然,要是一般只需要中文旁白,用用国内的文字转语音网站就已经足够了。知意、讯飞、牛片网、魔音工坊......一搜一麻袋。
官方网站`
声咖
被金钱击败的话,选择声咖,假如你跟我一样是悬疑电台爱好者,可以用它来模拟一段你喜欢的电子书。
选好一个阴沉型的角色,粘贴文本,这次不用费劲儿搜罗语音合成标记语言,直接点击插入停顿,对局部变速,添加富有惊悚感的雷电音效,背景音乐,在涉及多人对话的地方,对每个人的话语设置不同 AI,改变它们的方言或情绪,接下来,你就可以听你自己制作的有声书了。
中文之间要是出现了英文或数字,也不必担心,你可以点击上方的数字符号和单词读法进行设置。一个个念单词太死板,那就加上词组连读,看得出来,主攻中文的 AI 念起英语也是毫不违和。
XAudioPro
那么万事俱备,最后你我只需要一条条导出 AI 合成的配音,放进剪辑软件调整音频就好了。
其实,你可以用 XAudioPro 把这个过程变得再快捷点。
以电商销售为例子,把刚刚的音频导入剪辑轨道,配合提前备好的喧闹环境音来调整,你可以模拟主播情绪状态增减音量,添加淡入淡出,混响,降噪,边配边剪,边剪边配,直到模拟出来的效果跟真实差不多,这听了谁还说是营销号。
Uberduck
不过,你可能还是觉得这些声库都不够特别,不能展现你视频配音的独特性。Uberduck 你会感兴趣的,你可以使用里面众多以电影,动漫人物为原型的语音,cos 你想要的角色。如果你正好是其中一些作品的粉丝,像这样编排文案语音和剧情,结合剪辑创造一段同人作品也非常 ok 。
虽然 AI 配音被大量营销号使用,但请不要对它产生什么偏见,它也可以做成正经的科普、有氛围的有声书、事件记录……用在很多地方。
你要是不嫌折腾,还可以试试 GitHub 上的开源项目,自己部署软件和环境,花心思调教调教,机器也可能克隆出你的声音。-------------------------------------
TTS文字转语音工具
TTS 是Text To Speech的缩写,即“从文本到语音”。它是同时运用语言学和心理学的杰出之作,在内置芯片的支持之下,通过神经网络的设计,把文字智能地转化为自然语音流。TTS技术对文本文件进行实时转换,转换时间之短可以秒计算。
今天分享的TTS文字转语音工具,汇集了多个平台引擎,压缩包内有将近上百种的音源供大家选择。听书听小说或者配音都可以使用.
使用方法:
首先将软件安装好,然后把离线音源包(点击右上角导入压缩包里的两个voice.zip)导入到软件中即可使用。每个音都可以自行调试,非常好用。
软件下载:
https://www.123pan.com/s/hUDbVv-nehNH.html
提取码:52pj
---------------------
http://cn.piliapp.com/text-to-speech/ 直接输入文字点击播放。
百度语音广播开放平台:
百度的这个还不错,支持5000字 https://developer.baidu.com/vcast ,
生成的语音链接可以下载到本地。
Read Aloud 是一款用来朗读网页的 Chrome 扩展,支持 40 多种语言,包括普通话、国语、粤语等,支持阅读 PDF,默认是女声。可以自己选择想听的语言:

可以选中文字右键朗读.
