Real time transcription with OpenAI Whisper.

This is a demo of real time speech to text with OpenAI's Whisper model. It works by constantly recording audio in a thread and concatenating the raw bytes over multiple recordings.
To install dependencies simply run
pip install -r requirements.txt
in an environment of your choosing.
Whisper also requires the command-line tool ffmpeg to be installed on your system, which is available from most package managers:
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
For more information on Whisper please see https://github.com/openai/whisper
from https://github.com/davabase/whisper_real_time
---------
High-performance GPGPU inference of OpenAI's Whisper automatic speech recognition (ASR) model.
This project is a Windows port of the whisper.cpp implementation.
Which in turn is a C++ port of OpenAI's Whisper automatic speech recognition (ASR) model.
Download WhisperDesktop.zip from the “Releases” section of this repository, unpack the ZIP, and run WhisperDesktop.exe.
On the first screen it will ask you to download a model.
I recommend ggml-medium.bin (1.42GB in size), because I’ve mostly tested the software with that model.

The next screen allows to transcribe an audio file.

There’s another screen which allows to capture and transcribe or translate live audio from a microphone.

-
Vendor-agnostic GPGPU based on DirectCompute; another name for that technology is “compute shaders in Direct3D 11”
-
Plain C++ implementation, no runtime dependencies except essential OS components
-
Much faster than OpenAI’s implementation.
On my desktop computer with GeForce 1080Ti GPU, medium model, 3:24 min speech took 45 seconds to transcribe with PyTorch and CUDA, but only 19 seconds with my implementation and DirectCompute.
Funfact: that’s 9.63 gigabytes runtime dependencies, versus 431 kilobytesWhisper.dll -
Mixed F16 / F32 precision: Windows requires support of
R16_FLOATbuffers since D3D version 10.0 -
Built-in performance profiler which measures execution time of individual compute shaders
-
Low memory usage
-
Media Foundation for audio handling, supports most audio and video formats (with the notable exception of Ogg Vorbis), and most audio capture devices which work on Windows (except some professional ones, which only implementing ASIO API).
-
Voice activity detection for audio capture.
The implementation is based on the 2009 article “A simple but efficient real-time voice activity detection algorithm” by Mohammad Moattar and Mahdi Homayoonpoor. -
Easy to use COM-style API. Idiomatic C# wrapper available on nuget.
Version 1.10 introduced scripting support for PowerShell 5.1, that’s the older “Windows PowerShell” version which comes pre-installed on Windows. -
Pre-built binaries available
The only supported platform is 64-bit Windows.
Should work on Windows 8.1 or newer, but I have only tested on Windows 10.
The library requires a Direct3D 11.0 capable GPU, which in 2023 simply means “any hardware GPU”.
The most recent GPU without D3D 11.0 support was Intel Sandy Bridge from 2011.
On the CPU side, the library requires AVX1 and F16C support.
-
Clone this repository
-
Open
WhisperCpp.slnin Visual Studio 2022. I’m using the freeware community edition, version 17.4.4. -
Switch to
Releaseconfiguration -
Build and run
CompressShadersC# project, in theToolssubfolder of the solution. To run that project, right click in visual studio, “Set as startup project”, then in the main menu of VS “Debug / Start Without Debugging”. When completed successfully, you should see a console window with a line like that:
Compressed 46 compute shaders, 123.5 kb -> 18.0 kb -
Build
Whisperproject to get the native DLL, orWhisperNetfor the C# wrapper and nuget package, or the examples.
If
you gonna consume the library in a software built with Visual C++ 2022
or newer, you probably redistribute Visual C++ runtime DLLs in the form
of the .msm merge module,
or vc_redist.x64.exe binary.
If you do that, right click on the Whisper project, Properties, C/C++, Code Generation,
switch “Runtime Library” setting from Multi-threaded (/MT) to Multi-threaded DLL (/MD),
and rebuild: the binary will become smaller.
The library includes RenderDoc GPU debugger integration.
When launched your program from RenderDoc, hold F12 key to capture the compute calls.
If you gonna debug HLSL shaders, use the debug build of the DLL, it
includes debug build of the shaders and you’ll get better UX in the
debugger.
The repository includes a lot of code which was only used
for development:
couple alternative model implementations, compatible FP64 versions of
some compute shaders, debug tracing and the tool to compare the traces,
etc.
