GFW 的原理
要与 GFW 对抗不能仅仅停留在什么不能访问了,什么可以访问之类的表面现象上。知道 youtube 不能访问了,对于翻墙来说并无帮助。但是知道 GFW 是如何让我们不能访问 youtube 的,则对下一步的翻墙方案的选择和实施具有重大意义。所以在讨论如何翻之前,先要深入原理了解 GFW 是如何封的。
总的来说,GFW 是一个分布式的入侵检测系统,并不是一个严格意义上的防火墙。不是说每个出入国境的 IP 包都需要先经过 GFW 的首可。做为一个入侵检测系统,GFW 把你每一次访问 facebook 都看做一次入侵,然后在检测到入侵之后采取应对措施,也就是常见的连接重置。
检测有两种方式。一种是人工检测,一种是机器检测。你去国新办网站举报,就是参与了人工检测。在人工检测到不和谐的网站之后,就会采取一些应对方式来防止国内的网民访问该网站。对于这类的封锁,规避检测就不是技术问题了,只能从 GFW 采取的应对方式上采取反制措施。另外一类检测是机器检测,其检测过程又可以再进一步细分:
重建是指 GFW 从网络上监听过往的 IP 包,然后分析其中的 TCP 协议,最后重建出一个完整的字节流。分析是在这个重建的字节流上分析具体的应用协议,比如 HTTP 协议。然后在应用协议中查找是不是有不和谐的内容,然后决定采用何种应对方式。
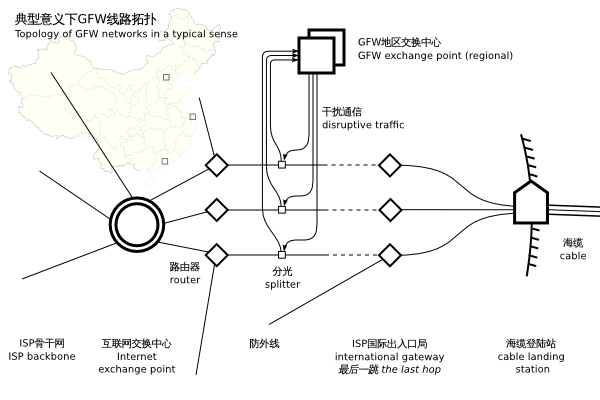
所以,GFW 机器检测的第一步就是重建出一个字节流。那么 GFW 是如何拿到原始的 IP 包的呢?真正的 GFW 部署方式,外人根本无从得知。据猜测,GFW 是部署在国家的出口路由器的旁路上,用 “分光” 的方式把 IP 包复制一份到另外一根光纤上,从而拿到所有进出国境的 IP 包。下图引在 gfwrev.blogspot.com:
但是 Google 在北京有自己的机房。所以聪明的网友就使用 Google 的北京机房提供的 GAE 服务,用 Goagent 软件达到高速翻墙的目的。但是有网友证实 https://twitter.com/chengr28/status/260970749190365184 ,
即便是北京的机房也会被骨干网丢包。事实上
Google 在北京的谷翔机房有一个独立的 AS(BGP 的概念)。这个 AS 与谷歌总部有一条 IPV6 的直连线路,所以通过这个机房可以用
IPV6 不受墙的限制出去。但是这个 AS 无论是连接国内还是国外都是要经过 GFW 的。所以机房在北京也不能保证国内访问不被墙。GFW
通过配置骨干网的 BGP 路由规则,是可以让国内的机房也经过它的。另外一个例子是当我们访问被封的网站触发连接重置的时候,往往收到两个 RST
包,但是 TTL 不同。还有一个例子是对于被封的 IP,访问的 IP 包还没有到达国际出口就已经被丢弃。所以 GFW
应该在其他地方也部署有设备,据推测是在省级骨干路由的位置。
对于 GFW 到底在哪这个话题,最近又有国外友人表达了兴趣 https://github.com/mothran/mongol。 笔者在前人的基础上写了一个更完备的探测工具 https://github.com/fqrouter/qiang 。其原理是基于一个 IP 协议的特性叫 TTL。TTL 是 Time to Live 的简写。IP 包在没经过一次路由的时候,路由器都会把 IP 包的 TTL 减去 1。如果 TTL 到零了,路由器就不会再把 IP 包发给下一级路由。然后我们知道 GFW 会在监听到不和谐的 IP 包之后发回 RST 包来重置 TCP 连接。那么通过设置不同的 TTL 就可以知道从你的电脑,到 GFW 之间经过了几个路由器。比如说 TTL 设置成 9 不触发 RST,但是 10 就触发 RST,那么到 GFW 就是经过了 10 个路由器。另外一个 IP 协议的特性是当 TTL 耗尽的时候,路由器应该发回一个 TTL EXCEEDED 的 ICMP 包,并把自己的 IP 地址设置成 SRC(来源)。结合这两点,就可以探测出 IP 包是到了 IP 地址为什么的路由器之后才被 GFW 检测到。有了 IP 地址之后,再结合 IP 地址地理位置的数据库就可以知道其地理位置。据说,得出的位置大概是这样的:
但是这里检测出来的 IP 到底是 GFW 的还是骨干路由器的?更有可能的是骨干路由器的 IP。GFW 做为一个设备用 “分光” 的方式挂在主干路由器旁边做入侵检测。无论如何,GFW 通过某种神奇的方式,可以拿到你和国外服务器之间来往的所有的 IP 包,这点是肯定的。更严谨的理论研究有:Internet Censorship in China: Where Does the Filtering Occur?
GFW 在拥有了这些 IP 包之后,要做一个艰难的决定,那就是到底要不要让你和服务器之间的通信继续下去。GFW 不能太过于激进,毕竟全国性的不能访问国外的网站是违反 GFW 自身存在价值的。GFW 就需要在理解了 IP 包背后代表的含义之后,再来决定是不是可以安全的阻断你和国外服务器之间的连接。这种理解就要建立了前面说的 “重建” 这一步的基础上。大概用图表达一下重建是在怎么一回事:

重建需要做的事情就是把 IP 包 1 中的 GET /inde 和 IP 包 2 中的 x.html H 和 IP 包 3 中的 TTP/1.1 拼到一起变成 GET /index.html HTTP/1.1。拼出来的数据可能是纯文本的,也可能是二进制加密的协议内容。具体是什么是你和服务器之间约定好的。GFW 做为窃听者需要猜测才知道你们俩之间的交谈内容。对于 HTTP 协议就非常容易猜测了,因为 HTTP 的协议是标准化的,而且是未加密的。所以 GFW 可以在重建之后很容易的知道,你使用了 HTTP 协议,访问的是什么网站。
重建这样的字节流有一个难点是如何处理巨大的流量?这个问题在这篇博客 http://gfwrev.blogspot.tw/2010/02/gfw.html 中已经讲得很明白了。其原理与网站的负载均衡器一样。对于给定的来源和目标,使用一个 HASH 算法取得一个节点值,然后把所有符合这个来源和目标的流量都往这个节点发。所以在一个节点上就可以重建一个 TCP 会话的单向字节流。
最后为了讨论完整,再提两点。虽然 GFW 的重建发生在旁路上是基于分光来实现的,但并不代表整个 GFW 的所有设备都在旁路。后面会提到有一些 GFW 应对形式必须是把一些 GFW 的设备部署在了主干路由上,比如对 Google 的 HTTPS 的间歇性丢包,也就是 GFW 是要参与部分 IP 的路由工作的。另外一点是,重建是单向的 TCP 流,也就是 GFW 根本不在乎双向的对话内容,它只根据监听到的一个方向的内容然后做判断。但是监听本身是双向的,也就是无论是从国内发到国外,还是从国外发到国内,都会被重建然后加以分析。所以一个 TCP 连接对于 GFW 来说会被重建成两个字节流。具体的证据会在后面谈如何直穿 GFW 中详细讲解。
分析
分析是 GFW 在重建出字节流之后要做的第二步。对于重建来说,GFW 主要处理 IP 协议,以及上一层的 TCP 和 UDP 协议就可以了。但是对于分析来说,GFW 就需要理解各种各样的应用层的稀奇古怪的协议了。甚至,我们也可以自己发明新的协议。
总的来说,GFW 做协议分析有两个相似,但是不同的目的。第一个目的是防止不和谐内容的传播,比如说使用 Google 搜索了 “不该” 搜索的关键字。第二个目的是防止使用翻墙工具绕过 GFW 的审查。下面列举一些已知的 GFW 能够处理的协议。
对于 GFW 具体是怎么达到目的一,也就是防止不和谐内容传播的就牵涉到对 HTTP 协议和 DNS 协议等几个协议的明文审查。大体的做法是这样的。