Chrome扩展的安装地址 https://chrome.google.com/webstore/detail/read-aloud-a-text-to-spee/hdhinadidafjejdhmfkjgnolgimiaplp
讯飞快读
很多APP的语音朗读功能都是用的科大讯飞提供的接口https://www.xfyun.cn/services/online_tts
讯飞快读是科大讯飞旗下产品 https://www.ffkuaidu.com/ ,限制1500字,不过语音末尾会加上本文语音由讯飞快读提供这段文字。
保存为mp3需要登录,不想登录怎么办 ,用 idm软件捕获音频下载。你还可以选择朗读员和背景音。除了网页版他们还有对应小程序版(1500字内),生成一张有声的二维码图片,这样方便在微信里分享。点击打开小程序
讯飞文字转语音的程序
这个也是基于讯飞的软件,免安装,直接点击运行即可,合成的语音保存在程序目录。
Balabolka使用微软的语音API ,可自行调节语调和语速。输入文字后点击朗读按钮,觉得可以再保存到本地。http://www.cross-plus-a.com/cn/balabolka.htm, Balabolka是一个文本转语音(TTS)的程序。Balabolka可以使用计算机系统上安装的所有语音。屏幕上的文字可以被保存为一个WAV,MP3,OGG或者WMA文件。该软件可以读取剪贴板的内容,可以查看AZW,AZW3,CHM,DjVu,DOC,EML,EPUB,FB2,FB3,LIT,MD,MOBI,ODP,ODS,ODT,PDB,PDF,PPT,PRC,RTF,TCR,WPD,XLS和HTML文件中的文本,可自定义字体和背景颜色,控制从系统托盘阅读或者使用热键。 Balabolka使用微软的语音API(SAPI)的各种版本,它可以改变语音的参数,包括语度和语调。用户可以应用特殊的替代清单,以提高语音的清晰度质量。当你想改变的单词拼写时这个功能就非常有用。纠正发音规则使用VBScript的语法.
http://www.cross-plus-a.com/balabolka.zip
该程序通过使用以下在线服务将文本或字幕转换为音频文件:Google,亚马逊,百度,IBM Watson,微软,Naver,有道。
The program converts text or subtitles to audio files by using of the Yandex service.
To perform operations via the Yandex API, it is necessary to authenticate using an API-key.
* Balabolka是一个俄语单词,可翻译为“喋喋不休".
from http://www.cross-plus-a.com/cn/balabolka.htm

-----------------------------------------------------------
https://tool.chishi.com/speech_synthesis
-------------------------------------------
文字转语音助手
文字转语音助手是一款实用的文字朗读配音app,可将大段文字以各种优美的声音朗读朗诵出来,将文字转为语音!