That stuff is disabled by preprocessor macros or constexpr flags, I hope it’s fine to keep here.
I have a limited selection of GPUs in this house.
Specifically, I have optimized for nVidia 1080Ti, Radeon Vega 8 inside Ryzen 7 5700G, and Radeon Vega 7 inside Ryzen 5 5600U.
Here’s the summary.
The nVidia delivers relative speed 5.8 for the large model, 10.6 for the medium model.
The AMD Ryzen 5 5600U APU delivers relative speed about 2.2 for the
medium model. Not great, but still, much faster than realtime.
I have also tested on nVidia 1650: slower than 1080Ti but pretty good, much faster than realtime.
I have also tested on Intel HD Graphics 4000 inside Core i7-3612QM, the
relative speed was 0.14 for medium model, 0.44 for small model.
That’s much slower than realtime, but I was happy to find my software
works even on the integrated mobile GPU launched in 2012.
I’m not sure the performance is ideal on discrete AMD GPUs, or integrated Intel GPUs, have not specifically optimized for them.
Ideally, they might need slightly different builds of a couple of the most expensive compute shaders, mulMatTiled.hlsl and mulMatByRowTiled.hlsl
And maybe other adjustments, like the useReshapedMatMul() value in Whisper/D3D/device.h header file.
I don’t know how to measure that, but I have a feeling the bottleneck is memory, not compute.
Someone on Hacker News has tested on 3060Ti,
the version with GDDR6 memory.
Compared to 1080Ti, that GPU has 1.3x FP32 FLOPS, but 0.92x VRAM bandwidth.
The app was about 10% slower on the 3060Ti.
I have only spent a few days optimizing performance of these shaders.
It might be possible to do much better, here’s a few ideas.
-
Newer GPUs like Radeon Vega or nVidia 1650 have higher FP16 performance compared to FP32, yet my compute shaders are only using FP32 data type.
Half The Precision, Twice The Fun -
In the current version, FP16 tensors are using shader resource views to upcast loaded values, and unordered access views to downcast stored ones.
Might be a good idea to switch to byte address buffers, load/store complete 4-bytes values, and upcast / downcast in HLSL withf16tof32/f32tof16intrinsics. -
In the current version all shaders are compiled offline, and
Whisper.dllincludes DXBC byte codes.
The HLSL compilerD3DCompiler_47.dllis an OS component, and is pretty fast. For the expensive compute shaders, it’s probably a good idea to ship HLSL instead of DXBC, and compile on startup with environment-specific values for the macros. -
It might be a good idea to upgrade the whole thing from D3D11 to D3D12.
The newer API is harder to use, but includes potentially useful features not exposed to D3D11: wave intrinsics, and explicit FP16.
Automatic language detection is not implemented.
In the current version there’s high latency for realtime audio capture.
Specifically, depending on voice detection the figure is about 5-10 seconds.
At least in my tests, the model wasn’t happy when I supplied too short pieces of the audio.
I have increased the latency and called it a day, but ideally this needs a better fix for optimal UX.
From my perspective, this is an unpaid hobby project, which I completed over the 2022-23 winter holydays.
The code probably has bugs.
The software is provided “as is”, without warranty of any kind.
Thanks to Georgi Gerganov for whisper.cpp implementation,
and the models in GGML binary format.
I don’t program Python, and I don’t know anything about the ML ecosystem.
I wouldn’t even start this project without a good C++ reference implementation, to test my version against.
That whisper.cpp project has an example which uses
the same GGML implementation to run another OpenAI’s model, GPT-2.
It shouldn’t be hard to support that ML model with the compute shaders
and relevant infrastructure already implemented in this project.
If you find this useful, I’ll be very grateful if you consider a donation to “Come Back Alive” foundation.
from https://github.com/Const-me/Whisper
---------
[Blog] [Paper] [Model card] [Colab example]
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.

A Transformer sequence-to-sequence model is trained on various speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. These tasks are jointly represented as a sequence of tokens to be predicted by the decoder, allowing a single model to replace many stages of a traditional speech-processing pipeline. The multitask training format uses a set of special tokens that serve as task specifiers or classification targets.