像 HTTP 这样的协议会有非常明显的特征供检测,所以第一步就没什么好说的了。当 GFW 发现了包是 HTTP 的包之后就会按照 HTTP 的协议规则拆包。这个拆包过程是 GFW 按照它对于协议的理解来做的。比如说,从 HTTP 的 GET 请求中取得请求的 URL。然后 GFW 拿到这个请求的 URL 去与关键字做匹配,比如查找 Twitter 是否在请求的 URL 中。为什么有拆包这个过程?首先,拆包之后可以更精确的打击,防止误杀。另外可能预先做拆包,比全文匹配更节省资源。其次,xiaoxia 和 liruqi 同学的 jjproxy 的核心就是基于 GFW 的一个 HTTP 拆包的漏洞,当然这个 bug 已经被修复了。其原理就是 GFW 在拆解 HTTP 包的时候没有处理有多出来的 \r\n 这样的情况,但是你访问的 google.com 却可以正确处理额外的 \r\n 的情况。从这个例子中可以证明,GFW 还是先去理解协议,然后才做关键字匹配的。关键字匹配应该就是使用了一些高效的正则表达式算法,没有什么可以讨论的。
HTTP 代理和 SOCKS 代理,这两种明文的代理都可以被 GFW 识别。之前笔者认为 GFW 可以在识别到 HTTP 代理和 SOCKS 代理之后,再拆解其内部的 HTTP 协议的正文。也就是做两次拆包。但是分析发现,HTTP 代理的关键字列表和 HTTP 的关键字列表是不一样的,所以笔者现在认为 HTTP 代理协议和 SOCKS 代理协议是当作单独的协议来处理的,并不是拆出载荷的 HTTP 请求再进行分析的。
目前已知的 GFW 会做的协议分析如下:
DNS 查询
GFW 可以分析 53 端口的 UDP 协议的 DNS 查询。如果查询的域名匹配关键字则会被 DNS 劫持。可以肯定的是,这个匹配过程使用的是类似正则的机制,而不仅仅是一个黑名单,因为子域名实在太多了。证据是:2012 年 11 月 9 日下午 3 点半开始,防火长城对 Google 的泛域名 .google.com 进行了大面积的污染,所有以 .google.com 结尾的域名均遭到污染而解析错误不能正常访问,其中甚至包括不存在的域名(来源 http://zh.wikipedia.org/wiki/%E5%9F%9F%E5%90%8D%E5%8A%AB%E6%8C%81)
目前为止 53 端口之外的查询也没有被劫持。但是 TCP 的 DNS 查询已经可以被 TCP RST 切断了,表明了 GFW 具有这样的能力,只是不屑于大规模部署。而且 TCP 查询的关键字比 UDP 劫持的域名要少的多。目前只有 dl.dropbox.com 会触发 TCP RST。相关的研究论文有:
Hold-On: Protecting Against On-Path DNS Poisoning
The Great DNS Wall of China
HTTP 请求
GFW 可以识别出 HTTP 协议,并且检查 GET 的 URL 与 HOST。如果匹配了关键字则会触发 TCP RST 阻断。前面提到了 jjproxy 使用的构造特殊的 HTTP GET 请求欺骗 GFW 的做法已经失效,现在 GFW 只要看到 \r\n 就直接 TCP RST 阻断了(来源 https://plus.google.com/u/0/108661470402896863593/posts/6U6Q492M3yY)。相关的研究论文有:
The Great Firewall Revealed
Ignoring the Great Firewall of China
ConceptDoppler: A Weather Tracker for Internet Censorship
对翻墙流量的分析识别
GFW 的第二个目的是封杀翻墙软件。为了达到这个目的 GFW 采取的手段更加暴力。原因简单,对于 HTTP 协议的封杀如果做不好会影响互联网的正常运作,GFW 与互联网是共生的关系,它不会做威胁自己存在的事情。但是对于 TOR 这样的几乎纯粹是为翻墙而存在的协议,只要检测出来就是格杀勿论的了。GFW 具体是如何封杀各种翻墙协议的,我也不是很清楚,事态仍然在不断更新中。但是举两个例子来证明 GFW 的高超技术。