文字转语音助手是一款文字转语音配音语音朗诵软件,支持文本转换语音轻松转换阅读,适用于商场店铺广告促销配音、地摊叫卖录音、文本有声朗读、短视频制作配音等多种场景,实时保存文件转换与分享,提高日常工作效率,从而方便快捷的语音阅读开始!
【产品主要功能】
智能文字识别:
- 采用智能文字识别技术,准确将文本转换为语音播放;
- 随时播放,为用户提供高效的文档转换播放工具;
多种主播声音:
- 内置100多种主播语音包,支持中文与英文;
多种背景音乐:
- 内置多种背景音乐,让朗读不再枯燥乏味;
一键保存分享音频:
- 识别转换的音频文件可以保存到本地,同时也支持一键分享至他人
新内容
1、新增音频转文字功能。
from https://apps.apple.com/cn/app/id1586430502
--------------------------------
阿里云的智能语音交互产品
软件特点
- 简洁、清爽的UI界面
- 80种类型的阿里语音、内置背景音乐、示例文本
- 使用不限制文本字数
- 支持输出格式:MP3、WAV
注意事项
- 内置阿里免费key,支持自定义key(强烈建议自行申请一个,否则过一段时间可能就失效了)
- 官方文档:https://help.aliyun.com/document_detail/69835.html


下载地址:https://www.123pan.com/s/1FzA-3HoMv
----------------
https://ttsmaker.com/,Free Text to Speech
----------------------------
https://www.youtube.com/watch?v=RsnU0Pjt7lo
Fliki:https://fliki.ai/
LOVO:https://lovo.ai/
Audyo:https://www.audyo.ai/
-------------------------------------------------------------
中文语音机器人:wukong-robot
wukong-robot是国人开发的中文语音对话机器人项目,目的是让中国的 Maker 和 Haker 们快速打造个性化的智能音箱。wukong-robot 被唤醒后,用户的语音指令先经过 ASR 引擎进行 ASR 识别成文本,然后对识别到的文本进行 NLU 解析,再将解析结果进行技能匹配,交给适合处理该指令的技能插件去处理。插件处理完成后,得到的结果再交给 TTS 引擎合成语音,播放给用户。wukong-robot遵守MIT开源协议。
特性:
高度模块化。功能插件、语音识别、语音合成、对话机器人,第三方插件单独维护,可扩展性强。
中文支持。集成百度、科大讯飞、阿里、腾讯等多家中文语音识别和语音合成技术,且可以继续扩展。
对话机器人支持。支持接入图灵机器人、Emotibot 等对话机器人。
全局监听,离线唤醒。支持无接触地离线语音指令唤醒。
灵活可配置。支持定制机器人名字,支持选择语音识别和合成的插件。
智能家居。支持和 mqtt、HomeAssistant 等智能家居协议联动,支持语音控制智能家电。
后台配套支持。提供配套后台,可实现远程操控、修改配置和日志查看等功能。