We used Python 3.9.9 and PyTorch 1.10.1 to train and test our models, but the codebase is expected to be compatible with Python 3.8-3.11 and recent PyTorch versions. The codebase also depends on a few Python packages, most notably OpenAI's tiktoken for their fast tokenizer implementation. You can download and install (or update to) the latest release of Whisper with the following command:
pip install -U openai-whisper
Alternatively, the following command will pull and install the latest commit from this repository, along with its Python dependencies:
pip install git+https://github.com/openai/whisper.git
To update the package to the latest version of this repository, please run:
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
It also requires the command-line tool ffmpeg to be installed on your system, which is available from most package managers:
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpegYou may need rust installed as well, in case tiktoken does not provide a pre-built wheel for your platform. If you see installation errors during the pip install command above, please follow the Getting started page to install Rust development environment. Additionally, you may need to configure the PATH environment variable, e.g. export PATH="$HOME/.cargo/bin:$PATH". If the installation fails with No module named 'setuptools_rust', you need to install setuptools_rust, e.g. by running:
pip install setuptools-rustThere are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and inference speed relative to the large model; actual speed may vary depending on many factors including the available hardware.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
The .en models for English-only applications tend to perform better, especially for the tiny.en and base.en models. We observed that the difference becomes less significant for the small.en and medium.en models.
Whisper's performance varies widely depending on the language. The figure below shows a performance breakdown of large-v3 and large-v2 models by language, using WERs (word error rates) or CER (character error rates, shown in Italic)
evaluated on the Common Voice 15 and Fleurs datasets. Additional
WER/CER metrics corresponding to the other models and datasets can be
found in Appendix D.1, D.2, and D.4 of the paper, as well as the BLEU (Bilingual Evaluation Understudy) scores for translation in Appendix D.3.

The following command will transcribe speech in audio files, using the medium model:
whisper audio.flac audio.mp3 audio.wav --model medium
The default setting (which selects the small
model) works well for transcribing English. To transcribe an audio file
containing non-English speech, you can specify the language using the --language option:
whisper japanese.wav --language Japanese
Adding --task translate will translate the speech into English:
whisper japanese.wav --language Japanese --task translate
Run the following to view all available options:
whisper --help
See tokenizer.py for the list of all available languages.
from https://github.com/openai/whisper
-------------------------------------------------
Port of OpenAI's Whisper model in C/C++
Stable: v1.6.2 / Roadmap | F.A.Q.
High-performance inference of OpenAI's Whisper automatic speech recognition (ASR) model:
- Plain C/C++ implementation without dependencies
- Apple Silicon first-class citizen - optimized via ARM NEON, Accelerate framework, Metal and Core ML
- AVX intrinsics support for x86 architectures
- VSX intrinsics support for POWER architectures
- Mixed F16 / F32 precision
- 4-bit and 5-bit integer quantization support
- Zero memory allocations at runtime
- Support for CPU-only inference
- Efficient GPU support for NVIDIA
- Partial OpenCL GPU support via CLBlast
- OpenVINO Support
- C-style API
Supported platforms:
- Mac OS (Intel and Arm)
- iOS
- Android
- Java
- Linux / FreeBSD
- WebAssembly
- Windows (MSVC and MinGW]
- Raspberry Pi
- docker
The entire high-level implementation of the model is contained in whisper.h and whisper.cpp.
The rest of the code is part of the ggml machine learning library.
Having such a lightweight implementation of the model allows to easily integrate it in different platforms and applications. As an example, here is a video of running the model on an iPhone 13 device - fully offline, on-device: whisper.objc
whisper-iphone-13-mini-2.mp4
You can also easily make your own offline voice assistant application: command
command-0.mp4
On Apple Silicon, the inference runs fully on the GPU via Metal:
metal-base-1.mp4
Or you can even run it straight in the browser: talk.wasm
- The core tensor operations are implemented in C (ggml.h / ggml.c)
- The transformer model and the high-level C-style API are implemented in C++ (whisper.h / whisper.cpp)
- Sample usage is demonstrated in main.cpp
- Sample real-time audio transcription from the microphone is demonstrated in stream.cpp
- Various other examples are available in the examples folder
The tensor operators are optimized heavily for Apple silicon CPUs. Depending on the computation size, Arm Neon SIMD intrinsics or CBLAS Accelerate framework routines are used. The latter are especially effective for bigger sizes since the Accelerate framework utilizes the special-purpose AMX coprocessor available in modern Apple products.