第一个例子是 GFW 对 TOR 的自动封杀,体现了 GFW 尽最大努力去理解协议本身。根据这篇博客 https://blog.torproject.org/blog/knock-knock-knockin-bridges-doors 。 使用中国的 IP 去连接一个美国的 TOR 网桥,会被 GFW 发现。然后 GFW 回头(15 分钟之后)会亲自假装成客户端,用 TOR 的协议去连接那个网桥。如果确认是 TOR 的网桥,则会封当时的那个端口。换了端口之后,可以用一段时间,然后又会被封。这表现出了 GFW 对于协议的高超检测能力,可以从国际出口的流量中敏锐地发现你连接的 TOR 网桥。据 TOR 的同志说是因为 TOR 协议中的握手过程具有太明显的特征了。另外一点就表现了 GFW 的不辞辛劳,居然会自己伪装成客户端过去连连看。
第二个例子表现了 GFW 根本不在乎加密的流量中的具体内容是不是有敏感词。只要疑似翻墙,特别是提供商业服务给多个翻墙,就会被封杀。根据这个帖子 http://www.v2ex.com/t/55531 , 使用的 ShadowSocks 协议。预先部署密钥,没有明显的握手过程仍然被封。据说是 GFW 已经升级为能够机器识别出哪些加密的流量是疑似翻墙服务的。
关于 GFW 是如何识别与封锁翻墙服务器的,最近写了一篇文章提出我的猜想,大家可以去看看:http://fqrouter.tumblr.com/post/45969604783/gfw。
最近发现 GFW 对 OpenVPN 和 SSL 证书已经可以做到准实时的封 IP(端口)。原理应该是离线做的深包分析,然后提取出可疑的 IP 列表,经过人工确认之后封 IP。因为 OpenVPN 有显著的协议的特征,而且基本不用于商业场景所以很容易确认是翻墙服务。但是 SSL 也就是 HTTPS 用的加密协议也能基于 “证书” 做过滤不得不令人感到敬畏了。Shadowsocks 的作者 Clowwindy 为此专门撰文 “为什么不应该用 SSL 翻墙 “: https://gist.github.com/clowwindy/5947691。
总结起来就是,GFW 已经基本上完成了目的一的所有工作。明文的协议从 HTTP 到 SMTP 都可以分析然后关键字检测,甚至电驴这样不是那么大众的协议 GFW 都去搞了。从原理上来说也没有什么好研究的,就是明文,拆包,关键字。GFW 显然近期的工作重心在分析网络流量上,从中识别出哪些是翻墙的流量。这方面的研究还比较少,而且一个显著的特征是自己用没关系,大规模部署就容易出问题。我目前没有在 GFW 是如何封翻墙工具上有太多研究,只能是道听途说了。
措施
封 IP
一般常见于人工检测之后的应对。还没有听说有什么方式可以直接使得 GFW 的机器检测直接封 IP。一般常见的现象是 GFW 机器检测,然后用 TCP RST 重置来应对。过了一段时间才会被封 IP,而且没有明显的时间规律。所以我的推测是,全局性的封 IP 应该是一种需要人工介入的。注意我强调了全局性的封 IP,与之相对的是部分封 IP,比如只对你访问那个 IP 封个 3 分钟,但是别人还是可以访问这样的。这是一种完全不同的封锁方式,虽然现象差不多,都是 ping 也 ping 不通。要观摩的话 ping twitter.com 就可以了,都封了好久了。
其实现方式是把无效的路由黑洞加入到主干路由器的路由表中,然后让这些主干网上的路由器去帮 GFW 把到指定 IP 的包给丢弃掉。路由器的路由表是动态更新的,使用的协议是 BGP 协议。GFW 只需要维护一个被封的 IP 列表,然后用 BGP 协议广播出去就好了。然后国内主干网上的路由器都好像变成了 GFW 的一份子那样,成为了帮凶。