开放API。可利用后端开放的API,实现更丰富的功能。
微信接入。配合 wukong-itchat(https://github.com/wzpan/wukong-itchat) ,可实现通过微信远程操控家中的设备。
安装简单,支持Mac 以及 Linux 系统中运行。(可运行在树莓派上)
[repo owner=”wzpan” name=”wukong-robot”]
(wukong-robot 是一个简单、灵活、优雅的中文语音对话机器人/智能音箱项目,支持ChatGPT多轮对话能力,还可能是首个支持脑机交互的开源智能音箱项目。
wukong-robot
wukong-robot 是一个简单、灵活、优雅的中文语音对话机器人/智能音箱项目,目的是让中国的 Maker 和 Haker 们也能快速打造个性化的智能音箱。wukong-robot 还可能是第一个开源的脑机唤醒智能音箱。
截至 2023 年 3 月 31 日,wukong-robot 的安装设备数已超过 13,000 台,唤醒次数累积超过了 700,000 次。



Table of Contents
特性
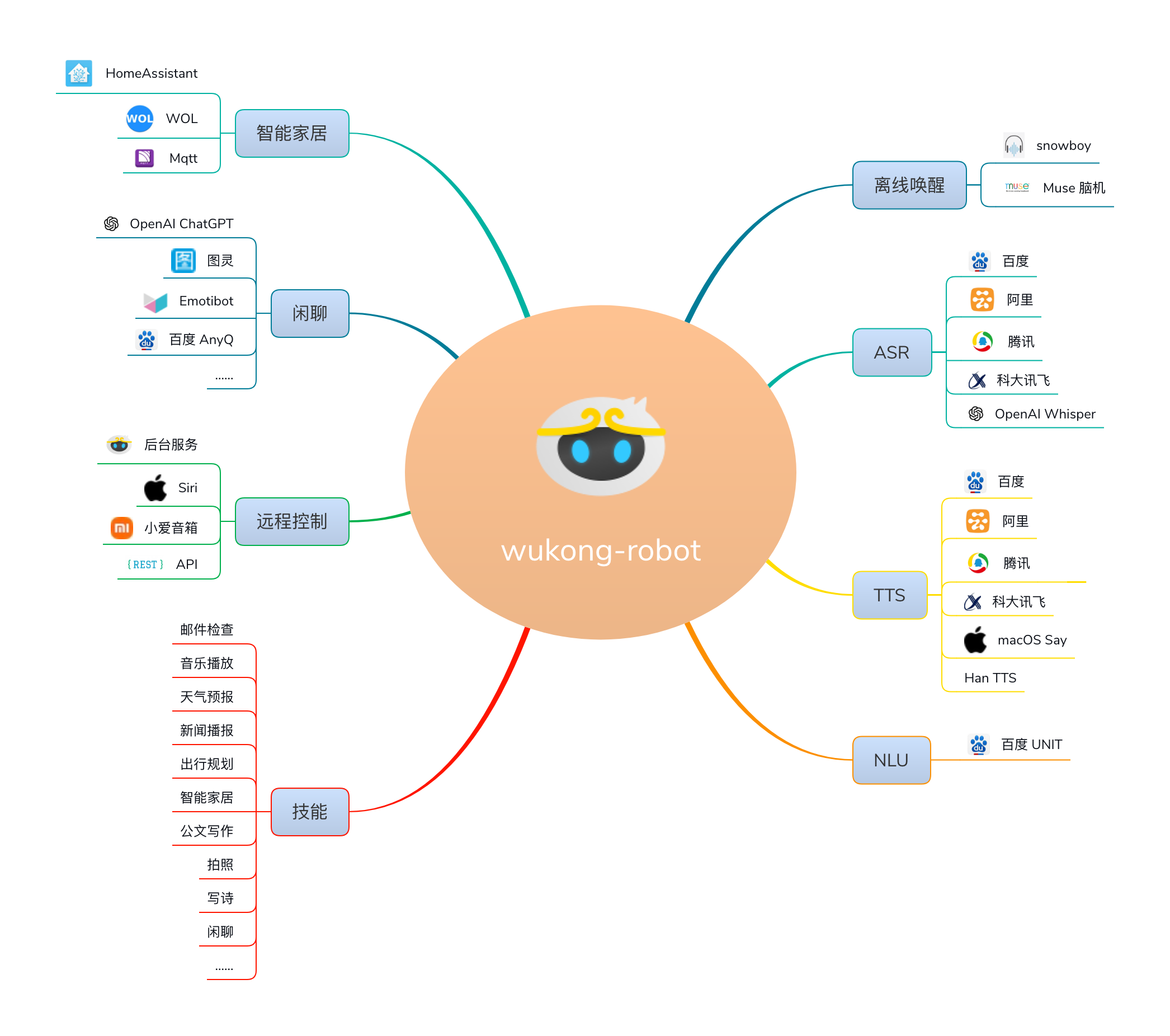
- 模块化。功能插件、语音识别、语音合成、对话机器人都做到了高度模块化,第三方插件单独维护,方便继承和开发自己的插件。
- 中文支持。集成百度、科大讯飞、阿里、腾讯、OpenAI Whisper、Apple、微软Edge、VITS声音克隆TTS 等多家中文语音识别和语音合成技术,且可以继续扩展。
- 对话机器人支持。支持基于 AnyQ 的本地对话机器人,并支持接入图灵机器人、ChatGPT 等在线对话机器人。
- 全局监听,离线唤醒。支持 Porcupine 和 snowboy 两套离线语音指令唤醒引擎,并支持 Muse 脑机唤醒 以及行空板摇一摇唤醒等其他唤醒方式。
- 灵活可配置。支持定制机器人名字,支持选择语音识别和合成的插件。
- 智能家居。支持和 小爱音箱、Siri、mqtt、HomeAssistant 等智能家居协议联动,支持语音控制智能家电。
- 后台配套支持。提供配套后台,可实现远程操控、修改配置和日志查看等功能。
- 开放API。可利用后端开放的API,实现更丰富的功能。
- 安装简单,支持更多平台。相比 dingdang-robot ,舍弃了 PocketSphinx 的离线唤醒方案,安装变得更加简单,代码量更少,更易于维护并且能在 Mac 以及更多 Linux 系统中运行。
wukong-robot 的功能还在不断更新迭代中,详见 更新说明 。
wukong-robot 的工作模式:
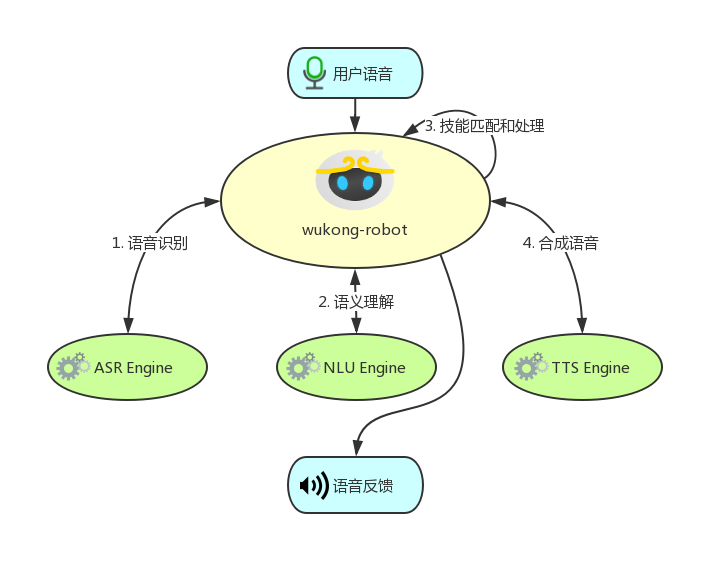
wukong-robot 被唤醒后,用户的语音指令先经过 ASR 引擎进行 ASR 识别成文本,然后对识别到的文本进行 NLU 解析,再将解析结果进行技能匹配,交给适合处理该指令的技能插件去处理。插件处理完成后,得到的结果再交给 TTS 引擎合成成语音,播放给用户。
虽然一次交互可能包含多次网络请求,不过带来的好处是:每一个环节都可以被修改和定制。而且我认为,到了 5G 时代,音箱的响应速度将不再成为体验问题。可定制和个性化才是未来的主流,而届时 wukong-robot 将会是更好的选择!