First clone the repository:
git clone https://github.com/ggerganov/whisper.cpp.gitThen, download one of the Whisper models converted in ggml format. For example:
bash ./models/download-ggml-model.sh base.enNow build the main example and transcribe an audio file like this:
# build the main example
make
# transcribe an audio file
./main -f samples/jfk.wavFor a quick demo, simply run make base.en:
$ make base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
bash ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
The command downloads the base.en model converted to custom ggml format and runs the inference on all .wav samples in the folder samples.
For detailed usage instructions, run: ./main -h
Note that the main example currently runs only with 16-bit WAV files, so make sure to convert your input before running the tool.
For example, you can use ffmpeg like this:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavIf you want some extra audio samples to play with, simply run:
make samples
This will download a few more audio files from Wikipedia and convert them to 16-bit WAV format via ffmpeg.
You can download and run the other models as follows:
make tiny.en
make tiny
make base.en
make base
make small.en
make small
make medium.en
make medium
make large-v1
make large-v2
make large-v3
| Model | Disk | Mem |
|---|---|---|
| tiny | 75 MiB | ~273 MB |
| base | 142 MiB | ~388 MB |
| small | 466 MiB | ~852 MB |
| medium | 1.5 GiB | ~2.1 GB |
| large | 2.9 GiB | ~3.9 GB |
whisper.cpp supports integer quantization of the Whisper ggml models.
Quantized models require less memory and disk space and depending on the hardware can be processed more efficiently.
Here are the steps for creating and using a quantized model:
# quantize a model with Q5_0 method
make quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wavOn
Apple Silicon devices, the Encoder inference can be executed on the
Apple Neural Engine (ANE) via Core ML. This can result in significant
speed-up - more than x3 faster compared with CPU-only execution. Here
are the instructions for generating a Core ML model and using it with whisper.cpp:
-
Install Python dependencies needed for the creation of the Core ML model:
pip install ane_transformers pip install openai-whisper pip install coremltools
- To ensure
coremltoolsoperates correctly, please confirm that Xcode is installed and executexcode-select --installto install the command-line tools. - Python 3.10 is recommended.
- MacOS Sonoma (version 14) or newer is recommended, as older versions of MacOS might experience issues with transcription hallucination.
- [OPTIONAL] It is recommended to utilize a Python version management system, such as Miniconda for this step:
- To create an environment, use:
conda create -n py310-whisper python=3.10 -y - To activate the environment, use:
conda activate py310-whisper
- To create an environment, use:
Generate a Core ML model. For example, to generate a base.en model, use:
./models/generate-coreml-model.sh base.enThis will generate the folder models/ggml-base.en-encoder.mlmodelc
Build whisper.cpp with Core ML support:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config ReleaseRun the examples as usual. For example:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
The first run on a device is slow, since the ANE service compiles the Core ML model to some device-specific format. Next runs are faster.
For more information about the Core ML implementation please refer to PR #566.
On platforms that support OpenVINO, the Encoder inference can be executed on OpenVINO-supported devices including x86 CPUs and Intel GPUs (integrated & discrete).
This can result in significant speedup in encoder
performance. Here are the instructions for generating the OpenVINO model
and using it with whisper.cpp:
-
First, setup python virtual env. and install python dependencies. Python 3.10 is recommended.
Windows:
cd models python -m venv openvino_conv_env openvino_conv_env\Scripts\activate python -m pip install --upgrade pip pip install -r requirements-openvino.txt
Linux and macOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txtGenerate an OpenVINO encoder model. For example, to generate a base.en model, use:
python convert-whisper-to-openvino.py --model base.en
This will produce
ggml-base.en-encoder-openvino.xml/.bin IR model files. It's recommended
to relocate these to the same folder as ggml models, as that
is the default location that the OpenVINO extension will search at runtime.
Build whisper.cpp with OpenVINO support:
Download OpenVINO package from release page. The recommended version to use is 2023.0.0.