如果我们使用 traceroute 去检查这种被全局封锁的 IP 就可以发现,IP 包还没有到 GFW 所在的国际出口就已经被电信或者联通的路由器给丢弃了。这就是 BGP 广播的作用了。
DNS 劫持
这也是一种常见的人工检测之后的应对。人工发现一个不和谐网站,然后就把这个网站的域名给加到劫持列表中。其原理是基于 DNS 与 IP 协议的弱点,DNS 与 IP 这两个协议都不验证服务器的权威性,而且 DNS 客户端会盲目地相信第一个收到的答案。所以你去查询 facebook.com 的话,GFW 只要在正确的答案被返回之前抢答了,然后伪装成你查询的 DNS 服务器向你发错误的答案就可以了。
TCP RST 阻断
TCP 协议规定,只要看到 RST 包,连接立马被中断。从浏览器里来看就是连接已经被重置。我想对于这个错误大家都不陌生。据我个人观感,这种封锁方式是 GFW 目前的主要应对手段。大部分的 RST 是条件触发的,比如 URL 中包含某些关键字。目前享受这种待遇的网站就多得去了,著名的有 facebook。还有一些网站,会被无条件 RST。也就是针对特定的 IP 和端口,无论包的内容就会触发 RST。比较著名的例子是 https 的 wikipedia。GFW 在 TCP 层的应对是利用了 IPv4 协议的弱点,也就是只要你在网络上,就假装成任何人发包。所以 GFW 可以很轻易地让你相信 RST 确实是 Google 发的,而让 Google 相信 RST 是你发的。
封端口
GFW 除了自身主体是挂在骨干路由器旁路上的入侵检测设备,利用分光技术从这个骨干路由器抓包下来做入侵检测 (所谓 IDS),除此之外这个路由器还会被用来封端口 (所谓 IPS)。GFW 在检测到入侵之后可以不仅仅可以用 TCP RST 阻断当前这个连接,而且利用骨干路由器还可以对指定的 IP 或者端口进行从封端口到封 IP,设置选择性丢包的各种封禁措施。可以理解为骨干路由器上具有了类似 “iptables” 的能力(网络层和传输层的实时拆包,匹配规则的能力)。这个 iptables 的能力在 CISCO 路由器上叫做 ACL Based Forwarding (ABF)。而且规则的部署是全国同步的,一台路由器封了你的端口,全国的挂了 GFW 的骨干路由器都会封。一般这种封端口都是针对翻墙服务器的,如果检测到服务器是用 SSH 或者 VPN 等方式提供翻墙服务。GFW 会在全国的出口骨干路由上部署这样的一条 ACL 规则,来封你这个服务器 + 端口的下行数据包。也就是如果包是从国外发向国内的,而且 src(源 ip)是被封的服务器 ip,sport(源端口)是被封的端口,那么这个包就会被过滤掉。这样部署的规则的特点是,上行的数据包是可以被服务器收到的,而下行的数据包会被过滤掉。
如果被封端口之后服务器采取更换端口的应对措施,很快会再次被封。而且多次尝试之后会被封 IP。初步推断是,封端口不是 GFW 的自动应对行为,而是采取黑名单加人工过滤地方式实现的。一个推断的理由就是网友报道,封端口都是发生在白天工作时间。
反向墙
大部分机场使用的国内中转服务器,GFW 检测到了十分异常的境外大流量,就会在特殊时期,如两会和国庆期间,将该服务器反向墙。具体表现为国外的服务器无法访问该被反向墙了的 IP。测该国内服务器的 ping 就是国外一片红,国内一片绿。解决方法不多,要么更换 IP,或者等敏感时期过去,自动恢复。
翻墙原理
前面从原理上讲解了 GFW 的运作原理。翻墙的原理与之相对应,分为两大类。第一类是大家普遍的使用的绕道的方式。IP 包经由第三方中转已加密的形式通过 GFW 的检查。这样的一种做法更像 “翻” 墙,是从墙外绕过去的。第二类是找出 GFW 检测过程的中一些 BUG,利用这些 BUG 让 GFW 无法知道准确的会话内容从而放行。