Demo

- Demo视频:
- 后台管理端 Demo
- 体验地址:https://bot.hahack.com (体验用户名:wukong;体验密码:wukong@2019)
环境要求
Python 版本
wukong-robot 只支持 Python >= 3.7 且 < 3.10 ,不支持 Python 2.x 。
设备要求
wukong-robot 支持运行在以下的设备和系统中:
- Intel Chip Mac (不支持 M1 芯片)
- 64bit Ubuntu(12.04 and 14.04)
- 全系列的树莓派(Raspbian 系统)
- Pine 64 with Debian Jessie 8.5(3.10.102)
- Intel Edison with Ubilinux (Debian Wheezy 7.8)
- 装有 WSL(Windows Subsystem for Linux) 的 Windows
安装
升级
python3 wukong.py update如果提示升级失败,可以尝试在 wukong-robot 的根目录手动执行以下命令,看看问题出在哪。
git pull
pip3 install -r requirements.txt运行
python3 wukong.py建议在 tmux 或 supervisor 中执行。
第一次启动时将提示你是否要到用户目录下创建一个配置文件,输入 y 即可。
然后通过唤醒词 “snowboy” 唤醒 wukong-robot 进行交互(该唤醒词可自定义)。
此外,wukong-robot 默认在运行期间还会启动一个后台管理端,提供了远程对话、查看修改配置、查看 log 等能力。
- 默认地址:http://localhost:5001
- 默认账户名:wukong
- 默认密码:wukong@2019
建议正式使用时修改用户名和密码,以免泄漏隐私。
配置
参考配置文件的注释进行配置即可。注意不建议直接修改 default.yml 里的内容,否则会给后续通过 git pull 更新带来麻烦。你应该拷贝一份放到 $HOME/.wukong/config.yml 中,或者在运行的时候按照提示让 wukong-robot 为你完成这件事。
tips:不论使用哪个厂商的API,都建议注册并填上自己注册的应用信息,而不要用默认的配置。这是因为这些API都有使用频率和并发数限制,过多人同时使用会影响服务质量。
技能插件
API 接口
wukong-robot 的后台接口是开放 Web API 的,可以使用 Restful 方式调用,见 后台API。
from https://github.com/wzpan/wukong-robot )
---------------------------------------------------------
TTS-Vue,微软语音合成工具,使用 Electron + Vue + ElementPlus + Vite 构建。
from https://loker-page.lgwawork.com/home.html
(https://loker-page.lgwawork.com/guide/,
https://github.com/LokerL/tts-vue
https://github.com/LokerL/tts-vue/releases)
-----------------------------------------------------------------------------------------
Sample Repository for the Microsoft Cognitive Services Speech SDK
This project hosts the samples for the Microsoft Cognitive Services Speech SDK. To find out more about the Microsoft Cognitive Services Speech SDK itself, please visit the SDK documentation site.
News
Please check here for release notes and older releases.
Features
This repository hosts samples that help you to get started with several features of the SDK. In addition more complex scenarios are included to give you a head-start on using speech technology in your application.