After downloading & extracting package onto your development system, set up required environment by sourcing setupvars script. For example:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (cmd):
C:\Path\To\w_openvino_toolkit_windows_2023.0.0.10926.b4452d56304_x86_64\setupvars.batAnd then build the project using cmake:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config ReleaseRun the examples as usual. For example:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
The first time run on an OpenVINO device is slow, since the OpenVINO framework will compile the IR (Intermediate Representation) model to a device-specific 'blob'. This device-specific blob will get cached for the next run.
For more information about the Core ML implementation please refer to PR #1037.
With NVIDIA cards the processing of the models is done efficiently on the GPU via cuBLAS and custom CUDA kernels.
First, make sure you have installed cuda: https://developer.nvidia.com/cuda-downloads
Now build whisper.cpp with CUDA support:
make clean
WHISPER_CUDA=1 make -j
For cards and integrated GPUs that support OpenCL, the Encoder processing can be largely offloaded to the GPU through CLBlast. This is especially useful for users with AMD APUs or low end devices for up to ~2x speedup.
First, make sure you have installed CLBlast for your OS or Distribution: https://github.com/CNugteren/CLBlast
Now build whisper.cpp with CLBlast support:
Makefile:
cd whisper.cpp
make clean
WHISPER_CLBLAST=1 make -j
CMake:
cd whisper.cpp
cmake -B build -DWHISPER_CLBLAST=ON
cmake --build build -j --config Release
Run all the examples as usual.
Encoder processing can be accelerated on the CPU via OpenBLAS.
First, make sure you have installed openblas: https://www.openblas.net/
Now build whisper.cpp with OpenBLAS support:
make clean
WHISPER_OPENBLAS=1 make -j
Encoder processing can be accelerated on the CPU via the BLAS compatible interface of Intel's Math Kernel Library. First, make sure you have installed Intel's MKL runtime and development packages: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-download.html
Now build whisper.cpp with Intel MKL BLAS support:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
- Docker must be installed and running on your system.
- Create a folder to store big models & intermediate files (ex. /whisper/models)
We have two Docker images available for this project:
ghcr.io/ggerganov/whisper.cpp:main: This image includes the main executable file as well ascurlandffmpeg. (platforms:linux/amd64,linux/arm64)ghcr.io/ggerganov/whisper.cpp:main-cuda: Same asmainbut compiled with CUDA support. (platforms:linux/amd64)
# download model and persist it in a local folder docker run -it --rm \ -v path/to/models:/models \ whisper.cpp:main "./models/download-ggml-model.sh base /models" # transcribe an audio file docker run -it --rm \ -v path/to/models:/models \ -v path/to/audios:/audios \ whisper.cpp:main "./main -m /models/ggml-base.bin -f /audios/jfk.wav" # transcribe an audio file in samples folder docker run -it --rm \ -v path/to/models:/models \ whisper.cpp:main "./main -m /models/ggml-base.bin -f ./samples/jfk.wav"
You can install pre-built binaries for whisper.cpp or build it from source using Conan. Use the following command:
conan install --requires="whisper-cpp/[*]" --build=missing
For detailed instructions on how to use Conan, please refer to the Conan documentation.
- Inference only
Here is another example of transcribing a 3:24 min speech
in about half a minute on a MacBook M1 Pro, using medium.en model:
Expand to see the result
This is a naive example of performing real-time inference on audio from your microphone. The stream tool samples the audio every half a second and runs the transcription continuously. More info is available in issue #10.