基于绕道法的翻墙方式无论是 VPN 还是 SOCKS 代理,原理都是类似的。都是以国外有一个代理服务器为前提,然后你与代理服务器通信,代理服务器再与目标服务器通信。
除了基本的 http L2TP sock5 等代理协议外,现在主流的翻墙访问境外网站的协议均为 ss,vmess,ssr,vless,trojan,kcp,hysteria 等。
协议(直连)
Shadowsocks
shadowsocks(ss)是一种基于 sock5 代理方式的加密传输协议。初代版本发布于 2012 年 4 月 20 日。Shadowsocks 使用自行设计的协定进行加密通信。加密演算法有 AES、Blowfish、ChaCha20、RC4 等,除建立 TCP 连接外无需握手,每次请求只转发一个连接,无需保持一直连线的状态,因此在流动装置上相对较为省电。

现如今的该协议的现状是被 GFW 检测并且可以接着封禁,包括但不限于阻断、封端口、封 IP 等。所以如果是直连 SS 的话,基本就是头铁硬刚了。
因为其低延迟的原因,仍是众多主流机场的选择。(机场都使用中转,并非 ss 直连,所以封禁对其并无影响)
支持软件
其附带的衍生软件,shadowsocks 和 shadowsocksr 已基本被淘汰。
clash/v2rayn/v2rayng/shadowrocket/quantumultx 等主流软件都兼容该协议
shadowsocksr
可以说 shadowsocksr(ssr / 酸酸乳)是 ss 的升级版。SSR 是网名为 breakwa11 的用户发起的 Shadowsocks 分支,在 Shadowsocks 的基础上增加了一些资料混淆方式,称修复了部分安全问题并可以提高 QoS 优先级。后来贡献者 Librehat 也为 Shadowsocks 补上了一些此类特性,甚至增加了类似 Tor 的可插拔传输层功能。
支持软件
其附带的衍生软件,shadowsocks 和 shadowsocksr 已基本被淘汰。
clash/v2rayn/v2rayng/shadowrocket/quantumultx 等主流软件都兼容该协议
VMess
VMess 是一个基于 TCP 的加密传输协议,所有数据使用 TCP 传输。它分为入站和出站两部分,通常作为 V2Ray 客户端和服务器之间的桥梁。基于 v2ray 内核。
VMess 依赖于系统时间,请确保使用 V2Ray 的系统 UTC 时间误差在 90 秒之内,时区无关。在 Linux 系统中可以安装 ntp 服务来自动同步系统时间。
因为其加密性,现在也是主流加密协议之一。搭建直连节点时主要使用 vmess + websocket + tls + nginx伪装 协议,这样理论上是最不容易被墙的协议之一。
vmess 协议的主要特点就是严加密,但是随之而来的问题也很明显,握手次数多了,相较于 ss/ssr,延迟自然也是提高了很多。但是其速度方面是比 ss/ssr 要快的(经测试,同服务器 ss 和 vmess+ws 的速度比较得出,YouTube 也有测速比较视频)。
支持软件
其附带的衍生软件,v2rayn/v2rayng 依旧十分常用,现均默认使用 xray-core。
clash/v2rayn/v2rayng/shadowrocket/quantumultx 等主流软件都兼容该协议
Vless
vless 也可以说是 vmess 的升级版,基于 xray 内核。VLESS 是一个无状态的轻量传输协议,它分为入站和出站两部分,可以作为 V2Ray 客户端和服务器之间的桥梁。与 VMess 不同,VLESS 不依赖于系统时间,认证方式同样为 UUID,但不需要 alterId。
相较于 vmess,vless 的协议速度更快,延迟方面相差不多。
支持软件
vless 需要使用 xray-core 才能运行。
v2rayn/v2rayng/shadowrocket/quantumultx 等主流软件兼容该协议。clash 很遗憾并不支持。