We tested the samples with the latest released version of the SDK on Windows 10, Linux (on supported Linux distributions and target architectures), Android devices (API 23: Android 6.0 Marshmallow or higher), Mac x64 (OS version 10.14 or higher) and Mac M1 arm64 (OS version 11.0 or higher) and iOS 11.4 devices.
Getting Started
The SDK documentation has extensive sections about getting started, setting up the SDK, as well as the process to acquire the required subscription keys. You will need subscription keys to run the samples on your machines, you therefore should follow the instructions on these pages before continuing.
Get the samples
-
The easiest way to use these samples without using Git is to download the current version as a ZIP file.
- On Windows, before you unzip the archive, right-click it, select Properties, and then select Unblock.
- Be sure to unzip the entire archive, and not just individual samples.
-
Clone this sample repository using a Git client.
Build and run the samples
Note: the samples make use of the Microsoft Cognitive Services Speech SDK. By downloading the Microsoft Cognitive Services Speech SDK, you acknowledge its license, see Speech SDK license agreement.
Please see the description of each individual sample for instructions on how to build and run it.
Related GitHub repositories
-
Azure-Samples/Cognitive-Services-Voice-Assistant - Additional samples and tools to help you build an application that uses Speech SDK's DialogServiceConnector for voice communication with your Bot-Framework bot or Custom Command web application.
-
microsoft/cognitive-services-speech-sdk-js - JavaScript implementation of Speech SDK
-
Microsoft/cognitive-services-speech-sdk-go - Go implementation of Speech SDK
-
Azure-Samples/Speech-Service-Actions-Template - Template to create a repository to develop Azure Custom Speech models with built-in support for DevOps and common software engineering practices
Speech recognition quickstarts
The following quickstarts demonstrate how to perform one-shot speech recognition using a microphone. If you want to build them from scratch, please follow the quickstart or basics articles on our documentation page.
| Quickstart | Platform | Description |
|---|---|---|
| Quickstart C++ for Linux | Linux | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C++ for Windows | Windows | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C++ for macOS | macOS | |
| Quickstart C# .NET for Windows | Windows | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C# .NET Core | Windows, Linux, macOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C# UWP for Windows | Windows | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C# Unity (Windows or Android) | Windows, Android | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart for Android | Android | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Java JRE | Windows, Linux, macOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart JavaScript | Web | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Node.js | Node.js | Demonstrates one-shot speech recognition from a file. |
| Quickstart Python | Windows, Linux, macOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Objective-C iOS | iOS | Demonstrates one-shot speech recognition from a file with recorded speech. |
| Quickstart Swift iOS | iOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Objective-C macOS | macOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Swift macOS | macOS | Demonstrates one-shot speech recognition from a microphone. |
Speech translation quickstarts
The following quickstarts demonstrate how to perform one-shot speech translation using a microphone. If you want to build them from scratch, please follow the quickstart or basics articles on our documentation page.
| Quickstart | Platform | Description |
|---|---|---|
| Quickstart C++ for Windows | Windows | Demonstrates one-shot speech translation/transcription from a microphone. |
| Quickstart C# .NET Framework for Windows | Windows | Demonstrates one-shot speech translation/transcription from a microphone. |
| Quickstart C# .NET Core | Windows, Linux, macOS | Demonstrates one-shot speech translation/transcription from a microphone. |
| Quickstart C# UWP for Windows | Windows | Demonstrates one-shot speech translation/transcription from a microphone. |
| Quickstart Java JRE | Windows, Linux, macOS | Demonstrates one-shot speech translation/transcription from a microphone. |
Speech synthesis quickstarts
The following quickstarts demonstrate how to perform one-shot speech synthesis to a speaker. If you want to build them from scratch, please follow the quickstart or basics articles on our documentation page.