make stream
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000rt_esl_csgo_2.mp4
Adding the --print-colors argument will print the transcribed text using an experimental color coding strategy
to highlight words with high or low confidence:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors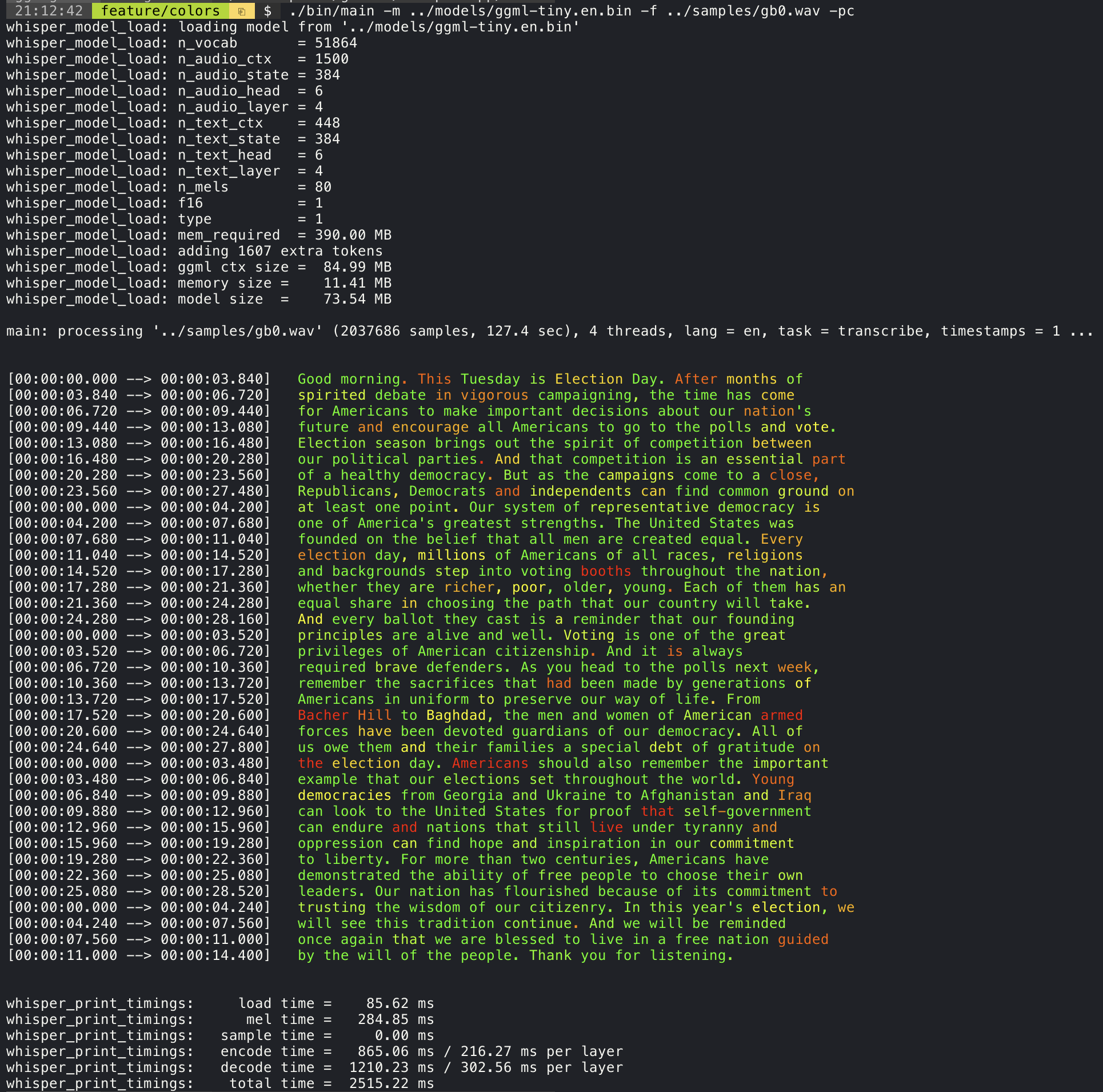
For example, to limit the line length to a maximum of 16 characters, simply add -ml 16:
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
The --max-len argument can be used to obtain word-level timestamps. Simply use -ml 1:
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
More information about this approach is available here: #1058
Sample usage:
# download a tinydiarize compatible model
./models/download-ggml-model.sh small.en-tdrz
# run as usual, adding the "-tdrz" command-line argument
./main -f ./samples/a13.wav -m ./models/ggml-small.en-tdrz.bin -tdrz
...
main: processing './samples/a13.wav' (480000 samples, 30.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, tdrz = 1, timestamps = 1 ...
...
[00:00:00.000 --> 00:00:03.800] Okay Houston, we've had a problem here. [SPEAKER_TURN]
[00:00:03.800 --> 00:00:06.200] This is Houston. Say again please. [SPEAKER_TURN]
[00:00:06.200 --> 00:00:08.260] Uh Houston we've had a problem.
[00:00:08.260 --> 00:00:11.320] We've had a main beam up on a volt. [SPEAKER_TURN]
[00:00:11.320 --> 00:00:13.820] Roger main beam interval. [SPEAKER_TURN]
[00:00:13.820 --> 00:00:15.100] Uh uh [SPEAKER_TURN]
[00:00:15.100 --> 00:00:18.020] So okay stand, by thirteen we're looking at it. [SPEAKER_TURN]
[00:00:18.020 --> 00:00:25.740] Okay uh right now uh Houston the uh voltage is uh is looking good um.