trojan
与 Shadowsocks 相反,Trojan 不使用自定义的加密协议来隐藏自身。相反,使用特征明显的 TLS 协议 (TLS/SSL),使得流量看起来与正常的 HTTPS 网站相同。TLS 是一个成熟的加密体系,HTTPS 即使用 TLS 承载 HTTP 流量。使用正确配置的加密 TLS 隧道,可以保证传输的
Trojan 不同于 vmess,可以自定是否加上 tls 加密,trojan 是强制使用 tls 加密的。也就是说 trojan 必须需要域名才能搭建。
速度方面,trojan 和 vmess 相差不多。但是 trojan 最大的优点就是对于服务器端的占用很小,十分的轻量,即使低配服务器也能跑的很爽。
支持软件
clash/v2rayn/v2rayng/shadowrocket/quantumultx 等主流软件兼容该协议。
Hysteria
Hysteria 是一个功能丰富的,专为恶劣网络环境进行优化的网络工具(双边加速),比如卫星网络、拥挤的公共 Wi-Fi、在中国连接国外服务器等。 基于修改版的 QUIC 协议。
Hysteria 这是一款由 go 编写的非常优秀的 “轻量” 代理程序,它很好的解决了在搭建富强魔法服务器时最大的痛点 —— 线路拉跨。
在魔法咏唱时最难的不是搭建维护,而是在晚高峰时期的交付质量。当三大运营商晚高变成了:奠信、连不通、移不动时,你我都有感触。 虽然是走的 udp 但是提供 obfs,暂时不会被运营商针对性的 QoS (不开 obfs 也不会被 QoS)。
这是最近十分火的新协议。主要优点就是即使线路不佳,也不用中转或者 CF CDN,使用 hysteria 即可拯救。目前来看对于非国内优化线路还是十分友好的。
支持软件
v2rayn/shadowrocket 最新版已支持 hysteria
中转
说完了直连,那么再说说中转吧。
中转主要是分为三种,一种就是国内大带宽服务器直接中转。主要优点就是相较于直连,可以更好的符合国内复杂的运营商网络情况。确定也很明显,对于国外被墙的 IP 束手无策,也怕反向墙,而且并非一个国内服务器就能拉得动所有国外服务器。有的国外服务器联通友好的,用电信的服务器去拉,很有可能就会很拉跨。
第二种就是隧道中转,这也是近几年才有的新的中转方式。隧道中转即一个国内服务器一个国外服务器。因为国外服务器一般有 BGP session,对于复杂的网络情况都可以比较好的应对,隧道的国外端到你的节点服务器普遍线路会比较友好。而隧道国外端到国内端又会经过加密,这样虽然也会略微增加延迟,但是可以无视国外机器被墙的情况。但是国内服务器也会怕反向墙。使用隧道的话,基本一个隧道节点就能拉得动大部分的国外服务器。
第三种就是专线中转,也是最昂贵的。一条 G 口专线一个月基本 2.5w+ rmb,不是有钱的机场用不起的。其实专线和隧道比较类似,同样也是分国内端和国外端。专线分为 IEPL 和 IPLC,对于这俩的定义可以参考 https://www.cheshirex.com/2005.html。 专线最大的优点,就是延迟低,稳定,不过墙,所以也不用担心节点服务器被墙或者国内反向墙的问题,可以说除了机房的日常维护等特殊情况下,专线是基本永不掉线的。也正是因为这点备受青睐。
自建
很多小白想要自己搭建节点,但是发现搭建完了以后不是断流就是接着被墙了。在这里统一推荐,使用 vmess+ws+tls+nginx伪装 或者 vless+ws+tls+nginx伪装 的搭建方式是比较合理的(没有中转的直连情况下)。对于动态 IP 的服务器来说,使用 vmess+ws 即可,保证速度的同时也不会被阻断。对于辣鸡线路的小鸡,可以使用 hysteria。
小结
和 GFW 的斗智斗勇还在继续~~~
转载编辑补充自 http://www.oneyearago.me
No comments:
Post a Comment