| Quickstart | Platform | Description |
|---|---|---|
| Quickstart C++ for Linux | Linux | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C++ for Windows | Windows | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C++ for macOS | macOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C# .NET for Windows | Windows | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C# UWP for Windows | Windows | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C# .NET Core | Windows, Linux | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart for C# Unity (Windows or Android) | Windows, Android | Demonstrates one-shot speech synthesis to a synthesis result and then rendering to the default speaker. |
| Quickstart for Android | Android | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Java JRE | Windows, Linux, macOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Python | Windows, Linux, macOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Objective-C iOS | iOS | Demonstrates one-shot speech synthesis to a synthesis result and then rendering to the default speaker. |
| Quickstart Swift iOS | iOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Objective-C macOS | macOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Swift macOS | macOS | Demonstrates one-shot speech synthesis to the default speaker. |
Voice Assistant quickstarts
The following quickstarts demonstrate how to create a custom Voice Assistant. The applications will connect to a previously authored bot configured to use the Direct Line Speech channel, send a voice request, and return a voice response activity (if configured). If you want to build these quickstarts from scratch, please follow the quickstart or basics articles on our documentation page.
See also Azure-Samples/Cognitive-Services-Voice-Assistant for full Voice Assistant samples and tools.
| Quickstart | Platform | Description |
|---|---|---|
| Quickstart Java JRE | Windows, Linux, macOS | Demonstrates speech recognition through the DialogServiceConnector and receiving activity responses. |
| Quickstart C# UWP for Windows | Windows | Demonstrates speech recognition through the DialogServiceConnector and receiving activity responses. |
Samples
The following samples demonstrate additional capabilities of the Speech SDK, such as additional modes of speech recognition as well as intent recognition and translation. Voice Assistant samples can be found in a separate GitHub repo.
| Sample | Platform | Description |
|---|---|---|
| C++ Console app for Windows | Windows | Demonstrates speech recognition, speech synthesis, intent recognition, conversation transcription and translation |
| C++ Speech Recognition from MP3/Opus file (Linux only) | Linux | Demonstrates speech recognition from an MP3/Opus file |
| C# Console app for .NET Framework on Windows | Windows | Demonstrates speech recognition, speech synthesis, intent recognition, and translation |
| C# Console app for .NET Core (Windows or Linux) | Windows, Linux, macOS | Demonstrates speech recognition, speech synthesis, intent recognition, and translation |
| Java Console app for JRE | Windows, Linux, macOS | Demonstrates speech recognition, speech synthesis, intent recognition, and translation |
| Python Console app | Windows, Linux, macOS | Demonstrates speech recognition, speech synthesis, intent recognition, and translation |
| Speech-to-text UWP sample | Windows | Demonstrates speech recognition |
| Text-to-speech UWP sample | Windows | Demonstrates speech synthesis |
| Speech recognition sample for Android | Android | Demonstrates speech and intent recognition |
| Speech recognition, synthesis, and translation sample for the browser, using JavaScript | Web | Demonstrates speech recognition, intent recognition, and translation |
| Speech recognition and translation sample using JavaScript and Node.js | Node.js | Demonstrates speech recognition, intent recognition, and translation |
| Speech recognition sample for iOS using a connection object | iOS | Demonstrates speech recognition |
| Extended speech recognition sample for iOS | iOS | Demonstrates speech recognition using streams etc. |
| Speech synthesis sample for iOS | iOS | Demonstrates speech synthesis using streams etc. |
| C# UWP DialogServiceConnector sample for Windows | Windows | Demonstrates speech recognition through the DialogServiceConnector and receiving activity responses. |
| C# Unity sample for Windows or Android | Windows, Android | Demonstrates speech recognition, intent recognition, and translation for Unity |
| C# Unity SpeechBotConnector sample for Windows or Android | Windows, Android | Demonstrates speech recognition through the SpeechBotConnector and receiving activity responses. |
| C#, C++ and Java DialogServiceConnector samples | Windows, Linux, Android | Additional samples and tools to help you build an application that uses Speech SDK's DialogServiceConnector for voice communication with your Bot-Framework Bot or Custom Command web application. |
Samples for using the Speech Service REST API (no Speech SDK installation required):
| Sample | Description |
|---|---|
| Batch transcription | Demonstrates usage of batch transcription from different programming languages |
| Batch synthesis | Demonstrates usage of batch synthesis from different programming languages |
Tools
| Tool | Platform | Description |
|---|---|---|
| Enumerate audio devices | C++, Windows | Shows how to get the Device ID of all connected microphones and loudspeakers. Device ID is required if you want to listen via non-default microphone (Speech Recognition), or play to a non-default loudspeaker (Text-To-Speech) using Speech SDK |
| Enumerate audio devices | C# .NET Framework, Windows | -"- |
Sample data for Custom Speech
Resources
from https://github.com/Azure-Samples/cognitive-services-speech-sdk
---------------------------------------------------------------------------------------
免费视频配音小程序-逗哥配音,60多种真人音色可选
本文就为您推荐一款免费视频配音软件“逗哥配音”,采用AI技术,60多种音色可选,让你分不出是真人还是电脑。
先来听几段不用音色的配音感受一下:
解说类
情感类
方言类
几十种音色就不一一举例了,当你制作好视频画面,写好文案,直接把生成的真人语音配上,超级完美!