[00:00:27.620 --> 00:00:29.940] And we had a a pretty large bank or so.The main example provides support for output of karaoke-style movies, where the
currently pronounced word is highlighted. Use the -wts argument and run the generated bash script.
This requires to have ffmpeg installed.
Here are a few "typical" examples:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4jfk.wav.mp4
./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4mm0.wav.mp4
./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4gb0.wav.mp4
Use the scripts/bench-wts.sh script to generate a video in the following format:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4jfk.wav.all.mp4
In order to have an objective comparison of the performance of the inference across different system configurations, use the bench tool. The tool simply runs the Encoder part of the model and prints how much time it took to execute it. The results are summarized in the following Github issue:
Additionally a script to run whisper.cpp with different models and audio files is provided bench.py.
You can run it with the following command, by default it will run against any standard model in the models folder.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2It is written in python with the intention of being easy to modify and extend for your benchmarking use case.
It outputs a csv file with the results of the benchmarking.
The original models are converted to a custom binary format. This allows to pack everything needed into a single file:
- model parameters
- mel filters
- vocabulary
- weights
You can download the converted models using the models/download-ggml-model.sh script or manually from here:
For more details, see the conversion script models/convert-pt-to-ggml.py or models/README.md.
- Rust: tazz4843/whisper-rs | #310
- JavaScript: bindings/javascript | #309
- React Native (iOS / Android): whisper.rn
- Go: bindings/go | #312
- Java:
- Ruby: bindings/ruby | #507
- Objective-C / Swift: ggerganov/whisper.spm | #313
- .NET: | #422
- Python: | #9
- stlukey/whispercpp.py (Cython)
- AIWintermuteAI/whispercpp (Updated fork of aarnphm/whispercpp)
- aarnphm/whispercpp (Pybind11)
- R: bnosac/audio.whisper
- Unity: macoron/whisper.unity
There are various examples of using the library for different projects in the examples folder. Some of the examples are even ported to run in the browser using WebAssembly. Check them out!
| Example | Web | Description |
|---|---|---|
| main | whisper.wasm | Tool for translating and transcribing audio using Whisper |
| bench | bench.wasm | Benchmark the performance of Whisper on your machine |
| stream | stream.wasm | Real-time transcription of raw microphone capture |
| command | command.wasm | Basic voice assistant example for receiving voice commands from the mic |
| wchess | wchess.wasm | Voice-controlled chess |
| talk | talk.wasm | Talk with a GPT-2 bot |
| talk-llama | Talk with a LLaMA bot | |
| whisper.objc | iOS mobile application using whisper.cpp | |
| whisper.swiftui | SwiftUI iOS / macOS application using whisper.cpp | |
| whisper.android | Android mobile application using whisper.cpp | |
| whisper.nvim | Speech-to-text plugin for Neovim | |
| generate-karaoke.sh | Helper script to easily generate a karaoke video of raw audio capture | |
| livestream.sh | Livestream audio transcription | |
| yt-wsp.sh | Download + transcribe and/or translate any VOD (original) | |
| server | HTTP transcription server with OAI-like API |
whisper.cpp. If you have a question, make sure to check the
Frequently asked questions (#126) discussion.from https://github.com/ggerganov/whisper.cpp
------------------------------------------------
A quick experiment to achieve almost realtime transcription using Whisper.
This is a quick experiment to achieve almost realtime transcription using Whisper.
Install the requirements:
pip install -r requirements.txt
Run the script:
python openai-whisper-realtime.py
Dependencies:
- Python > 3.7
- whisper
- sounddevice
- numpy
- asyncio
A very fast CPU or GPU is recommended.
The systems default audio input is captured with python, split into small chunks and is then fed to OpenAI's original transcription function. It tries (currently rather poorly) to detect word breaks and doesn't split the audio buffer in those cases. With how the model is designed, it doesn't make the most sense to do this, but i found it would be worth trying. It works acceptably well.
from https://github.com/tobiashuttinger/openai-whisper-realtime
No comments:
Post a Comment