如何制作配音?
1.在微信小程序直接搜索“逗哥配音”。
2.电脑端打开这个网址:逗哥配音神器- http://douge.club/
输入你想配音的文案,选择语音、语速即可,超级简单!后期还可针对配音进行音效处理,功能强大。
更有诸多工具:音效处理,录音变音,本地音频变声,文案提取,短视频去水印等。
--------------------------------------------
OpenAI文字转语音在线生成工具-OpenAI Text-To-Speech API with Gradio
OpenAI TTS New(OpenAI Text-To-Speech API with Gradio)是一个体验OpenAI新版文字转语音在线生成工具,不过需要自备OpenAI API Key,目前支持7种声音和两种模型,文字转语音工具支持调节语速,而且支持下载文字转语音后的mp3格式的文件,感兴趣的同学可以到网站学习体验。
地址:https://huggingface.co/spaces/ysharma/OpenAI_TTS_New
-------------------------------------------------------------------------
琅琅配音 永久免费的智能文本转语音服务
琅琅配音是一款免费的文本转语音工具,提供语音合成服务,支持多种语言,包括中文、英语、德语、法语、意大利语、西班牙语、印尼语等30多种语言,以及多种语音风格。您可以用它制作视频配音,也可用于有声书朗读,或产品营销内容制作。琅琅配音可免费合成语言,并免费下载音频文件用于商业用途。
为了防止服务盗用,每个用户每周30000字转换额度。注册账号需要填手机号,但目前无需短信验证,填写即可。
网址:https://www.lang123.top/
琅琅配音提供多音、别名、文本、数值、连读、插入停顿、背景音、音效等多种配音功能,以及多配音人的合成方式。
在编辑器中可以一次性完成所有文本转换操作,直观、方便,简单易用,并且支持历史转换任务再次修改。
琅琅配置支持中文、英语、德语、法语、意大利语、西班牙语、印尼语等30多种语言,以及快乐、悲伤、愤怒、恐惧、惊讶等多种情感风格。
您可以免费使用琅琅配音合成语音,并且拥有合成的音频文件的100%版权,并可以将其用于任何合法用途。
转换之后可以下载wav格式的音频文件。转换完成需要尽快下载,下载链接将在任务完成7天后失效。全程网页操作,不需要下载任何软件、app等。
最好用的文本转音频软件chatTTs,第三方魔改版,一键安装直接使用,免费生成长视频,支持角色扮演,Windows macOS android iPhone os 全平台
版本 | 地址 | 介绍 |
在线Colab版 | 可以在 Google Colab 上一键运行,需要 Google账号,Colib 自带15GB的GPU | |
PodCastLM是一款开源免费的工具,可以将 PDF 内容转化为适合音频播客的自然对话,并输出为 MP3 文件。灵感来自于
Google NotebookLM 工具。AI模型采用Llama,语音是采用- AI Powered Azure OpenAI TTS
。项目遵守MIT开源协议。
技术栈:
- React – FrontEnd Development
- Tailwindcss – CSS Engine
- FastAPI – BackEnd Development
源代码:https://github.com/YOYZHANG/PodCastLM
---------------------------------------------------------------------------------------------
相关帖子:
https://briteming.blogspot.com/2023/03/edge-tts-record.html
No comments:
Post a Comment